本项目使用Python语言对银行的个人金融业务数据进行分析,以对个人贷款会否违约进行预测。
本文目录:
1 导入数据
2 数据整理
3 逻辑回归建模预测
参考
1 导入数据
数据集来自《数据科学实战:Python篇》的老师Ben,感谢Ben老师的分享和讲解。
本项目数据集包含:账户表accounts、信用卡表card、客户信息表clients、权限分配表disp、人口地区统计表district、贷款表loans、支付命令表order、交易表trans。
1.1 导入基础库
import numpy as np
import pandas as pd
from pandas importSeries,DataFrame
import matplotlib.pyplotas plt
%matplotlib inline
import os
os.chdir(r'E:\...\个人贷款违约预测\案例')
os.getcwd()
'E:\\...\个人贷款违约预测\\案例'
1.2 导入数据
loanfile=os.listdir()
createVar=locals()
for i inloanfile:
if i.endswith('csv'):
createVar[i.split('.')[0]]=pd.read_csv(i,encoding='gbk')
print(i.split('.')[0])
accounts
card
clients
disp
district
loans
order
trans
2 数据整理
2.1 生成被解释变量
loans.head()
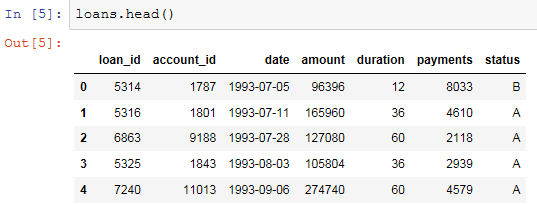
查看贷款表的描述信息
loans.describe()

查看贷款表中用户还款状态信息,并用字典生成被解释变量。
loans.status.value_counts()
C 403
A 203
D 45
B 31
Name: status,dtype: int64
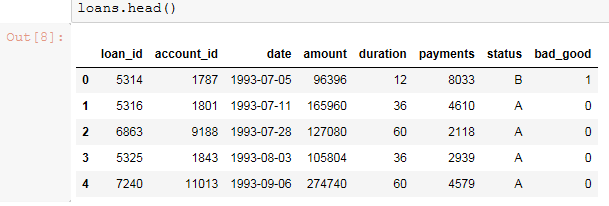
bad_good={'A':0,'B':1,'D':1,'C':2}
loans['bad_good']=loans.status.map(bad_good)
loans.head()
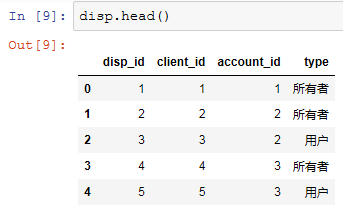
2.2 数据合并
disp.head()
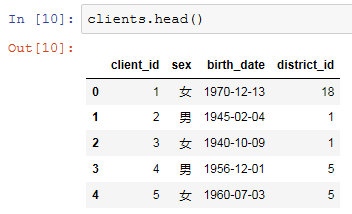
clients.head()
data2=pd.merge(loans,disp,on='account_id',how='left')
data2=pd.merge(data2,clients,on='client_id',how='left')
data2.head()
district.head()
data3=pd.merge(data2,district,left_on='district_id',right_on='A1',how='left')
data3.head()

2.3 计算贷款前一年账户的平均余额、余额的标准差、变异系数、平均支出与平均收入的比例、贷存比和贷收比
trans.head()
data4_t1=pd.merge(data3[['account_id','date']],trans[['account_id','type','amount','balance','date']],on='account_id')
data4_t1.columns=['account_id','date','type','amount','balance','t_date']
data4_t1.head(10)

data4_t1.info()
<class'pandas.core.frame.DataFrame'>
Int64Index: 233627entries, 0 to 233626
Data columns (total6 columns):
account_id 233627 non-null int64
date 233627 non-null object
type 233627 non-null object
amount 233627 non-null object
balance 233627 non-null object
t_date 233627 non-null object
dtypes: int64(1),object(5)
memory usage: 12.5+MB
数据转换:将data4_t1的date和t_date列数据类型转换为时间类型
data4_t1.date=pd.to_datetime(data4_t1.date)
data4_t1.t_date=pd.to_datetime(data4_t1.t_date)
data4_t1=data4_t1.sort_values(by=['account_id','t_date'])
data4_t1.tail()
数据转换:将data4_t1的amount和balance列数据类型转换为数值类型
data4_t1['amount2']=data4_t1.amount.map(lambda x : int(''.join(x[1:].split(','))))
data4_t1['balance2']=data4_t1.balance.map(lambda x : int(''.join(x[1:].split(','))))
data4_t1.head()
data4_t1.info()
<class'pandas.core.frame.DataFrame'>
Int64Index: 233627entries, 11182 to 156331
Data columns (total8 columns):
account_id 233627 non-null int64
date 233627 non-null datetime64[ns]
type 233627 non-null object
amount 233627 non-null object
balance 233627 non-null object
t_date 233627 non-null datetime64[ns]
amount2 233627 non-null int64
balance2 233627 non-null int64
dtypes:datetime64[ns](2), int64(3), object(3)
memory usage: 16.0+MB
将交易数据的时间窗口设置为贷款前一年期间
import datetime
data4_t2=data4_t1[(data4_t1.date>data4_t1.t_date)&(data4_t1.date<data4_t1.t_date+datetime.timedelta(days=365))]
data4_t2.tail()
计算账户的平均余额、余额的标准差、变异系数
data4_t3=data4_t2.groupby('account_id')['balance2'].agg([('avg_balance','mean'),('std_balance','std')])
data4_t3['cv_balance']=data4_t3[['avg_balance','std_balance']].apply(lambda x :x[1]/x[0],axis=1)
data4_t3.head(10)

计算平均支出与平均收入的比例
type_dict={'借':'out','贷':'income'}
data4_t2['type2']=data4_t2.type.map(type_dict)
data4_t4=data4_t2.groupby(['account_id','type2'])[['amount2']].sum()
data4_t4.head(10)
data4_t5=pd.pivot_table(data4_t4,values='amount2',index='account_id',columns='type2')
data4_t5.fillna(0,inplace=True)
data4_t5['r_out_in']=data4_t5[['out','income']].apply(lambda x :x[0]/x[1],axis=1)
data4_t5.head(10)

数据合并
data4=pd.merge(data3,data4_t3,left_on='account_id',right_index=True,how='left')
data4=pd.merge(data4,data4_t5,left_on='account_id',right_index=True,how='left')
data4.head(10)
计算贷存比和贷收比
data4['r_lb']=data4[['amount','avg_balance']].apply(lambda x : x[0]/x[1],axis=1)
data4['r_lin']=data4[['amount','income']].apply(lambda x : x[0]/x[1],axis=1)
data4.head()

提取权限类型是“所有者”行,去除权限类型是“用户”的行,因为只有“所有者”才有权限进行贷款。
data4=data4[data4.type=='所有者']
data4.info()
<class'pandas.core.frame.DataFrame'>
Int64Index: 682entries, 0 to 826
Data columns (total32 columns):
loan_id 682 non-null int64
account_id 682 non-null int64
date 682 non-null object
amount 682 non-null int64
duration 682 non-null int64
payments 682 non-null int64
status 682 non-null object
bad_good 682 non-null int64
disp_id 682 non-null int64
client_id 682 non-null int64
type 682 non-null object
sex 682 non-null object
birth_date 682 non-null object
district_id 682 non-null int64
A1 682 non-null int64
GDP 682 non-null int64
A4 682 non-null int64
A10 682 non-null float64
A11 682 non-null int64
A12 674 non-null float64
A13 682 non-null float64
A14 682 non-null int64
A15 674 non-null float64
a16 682 non-null float64
avg_balance 682 non-null float64
std_balance 682 non-null float64
cv_balance 682 non-null float64
income 682 non-null float64
out 682 non-null float64
r_out_in 682 non-null float64
r_lb 682 non-null float64
r_lin 682 non-null float64
dtypes:float64(13), int64(14), object(5)
memory usage:175.8+ KB
3 逻辑回归建模预测
3.1 提取相关数据
data4.columns
Index(['loan_id','account_id', 'date', 'amount', 'duration', 'payments',
'status', 'bad_good', 'disp_id','client_id', 'type', 'sex',
'birth_date', 'district_id', 'A1','GDP', 'A4', 'A10', 'A11', 'A12',
'A13', 'A14', 'A15', 'a16','avg_balance', 'std_balance', 'cv_balance',
'income', 'out', 'r_out_in', 'r_lb','r_lin'],
dtype='object')
data_model=data4[data4['status']!='C']
for_predict=data4[data4['status']=='C']
train=data_model.sample(frac=0.7,random_state=1235).copy()
test=data_model[~data_model.index.isin(train.index)].copy()
print('训练样本量:%i \n测试样本量:%i' %(len(train),len(test)))
训练样本量:195
测试样本量:84
len(data_model),len(for_predict),len(data4)
(279, 403, 682)
3.2 建模
def forward_select(data,response):
import statsmodels.api as sm
import statsmodels.formula.api as smf
remaining = set(data.columns)
remaining.remove(response)
selected = []
current_score,best_new_score = float('inf'), float('inf')
while remaining:
aic_with_candidates=[]
forcandidate in remaining:
formula = "{} ~ {}".format(
response,'+ '.join(selected + [candidate]))
aic = smf.glm(
formula=formula, data=data,
family=sm.families.Binomial(sm.families.links.logit)
).fit().aic
aic_with_candidates.append((aic,candidate))
aic_with_candidates.sort(reverse=True)
best_new_score,best_candidate=aic_with_candidates.pop()
ifcurrent_score > best_new_score:
remaining.remove(best_candidate)
selected.append(best_candidate)
current_score = best_new_score
print ('aicis {},continuing!'.format(current_score))
else:
print ('forwardselection over!')
break
formula = "{} ~ {} ".format(response,' + '.join(selected))
print('final formula is {}'.format(formula))
model = smf.glm(
formula=formula, data=data,
family=sm.families.Binomial(sm.families.links.logit)
).fit()
return(model)
candidates = ['bad_good', 'A1', 'GDP', 'A4', 'A10', 'A11', 'A12','amount', 'duration',
'A13', 'A14', 'A15', 'a16', 'avg_balance', 'std_balance',
'cv_balance', 'income', 'out', 'r_out_in', 'r_lb', 'r_lin']
data_for_select =train[candidates]
lg_m1=forward_select(data=data_for_select,response='bad_good')
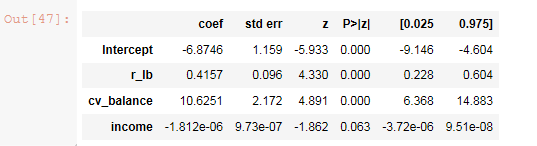
lg_m1.summary().tables[1]
aic is167.4331143250464,continuing!
aic is135.49278268705092,continuing!
aic is133.50978045995745,continuing!
forward selectionover!
final formula isbad_good ~ r_lb + cv_balance + income
3.3 用测试集对模型进行评估
import sklearn.metricsas metrics
fpr,tpr,th=metrics.roc_curve(test.bad_good,lg_m1.predict(test))
plt.figure(figsize=[6,6])
plt.plot(fpr,tpr,'b--')
plt.title('ROC curve')
Text(0.5,1,'ROCcurve')
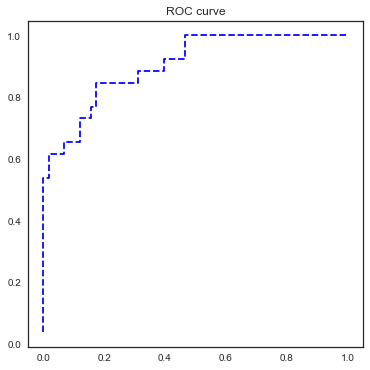
print('AUC=%.4f' %metrics.auc(fpr,tpr))
AUC=0.9045
3.4 预测
for_predict['prob']=lg_m1.predict(for_predict)
for_predict[['account_id','prob']].head(10)

参考:
1、《数据科学实战:Python篇》by Ben
2、《利用Python进行数据分析》机械工业出版社 Wes Mckinney著 唐雪韬等译

