提前声明,这不是一个好的例子,所以不要向我学习。让我先冷静一下!
OK,开始,今天我们开始从下面链接爬虫。
http://www.imdb.com/search/title?count=100&release_date=2016,2016&title_type=feature。
打开页面如下:总共有100页,包含电影1万多部。我只爬取了2000个。(PS:等我截下面这张图时顺序已经和原来的不一样了)
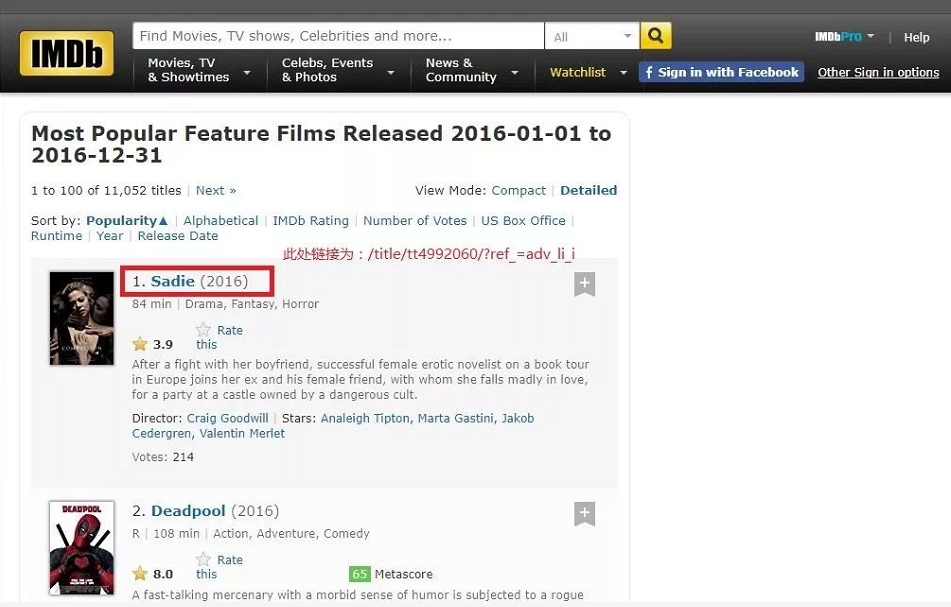
这个页面已经显示海报了,但是爬出来之后图片太小,也太模糊,不能满足我的需求,因此继续爬出电影主页链接。进去之后页面如下,海报大小质量还算可以基本能满足我的要求,如下图。因此第一步就把爬取电影主页链接。(有没有看见妹子在盯着你)
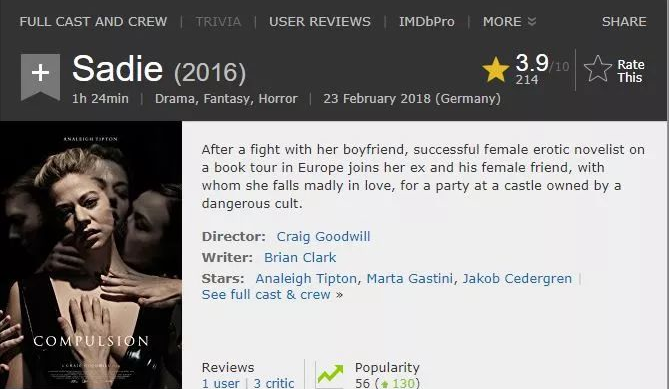
直接上代码,不过方法不可取,要不怎么说只有我敢这么做。
library(rvest)
library(downloader)#用来下载
library(stringr)#字符处理
i<-1link<-c()
url<-"http://www.imdb.com/search/title?count=100&release_date=2016,2016&title_type=feature"#我们从这页开始爬,我只怕前20页
for( a in 1:20){#每页100个,刚好20页
web<-read_html(url)
link1<-web%>%html_nodes("div.lister-list div.lister-item-image a")%>%html_attr("href")
url<-html_session(url)%>%follow_link("Next »")#获取下一页链接
url<-url$url #提取下一页链接
cat(sprintf("第[%i]页已爬完",i),sep = "\n")#打印信息,这页我们就知道那一页失败了
link<-c(link,link1)
i<-i+1
}
在这里,我需要说一下follow_link这个函数,它用来提取Next »字符的链接。也就是我们把第一页爬完后,它可以帮助我们获取下一页的链接。
这样爬取的电影主页链接为/title/tt4992060/?ref_=adv_li_i这种形式。因此需要在前面加上http://www.imdb.com。
link_title<-paste("http://www.imdb.com",link,sep = "")#给前面爬到的链接前加上http://www.imdb.com之后这个链接就是每个电影主页的链接
ok,现在我们电影主页链接爬好了,现在就是爬图片,电影名,评分,评分人数了。
name<-paste(1:2000,".png")
for(i in 1:2000){
all_message<-read_html(link_title[i])
poster <- all_message %>%
html_nodes("div.poster img") %>%
html_attr("src") #提取海报链接
download(poster,destfile=name[i],mode="wb") #下载图片 ,wb情况下下载图片质量高
movie_name_temp<-all_message%>%html_nodes("div.title_wrapper h1")%>%html_text()
movie_name[i]<-str_sub(movie_name_temp,1,-20) #提取电影名
movie_score[i]<-all_message%>%html_nodes("strong span")%>%html_text() #提取评分
movie_people[i]<-all_message%>%html_nodes("div.imdbRating a span")%>%html_text() #提取评分人数
cat(sprintf("第[%i]张已下载",i),sep = "\n") #显示爬到哪一页了
Sys.sleep(5) #由于没有用代理,那就慢慢爬吧。
}
爬好的数据如下,不过第1394, 1807, 1889, 1947个没有海报。

下面是movie_data.txt文件的部分数据,分别是电影名,电影评分,评分人数,电影链接。这里的顺序和海报的顺序是对应的哦,不过有的电影评分和评分人数为NA,那是因为电影没有评分,所以不要认为数据有问题哦。
"movie_name" "movie_score" "movie_people" "link_title"
"1" "Captain America: Civil War" "7.8" "477,676" "http://www.imdb.com/title/tt3498820/?ref_=adv_li_i"
"2" "Suicide Squad" "6.1" "468,731" "http://www.imdb.com/title/tt1386697/?ref_=adv_li_i"
"3" "Moana" "7.6" "182,533" "http://www.imdb.com/title/tt3521164/?ref_=adv_li_i"
"4" "Deadpool" "8.0" "706,431" "http://www.imdb.com/title/tt1431045/?ref_=adv_li_i"
"5" "Doctor Strange" "7.5" "392,951" "http://www.imdb.com/title/tt1211837/?ref_=adv_li_i"
"6" "10 Cloverfield Lane" "7.2" "230,590" "http://www.imdb.com/title/tt1179933/?ref_=adv_li_i"
"7" "La La Land" "8.1" "357,463" "http://www.imdb.com/title/tt3783958/?ref_=adv_li_i"
"8" "Sing" "7.1" "94,872" "http://www.imdb.com/title/tt3470600/?ref_=adv_li_i"
"9" "Split" "7.3" "254,601" "http://www.imdb.com/title/tt4972582/?ref_=adv_li_i"
"10" "Zootopia" "8.0" "337,554" "http://www.imdb.com/title/tt2948356/?ref_=adv_li_i"
"11" "Moonlight" "7.4" "186,689" "http://www.imdb.com/title/tt4975722/?ref_=adv_li_i"
"12" "X-Men: Apocalypse" "7.0" "312,722" "http://www.imdb.com/title/tt3385516/?ref_=adv_li_i"
分享到这了,想要数据,点击阅读原文,在我的GitHub上下载,走的时候别忘了点个赞。
☞推荐阅读☜
1:基于 TensorFlow 的图像识别(R实现)
2:聚类分析简单介绍(附R对应函数介绍)
3:日期格式那么多,处理起来却贼简单
4:啤酒和尿布的故事是真的吗
5:我把我用R写的第一个爬虫就献给了国家
6:搭建一款属于你自己的图像识别系统。

