上次听完丘老师的课,就想自己尝试做个小项目,于是,今天在有台风的日子,缩在电脑前琢磨下。
案例都是根据丘老师的在视屏中以新浪新闻举例爬虫的思想做的。
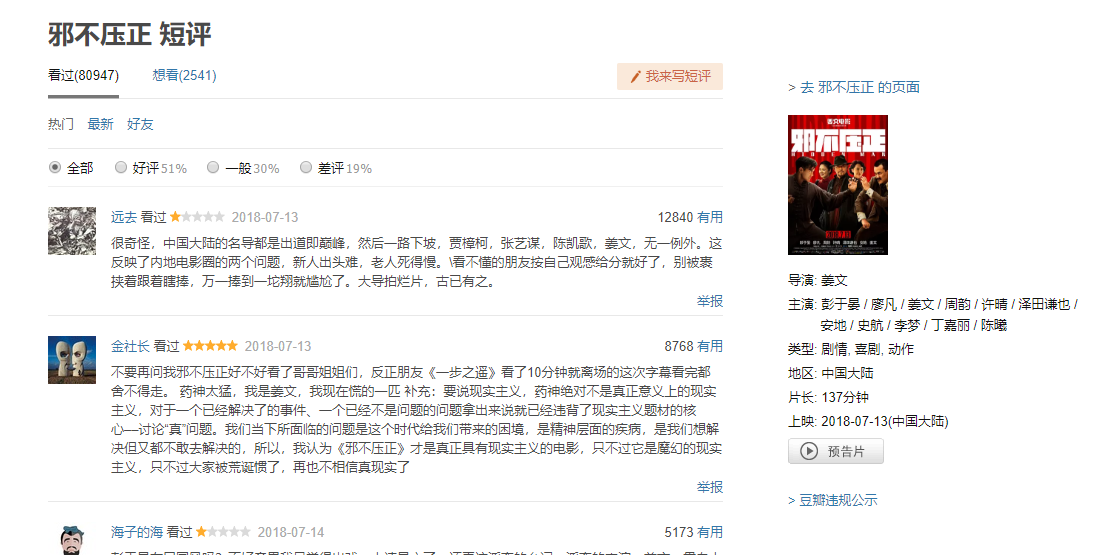
因为这周去看了姜文的《邪不压正》,看的全程,一脸懵逼。所以这次案例就是在豆瓣上爬取关于这部电影的影评。
一、分析网页:
我们打开豆瓣网页,点击《邪不压正》,然后点击
红线部分,就进入短评界面了。
右键然后选择‘检查’这时就出现代码框,选择网页窃听器Network,我们先去看Doc下有没有我们要找的东西,点击‘Doc’往下拉动,会看到第一条评论的信息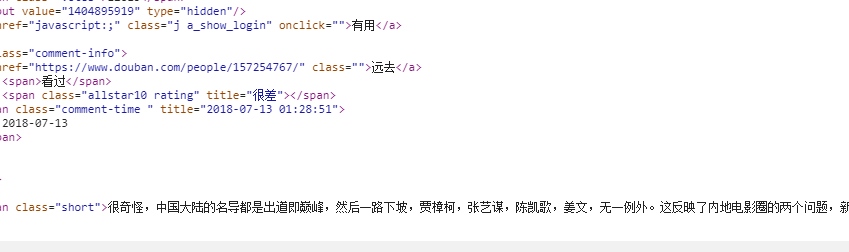
所以我们找到他的url: 他的获取方式是Get。所以我们先获取网页信息:
他的获取方式是Get。所以我们先获取网页信息:
import requests
res = requests.get('https://movie.douban.com/subject/26366496/comments?sort=time')
print(res.text)
然后运行成功。获得了网页信息。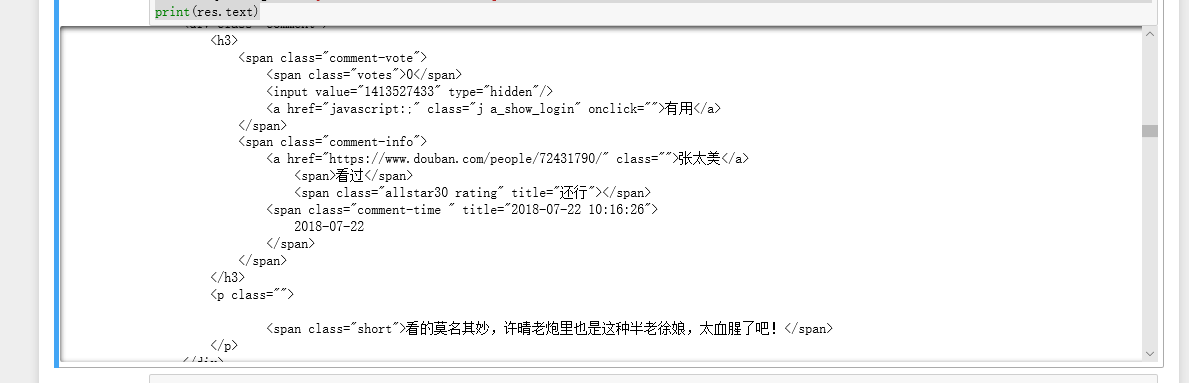
二、获取所需信息
影评一般有几个部分组成,一个是评论人的昵称,一个是评论时间,还有评论内容和评论的等级。这里等级我们在网页中看到页面显示是几颗星,在代码里就自动对应了文字。一颗星是很差,两颗星是较差,三颗星是还行,四颗星是推荐,五颗星是力荐。想好了我们要获取的信息,那么接下来我们就去获取每个影评的这些信息要素。
如何获取每页信息,因为每个影评的要素都一样,我们先从网页上获取所有的影评信息,然后采取循环遍历的方式,把一页20条影评的这些信息获取到。然后再采用这种思想,生成网页的url,这样我们就能获取每个网页的20条影评信息了。好啦,思路有了,下面就是技术的干活。
开始之前我们采用BeautifulSoup4来解析网页。
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,'html.parser')
print(soup)#打印出来看看
1.获取影评内容。
在这个版块我特别推荐丘老师公司开发的一个定位插件,这个插件可以定位你要获取的信息在那个目录下,真的很好用,我下面获取信息,有一步就是这个插件帮我的,这个插件是免费的,不过需要翻墙才能下载。但,我有一位超牛的同事,他翻墙把这个插件下载,又 把他打包成了一个Chrome安装包。大家有需要的可以私聊我,具体如何使用请观看丘老师的课程,他在课程里有介绍。我把链接放在这:https://edu.hellobi.com/course/81
我们通过查看代码,发现内容在class下的short下面 所以我们通过课堂上丘老师讲的方法,可以使用select找出所有class下为short的内容,在short前要加‘.’。代码如下:
所以我们通过课堂上丘老师讲的方法,可以使用select找出所有class下为short的内容,在short前要加‘.’。代码如下:
short = soup.select('.short')[0].text
print(short)
这里说明下,代码
short = soup.select('.short')
print(short)
会把所有影评信息打印出来,基于我们上面的思想,所以我们打印出第一条就行了,然后我们发现这是一个列表,所以在使用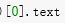 把第一页第一条影评内容打印出来。
把第一页第一条影评内容打印出来。
 。
。
好啦。这步结束。
2.获取时间。
用丘老师的插件点击时间,我们发现他在
class下的comment-time下。所以在此使用Class点获取信息。
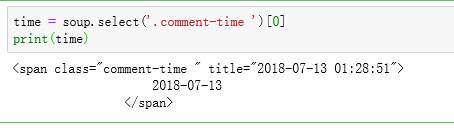
在我们获取信息时,发现返回结果里还带有代码,所以我直接就想使用 ,但这获取的结果只有年月日,没有分秒,
,但这获取的结果只有年月日,没有分秒,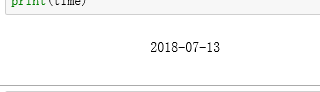
所以我就想我想获取信息在title下面,所以我在 后面直接加了
后面直接加了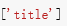 然后就得到了我们想要的信息。
然后就得到了我们想要的信息。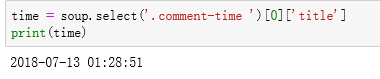 。
。
哈哈,第二步搞定。
3.获取评级
评级是在 allstar20 rating这个下面,但使用class点时发现是空列表,然后用丘老师的插件发现他是在
allstar20 rating这个下面,但使用class点时发现是空列表,然后用丘老师的插件发现他是在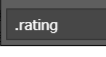 下面,然后使用class点。哈哈,获取到了。
下面,然后使用class点。哈哈,获取到了。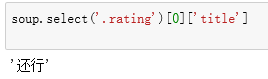 这时也是使用的['title']。
这时也是使用的['title']。
4.获取昵称
在获取昵称时,犯了难,因为昵称是在 a目录下的,使用丘老师教的方法,获取a标签下的东西,直接select(‘a’)就可以,但结果出来第一条不是我们想要的昵称,而是
a目录下的,使用丘老师教的方法,获取a标签下的东西,直接select(‘a’)就可以,但结果出来第一条不是我们想要的昵称,而是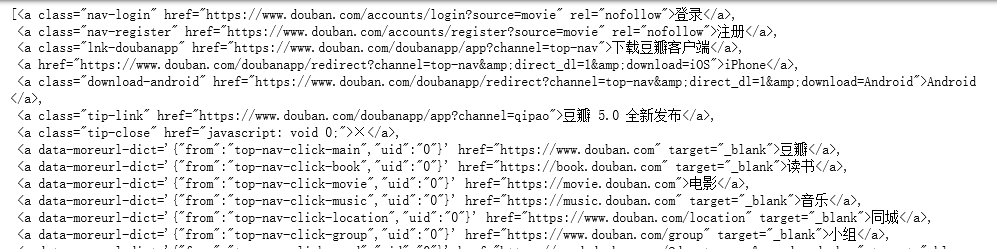
这种,所以我在想能不能用切片的方式,所以我就用切片方式,找出第一个昵称出来是32,每隔3个出来一条,一直到89个,但这时我就在想如果这样把一页昵称都打印出来,如何和时间,内容去对应。在次看了看在听丘老师课程时,我做的笔记,突然幡然醒悟,原来我的思路出现了错误。我当初就想把我们每页所有评论的昵称,时间,内容都一下子获取到,前面获取时间,内容没有出现bug,所以我没注意到,在获取昵称时,发现网页的有些信息也是在a这个目录下面的,所以获取信息时会产生干扰。
所以我们这时先获取所有影评信息。查找代码,发现他在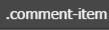 下面,所以代码如下:
下面,所以代码如下:
item = soup.select('.comment-item')
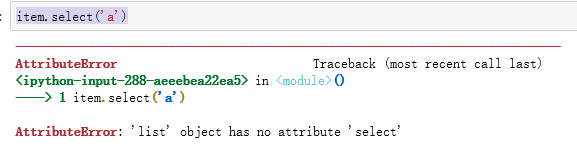
然后采用下面代码
item.select('a')
发现出错了,报错信息是list没有select这个方法,
所以我采用了循环方法。

然后就获取到了。哈哈。
5.定义函数
为下一步循环遍历网页信息做准备。

这时我们输入一个网址就可以获得该页信息上的影评的时间,昵称,评级,内容。
6.分页链接
这是一个分页模式,在我们翻页时就会发现在网页链接时,我们先看看几个链接
https://movie.douban.com/subject/26366496/comments?start=0&limit=20&sort=new_score&status=P
https://movie.douban.com/subject/26366496/comments?start=20&limit=20&sort=new_score&status=P
https://movie.douban.com/subject/26366496/comments?start=40&limit=20&sort=new_score&status=P
然后我们就发现网址只有start后的数字改变了,而且是以20倍数在改变。所以我们把start后的数字换成{}这个大括号,使用for循环,再用if判断语句生成20的倍数。在利用format函数生成链接。语句如下:
url = 'https://movie.douban.com/subject/26366496/comments?start={}&limit=20&sort=new_score&status=P'
for i in range(0,100):
if i%20 == 0:
print(url.format(i))
这时我们生成了如下链接:

7.获取每页信息。
代码如下:
url = 'https://movie.douban.com/subject/26366496/comments?start={}&limit=20&sort=new_score&status=P'
commentsdetails(url)
for i in range(0,100):
if i%20 == 0:
commentsurl = url.format(i)
commentsary = commentsdetails(commentsurl)
print(commentsary)
在获取前4页信息时程序跑的很好,但在第第五页时就出错了。问题是这样。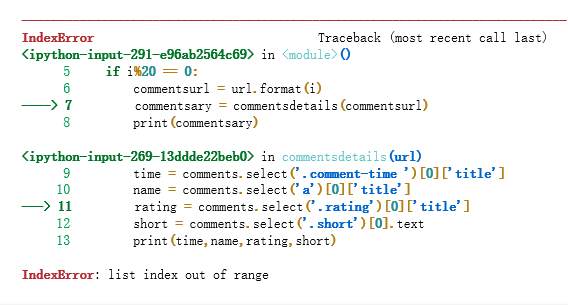
然后我就不知道如何破了,难道是豆瓣的反爬虫吗?
如果有大神知道这个问题,还请麻烦再评论里指出。
写在最后:
这是我学Python的第一次写案例,里面的知识还有很多不懂,这个案例也算是一种生搬硬套。不过写下来,觉得我的思路清楚了。所以冒着被拍砖的危险,斗胆在各位大神前写写在做案例的过程。里面的术语可能有些不专业,如果发现,请指正,我会立马改过来的。
如果你看完了,非常感谢。我会再接再厉的。

