/1 前言/
selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,是爬复杂动态网页的必备工具。支持的浏览器包括IE,Mozilla Firefox,Safari,Google Chrome,Opera等。
这里分两个场景,给大家介绍Selenium爬动态网页小技巧。
/2 场景一:替换日期控件值/
以12306网站为例,如下图所示,按照正常的方法,我们首先要定位到时间元素,然后调用selenium的click()方法进行点击。

这种操作也是可行的。但是,过了一段时间,我们再次运行自动化代码的时候,就会发现功能运行不正常。因为日期更改后,日历控件布局发生了变化,而且操作起来很麻烦。
我们先看一下日期框的元素,如下图所示:

重点看一下value=‘text’,这种属性值可以通过JavaScript来改变,三行代码就能解决这个问题,如下图所示:

第一行是要输入的日期,第二行是JavaScript代码,“documen.getElementById”是通过HTML的“id”定位元素,通过改变该元素的“value”实现值的变化。
效果演示如下:
/3 场景二:动态网页自动下拉/
一些复杂的动态网页需要下拉才能把元素显示完全,例如腾讯视频主页,如下图所示:
如果需要自动爬取这类动态网页,我们同样可以执行JavasScript的方法来实现,用5行代码就可以连续滑动网页,将动态网页元素全部展示出来,代码如下图所示:
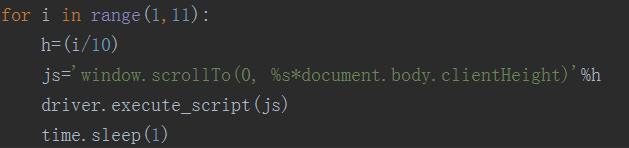
小编这里采取的分步下拉的方法,每次滚动1/10,“window.scrollTo”为向下滑动的命令,“document.body.clientHeight”为整个窗口的高度,“h=(i/10)”为每次滑动的高度。
效果演示如下:
/4 结语/
将JavaScript应用到selenium中可以帮我们解决很多问题,这里举两个小例子只是抛砖引玉,希望大家以后遇到selenium不好解决的问题时可以考虑在JavaScript身上寻找突破。
欢迎大家积极尝试,消耗在家的无聊时间。
本文涉及的代码都上传到了github地址上,https://github.com/cassieeric/python_crawler/tree/master/selenium_skill,觉得不错,记得给个star噢~
