AHP (Analytic Hierarchy Process)层次分析法是美国运筹学家Saaty教授于二十世纪80年代提出的一种实用的多方案或多目标的决策方法。其主要特征是,它合理地将定性与定量的决策结合起来,按照思维、心理的规律把决策过程层次化、数量化。
层次分析法的基本思路:先分解后综合
首先将所要分析的问题层次化,根据问题的性质和要达到的总目标,将问题分解成不同的组成因素,按照因素间的相互关系及隶属关系,将因素按不同层次聚集组合,形成一个多层分析结构模型,最终归结为最低层(方案、措施、指标等)相对于最高层(总目标)相对重要程度的权值或相对优劣次序的问题。
用AHP分析问题大体要经过以下五个步骤:
(1)建立层次结构模型;
(2)构造判断矩阵;
(3)层次单排序;
(4)一致性检验;
(5)层次总排序。
其中后三个步骤在整个过程中需要逐层地进行。
以下是一个情景案例:
假期你想要出去旅游,现有三个目的地(方案):
古风古韵的西安(P1);
天府之国的成都(P2);
如诗如画的杭州(P3)。
假如选择的标准和依据(行动方案准则)有5个:
景色,费用,饮食,居住和旅途。
则常规思维的方式一般是:
1、先确定这些准则在心中的各自占比的大小;
2、然后就每一准则将三个地点进行比较;
3、最后将这两个层次的比较判断进行综合,做出选择。
以下是根据分析思路构建的层次分析法结构模型:
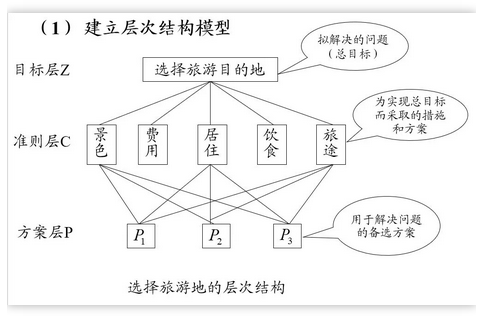
以上结构模型中,我们需要比较准侧层各个准则相对于目标的权重,同时也要比较方案层各个方案相对于准侧层每一个准则的权重。
权重的判断建立在专家打分的基础上,即通过一组打分标准,来赋予单层各个指标的相对权重。
这里的打分机制使用1~9标度法:
1代表两个元素相比,具有相同的重要性;
3代表两个元素相比,前者比后者稍重要;
5代表两个元素相比,前者比后者明显重要;
7代表两个元素相比,前者比后者极其重要;
9代表两个元素相比,前者比后者强烈重要
2,4,6,8表示上述相邻判断的中间值。
以上准则层的5个指标依次是:
景色:C1
费用:C2
居住:C3
饮食:C4
旅途:C5
相对于目标层:选择旅游地,进行两两比较打分。
景色 费用 居住 饮食 旅途 C1 C2 C3 C4 C5
C1 1 1/2 4 3 3
C2 2 1 7 5 5
C3 1/4 1/7 1 1/2 1/3
C4 1/3 1/5 2 1 1
C5 1/3 1/5 2 1 1
构造所有相对于不同准则的方案层判断矩阵
相对于景色
P1 p2 p3
P1 1 2 5
P2 1/2 1 2
P3 1/5 1/2 1
相对于费用
P1 p2 p3
P1 1 1/3 1/8
P2 3 1 1/3
P3 8 3 1
相对于居住
P1 p2 p3
P1 1 1 3
P2 1 1 3
P3 1/3 1/3 1
相对于饮食
P1 p2 p3
P1 1 3 4
P2 1/3 1 1
P3 1/4 1 1
相对于旅途
P1 P2 P3
P1 1 1 1/4
P2 1 1 1/4
P3 4 4 4
以下是整个层次分析法的整个建模流程:


#清空R语言环境内存
rm(list = ls())gc()
#加载包
library("readxl")
library("dplyr")
library("magrittr")
准则层:
C1——景色
C2——费用
C3——居住
C4——饮食
C5——旅途
方案层:
P1——西安
P2——成都
P3——杭州
准则层与方案层的判定矩阵:(专(hu)家 (luan) 打 (tian) 分 (xie) )
#准则层判断矩阵
data_C <- matrix( c(1,2,1/4,1/3,1/3,1/2,1,1/7,1/5,1/5,4,7,1,2,3,3,5,1/2,1,1,3,5,1/3,1,1), nrow = 5, dimnames = list(c("C1","C2","C3","C4","C5"),c("C1","C2","C3","C4","C5")))
#景色判断矩阵
data_B1 <- matrix( c(1,1/2,1/5,2,1,1/2,5,2,1), nrow = 3, dimnames = list(c("P1","P2","P3"),c("P1","P2","P3")))
#费用判断矩阵
data_B2 <- matrix( c(1,3,8,1/3,1,3,1/8,1/3,1), nrow = 3, dimnames = list(c("P1","P2","P3"),c("P1","P2","P3")))
#居住判断矩阵
data_B3 <- matrix( c(1,1,1/3,1,1,1/3,3,3,1), nrow = 3, dimnames = list(c("P1","P2","P3"),c("P1","P2","P3")))
#饮食判断矩阵
data_B4 <- matrix( c(1,1/3,1/4,3,1,1,4,1,1), nrow = 3, dimnames = list(c("P1","P2","P3"),c("P1","P2","P3")))
#路途判断矩阵
data_B5 <- matrix( c(1,1,4,1,1,4,1/4,1/4,1), nrow = 3, dimnames = list(c("P1","P2","P3"),c("P1","P2","P3")))
准侧层判别过程:
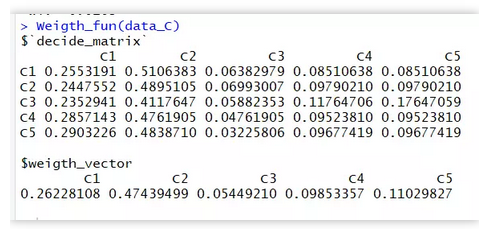
1、判断矩阵归一化:
Weigth_fun <- function(data){
if(class(data) == 'matrix'){ data = data } else {
if ( class(data) == 'data.frame' & nrow(data) == ncol(data) - 1 & is.character(data[,1,drop = TRUE])){ data = as.matrix(data[,-1]) } else if (class(data) == 'data.frame' & nrow(data) == ncol(data)) { data = as.matrix(data) } else {
stop('please recheck your data structure , you must keep a equal num of the row and col') } } sum_vector_row = data %>% apply(2,sum) decide_matrix = data %>% apply(1,function(x) x/sum_vector_row) weigth_vector = decide_matrix %>% apply(2,sum) result = list(decide_matrix = decide_matrix, weigth_vector = weigth_vector/sum(weigth_vector ))
return(result)}Weigth_fun(data_C)
2、输出特征向量λ
AW_Weight <- function(data){
if(class(data) == 'matrix'){ data = data } else {
if ( class(data) == 'data.frame' & nrow(data) == ncol(data) - 1 & is.character(data[,1,drop = TRUE])){ data = as.matrix(data[,-1]) } else if (class(data) == 'data.frame' & nrow(data) == ncol(data)) { data = as.matrix(data) } else {
stop('please recheck your data structure , you must keep a equal num of the row and col') } } AW_Vector = data %*% Weigth_fun(data)$weigth_vector λ = (AW_Vector/Weigth_fun(data)$weigth_vector) %>% sum(.) %>% `/`(length(AW_Vector)) result = list( AW_Vector = AW_Vector, `∑AW/W` = AW_Vector/Weigth_fun(data)$weigth_vector, λ = λ ) return(result)}AW_Weight(data_C)
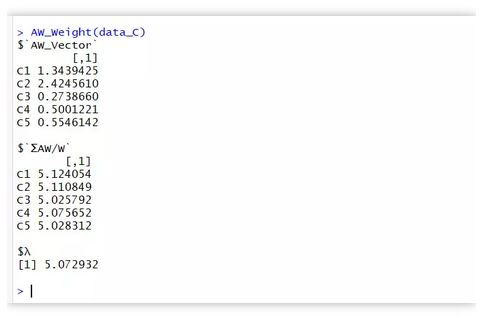
3、一致性检验:

Consist_Test <- function(λ,n){ RI_refer = c(0,0,0.52,0.89,1.12,1.26,1.36,1.41,1.46,1.49,1.52,1.54) CI = (λ - n)/(n - 1) CR = CI/(RI_refer[n])
if (CR <= .1){ cat(" 通过一致性检验!",sep = "
") cat(" Wi: ", round(CR,4), "
") } else { cat(" 请调整判断矩阵!","
") } return(CR)}Consist_Test(AW_Weight(data_C)$λ,5)
通过一致性检验!
Wi: 0.0163
[1] 0.01627942
OutPut:
(利用上述各步代码,将准则层、方案层的所有权重向量、特征值及一致性检验结果输出)
#准则层:
rule_Weigth_C <- Weigth_fun(data_C)$weigth_vector #准则层特征向量
rule_λ_C <- AW_Weight(data_C)$λ #准则层特征值
CR_C <- Consist_Test(AW_Weight(data_C)$λ,5) #准则层一致性检验:
rule_Weigth_C1 <- Weigth_fun(data_B1)$weigth_vector #方案层(for C1)特征向量
rule_Weigth_C2 <- Weigth_fun(data_B2)$weigth_vector #方案层(for C2)特征向量
rule_Weigth_C3 <- Weigth_fun(data_B3)$weigth_vector #方案层(for C3)特征向量
rule_Weigth_C4 <- Weigth_fun(data_B4)$weigth_vector #方案层(for C4)特征向量
rule_Weigth_C5 <- Weigth_fun(data_B5)$weigth_vector #方案层(for C5)特征向量
scheme_λ_C1 <- AW_Weight(data_B1)$λ #方案层(for C1)特征值
scheme_λ_C2 <- AW_Weight(data_B2)$λ #方案层(for C2)特征值
scheme_λ_C3 <- AW_Weight(data_B3)$λ #方案层(for C3)特征值
scheme_λ_C4 <- AW_Weight(data_B4)$λ #方案层(for C4)特征值
scheme_λ_C5 <- AW_Weight(data_B5)$λ #方案层(for C5)特征值
CR_C1 <- Consist_Test(AW_Weight(data_B1)$λ,3) #方案层(for C1)一致性检验
CR_C2 <- Consist_Test(AW_Weight(data_B2)$λ,3) #方案层(for C2)一致性检验
CR_C3 <- Consist_Test(AW_Weight(data_B3)$λ,3) #方案层(for C3)一致性检验
CR_C4 <- Consist_Test(AW_Weight(data_B4)$λ,3) #方案层(for C4)一致性检验
CR_C5 <- Consist_Test(AW_Weight(data_B5)$λ,3) #方案层(for C5)一致性检验
层次总排序:
all_matrix <- matrix(c(rule_Weigth_C1,rule_Weigth_C2,rule_Weigth_C3,rule_Weigth_C4,rule_Weigth_C5),nrow = 3)decide_result <- all_matrix %*% rule_Weigth_Cdimnames(decide_result) <- list(c("P1","P2","P3"),"score") scoreP1 0.2990074
P2 0.2454134
P3 0.4555792
P3(杭州) > p1(西安) > P2(成都)
最终决策结果显示,我们应该去的地方推荐优先级分别为:杭州 > 西安 > 成都
备注(因为打分数据是虚构的,所以并没有任何决策价值)
Python:
(备注:这里只给出使用Python构造模型的工具代码,具体判定过程需要自己操作)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import time
import numpy as np
import pandas as pd import os
from scrapy.exceptions import DropItemnp.random.seed(233333)os.chdir('D:/R/File')
#!!!
#温馨提示,这里的函数是基于pandas数据框,
#如果直接构造的矩阵数组,需要微调代码!
#判定矩阵归一化
def Weight(data): if data.shape[0] == data.shape[1] - 1 and data.iloc[:,0].dtype == 'object': data = data.iloc[:,1:] data.index = data.columns elif data.shape[0] == data.shape[1]: data.index = data.columns
else:
raise DropItem("please recheck your data structure , you must keep a equal num of the row and col") weigth_matrix = data.loc[:,].values weight_vector = weigth_matrix/np.sum(data.loc[:,].values,0) sum_vector_col = weight_vector.sum(axis = 1)
return {
"weigth_matrix":weigth_matrix,
"weight_vector":sum_vector_col/sum_vector_col.sum() }Weight(mydata)["weigth_matrix"]Weight(mydata)["weight_vector"]
#计算权重矩阵与特征值、特征向量
def AW_Weight(data): if data.shape[0] == data.shape[1] - 1 and data.iloc[:,0].dtype == 'object': data = data.iloc[:,1:] data.index = data.columns elif data.shape[0] == data.shape[1]: data.index = data.columns
else:
raise DropItem("please recheck your data structure , you must keep a equal num of the row and col") AW_Vector = np.dot(data.values,Weight(mydata)["weight_vector"]) λ = (AW_Vector/Weight(mydata)["weight_vector"]).sum()/len(AW_Vector)
return dict( AW_Vector = AW_Vector, AW_Vector_w = AW_Vector/Weight(mydata)["weight_vector"], λ = λ )AW_Weight(mydata)["AW_Vector"]AW_Weight(mydata)["AW_Vector_w"]AW_Weight(mydata)["λ"]
#一致性检验
def Consist_Test(λ,n): RI_refer = [0,0,0.52,0.89,1.12,1.26,1.36,1.41,1.46,1.49,1.52,1.54] CI = (λ - n)/(n - 1) CR = CI/(RI_refer[n-1])
if (CR <= 0.1): print(" 通过一致性检验!") print(" Wi: ", np.round(CR,4))
else: print(" 请调整判断矩阵!","
")
return np.round(CR,4)
层次分析法虽然在多目标决策上可以很好地将定性决策定量化,但越是完美无缺的:
1~9标准打分机制是否合理(因为几乎很难区别出临界两个分值之间的区别)
专家打分如何保证专家基于同一样的评分尺度、客观公允不划水,这些都是问题。
没有完美无缺的模型,还是要具体问题具体分析,多方案交叉验证效果!
参考资料:
《层次分析法原理》——章牧
如果你想要深入的去学ggplot2,但是又苦于平时学习、工作太忙木有时间研究浩如烟海的源文档,那也没关系,本小编最近花了不少功夫,把我自己学习ggplot2过程中的一些心得体会、学习经验、仿入坑指南精心整理,现已成功上线了R语言ggplot2可视化的视频课程,由天善智能独家发行,希望这门课程可以给你的R语言数据可视化学习带来更加丰富的体验。
相关课程推荐
体系全面,最具调性!R语言可视化&商务图表实战课程:https://edu.hellobi.com/course/264