1.场景与需求
如下图,id记录用户的编号,name记录用户的行为;
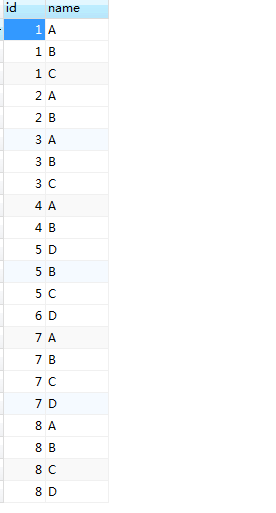
当前场景进行用户分类,将相同行为的用户查询出来。
2.SQL实现:

3.SQL解读:
由于SQL的执行优先级: from > where > group by > having >select > order by ;所以
where 筛选集合中的元素,
group by 生成子集,
having 专注于集合本身的性质,
而having的使用往往能得到意想不到的效果。
先运行下图所选中的代码,

where条件进行过滤,产生了如下结果集(只展示部分)
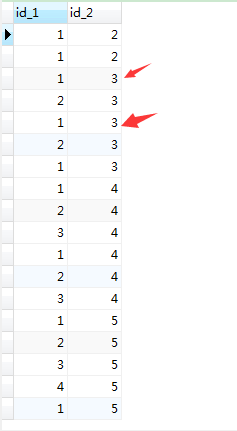
如上图,红色标记的情况,结果集中出现大量这种重复,因此加入"group by P1.id,P2.id"进行去重。
而having控制了完全一一映射的关系。
最后一重'group by'解决了重复关系的问题。
