最近有个朋友在找工作,正好之前11月参加了天善社区的培训,于是尝试下用python爬取拉勾网的招聘信息。
数据的爬取:
1、在拉勾网选关键词查询,经过分析发现关键词源码页面都在https://www.lagou.com/zhaopin/xxxx上
2、从源码页面提取需要的内容,经过测试发现使用了五十多个代理和二十多个浏览器的header最多也只能爬取5页,觉得拉勾网的防爬机制的确恶心
3、不想使用自己账号,于是在网上copy别人的cookies,然而发现这样也只能爬取六七十页二级页面(职业的详细要求),猜测拉勾网在某段时间内爬取页面数量有限制
4、在每一次爬取中加入休眠机制,程序挂着跑一晚上终于成功
代码具体如下(代码有点乱,没经过精简,见谅哈):
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import pandas as pd
import re
import random
name=[]
city=[]
times=[]
work_time=[]
money=[]
key=[]
attract=[]
company=[]
industry=[]
info=[]
for x in range(1,31):
ua=UserAgent()
headers1={'User-Agent': 'ua.random'}#使用随机header,模拟人类
cookiess = {'JSESSIONID': '99021FFD6F8EC6B6CD209754427DEA93','_gat': '1', 'user_trace_token': '20170203041008-9835aec2-e983-11e6-8a36-525400f775ce', 'PRE_UTM': '', 'PRE_HOST': '', 'PRE_SITE': '', 'PRE_LAND': 'https%3A%2F%2Fwww.lagou.com%2Fzhaopin%2F','LGUID': '20170203041008-9835b1c9-e983-11e6-8a36-525400f775ce', 'SEARCH_ID': 'bfed7faa3a0244cc8dc1bb361f0e8e35', 'Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1486066203', 'Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1486066567', '_ga': 'GA1.2.2003702965.1486066203', 'LGSID': '20170203041008-9835b03a-e983-11e6-8a36-525400f775ce', 'LGRID': '20170203041612-714b1ea3-e984-11e6-8a36-525400f775ce'}
url='https://www.lagou.com/zhaopin/shijuesheji/'+str(x)
r = requests.get(url,headers=headers1).text
soup = BeautifulSoup(r,'html.parser')
url_two=re.findall('<a class="position_link" href="https://ask.hellobi.com/(.*?)" target="_blank"',r, re.S) #二级界面的网址
for i in range(len(url_two)-1): #爬取二级页面关于职位的描述
print("第"+str(x)+"页第"+str(i)+"个职位")
new_proxy=['112.114.76.176:6668','222.172.239.69:6666','112.114.78.54:6673','121.31.103.33:6666','110.73.30.246:6666','113.121.245.32:6667','114.239.253.38:6666','116.28.106.165:6666','220.179.214.77:6666','110.73.32.7:6666','118.80.181.186:6675','60.211.17.10:6675','110.72.20.245:6673','114.139.48.8:6668','111.124.231.101:6668','110.73.33.207:6673','113.122.42.161:6675','122.89.138.20:6675','61.138.104.30:1080','121.31.199.91:6675','218.56.132.156:8080','218.56.132.156:8080','220.249.185.178:9999','60.190.96.190:808','121.31.196.109:8123','121.31.196.109:8123','61.135.217.7:80','61.135.217.7:80','61.155.164.109:3128','61.155.164.109:3128','61.155.164.110:3128','124.89.33.75:9999','124.89.33.75:9999','113.200.214.164:9999','113.200.214.164:9999','119.90.63.3:3128','112.250.65.222:53281','112.250.65.222:53281','222.222.169.60:53281','122.136.212.132:53281','122.136.212.132:53281','58.243.50.184:53281','58.243.50.184:53281','125.66.140.27:53281','125.66.140.27:53281','139.224.24.26:8888','139.224.24.26:8888']
new_proxy={'http':random.choice(new_proxy)}
headers2={'User-Agent': 'ua.random'}
new_url='{}'.format(url_two[i])
cookiess = {'JSESSIONID': '99021FFD6F8EC6B6CD209754427DEA93','_gat': '1', 'user_trace_token': '20170203041008-9835aec2-e983-11e6-8a36-525400f775ce', 'PRE_UTM': '', 'PRE_HOST': '', 'PRE_SITE': '', 'PRE_LAND': 'https%3A%2F%2Fwww.lagou.com%2Fzhaopin%2F','LGUID': '20170203041008-9835b1c9-e983-11e6-8a36-525400f775ce', 'SEARCH_ID': 'bfed7faa3a0244cc8dc1bb361f0e8e35', 'Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1486066203', 'Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1486066567', '_ga': 'GA1.2.2003702965.1486066203', 'LGSID': '20170203041008-9835b03a-e983-11e6-8a36-525400f775ce', 'LGRID': '20170203041612-714b1ea3-e984-11e6-8a36-525400f775ce'}
r1 = requests.get(new_url,headers=headers2,cookies=cookiess,proxies=new_proxy).text
soup1 = BeautifulSoup(r1,'html.parser')
s9=soup1.select('.job_bt p') #关于职位的描述
c=''
for j in s9:
d=j.text.strip().replace(' ','')
print(d)
c+=d+''
info.append(c)
import time
ts=random.randrange(1,120)
print("==========休息"+str(ts)+"秒============================")
time.sleep(ts)
s= soup.select('.position_link h3')
for i in s:
name.append(i.text)
s1=soup.select('.add em')
for i in s1:
city.append(i.text)
print(city)
s2=soup.select('.format-time')
for i in s2:
times.append(i.text)
s3=soup.select('.money')
for i in s3:
money.append(i.text)
s4=soup.select('.p_bot')
work_key=[]
for i in s4:
work_key.append(i.text.replace('\n','').strip())
for i in work_key:
index=i.index("经")
work_time.append(i[index:len(i)])
s5=soup.select('.company_name a')
for i in s5:
company.append(i.text)
s6=soup.select('.industry')
for i in s6:
industry.append(i.text.replace(' ','').strip())
s7=soup.select('.li_b_l')
key1=[]
for i in s7:
key1.append(i.text.strip().replace(' ','').replace('\n','/'))
for i in range(len(key1)):
if i%2!=0:
key.append(key1[i])
s8=soup.select('.li_b_r')
for i in s8:
attract.append(i.text.replace('“','').replace('”',''))
print(len(name),len(city),len(times),len(money),len(work_time),len(company),len(industry),len(key),len(attract),len(info))
data1=[]
for i in range(len(name)):
a=name[i],city[i],times[i],money[i],work_time[i],company[i],industry[i],key[i],attract[i],info[i]
data1.append(a)
data=pd.DataFrame(data1)
data.columns=['职位名称','城市','发布时间','薪水','工作年限','公司','行业','关键词','职位诱惑','职位描述及要求']
data
data.to_csv(r"C:\Users\Administrator\Desktop\lagou.csv") #职位的描述有些乱码,用gbk编码不成功,只能用utf-8
总共爬取到229个职位,结果如下:
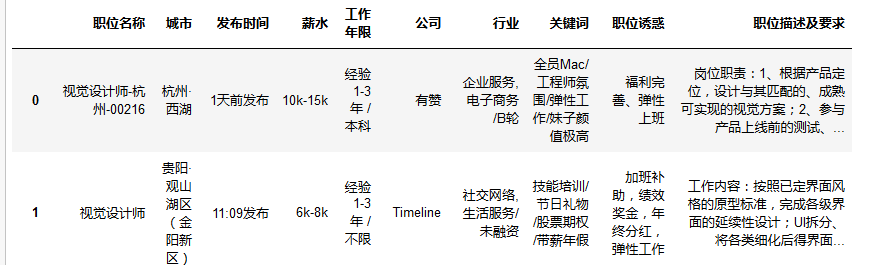
数据分析:
1、查看关于职位描述的能力要求
使用正则去掉中文,然后再清洗数据
for i in data["职位描述及要求"]:
a_req=re.findall("[A-Za-z]+[0-9][A-Za-z]+|[A-Za-z][0-9]+|[A-Za-z]+|[0-9][A-Za-z]",i,re.S)
print(a_req)

然后对所有的网页提取出任职要求的关键词,再进行排序,选取出现频率最高的十五个软件要求,再用Dash实现:
import dash
import dash_core_components as dcc
import dash_html_components as html
from collections import Counter
able=[]
for i in data["职位描述及要求"]:
a_req=re.findall("[A-Za-z]+[0-9][A-Za-z]+|[A-Za-z][0-9]+|[A-Za-z]+|[0-9][A-Za-z]",i,re.S)
#print(a_req)
for j in a_req:
able.append(j.replace('app','APP').replace('photoshop','Photoshop').replace('illustrator','Illustrator').replace('PS','Photoshop').replace('PS','Photoshop'))
kk=dict(Counter(able)) #统计所有软件要求出现次数
pic=sorted(kk.items(),key=lambda x:x[1],reverse=True)
name=[]
num=[]
for i in pic:
name.append(i[0])
num.append(i[1])
a1=name[0:15]#排名前十五名用Dash表示
a2=num[0:15]
app = dash.Dash()
new_data=[]
for i in range(len(a1)):
a={'x':[a1[i]], 'y':[a2[i]], 'type': 'bar', 'name': a1[i]}
new_data.append(a) #要求的软件 及描述出现次数
app.layout =dcc.Graph(id='graph', # 图形的具体内容
figure={
'data': new_data
}
)
if __name__ == '__main__':
app.run_server(host='0.0.0.0',port=8586)
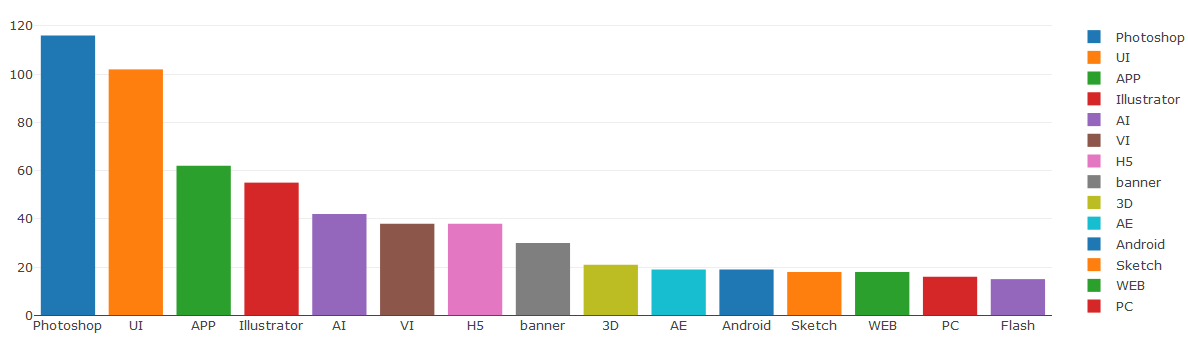
发现目前视觉设计大部分工作要求使用PS和UI,无语的是查看数据时候有些工作竟然要求会用web和JavaScript,看来现在一些工作对能力要求越来越高
2、看看对工作经验和学历的要求
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
mpl.rcParams['axes.unicode_minus'] = False
%matplotlib inline
print(data["工作年限"].value_counts().head()) #工作年限和学历要求
data["工作年限"].value_counts().plot(kind="pie",figsize=[6,6],counterclock=True,startangle=0,legend=False,title="经验要求")

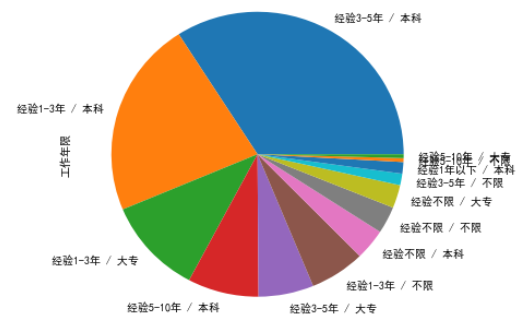
工作对学历和经验的大部分要求是工作1-3年和3-5年,学历基本都要求本科,看来有个本科学历还是挺重要的
3、再看看不同地域薪水的分布情况
先看看全国工资平均值上限和下限:
xs_min=[]
xs_max=[]
for i in data["薪水"]:
p=i.replace("k","").replace("K","")
b=p.index('-')
xs_min.append(int(p[0:b]))
xs_max.append(int(p[b+1:len(p)]))
a1=0
a2=0
for i in xs_min:
a1+=int(i)
print(a1/len(xs_min))
for i in xs_max:
a2+=int(i)
print(a2/len(xs_max))
city1=[]
for i in data["城市"]:
# print(i[0:2])
city1.append(i[0:2])
for i in range(135,len(city1)):
city1[i]="上海"
hh=[list(i) for i in zip(city1,xs_min,xs_max)]
new_data=pd.DataFrame(hh)
k1=new_data[1].groupby(new_data[0]).mean() #下限平均值
k2=new_data[2].groupby(new_data[0]).mean() #上线平均值
result = pd.concat([k1, k2], axis=1)
result.columns=['下限','上限']
result=result.sort_values(["下限"], ascending = False) #按下限排序
for i in range(0,10):
print(result.index[i],round(result['下限'][i],1),round(result['上限'][i],1))
app = dash.Dash()
app.layout =dcc.Graph(id='graph',
# 图形的具体内容
figure={
'data': [{'x':result.index[0:15], 'y':result['下限'][0:15], 'type': 'bar', 'name': "工资平均值下限"},
{'x':result.index[0:15], 'y':result['上限'][0:15], 'type': 'bar', 'name': "工资平均值上限"}]
}
)
if __name__ == '__main__':
app.run_server(host='0.0.0.0',port=8585)
统计的时候发现在229个职位中仅有45个职位分布在全国,其它的都是上海的工作,而且所有城市类型才11类,,这样数据不均衡可能有点偏差,于是再次爬取试试
第二次爬取有225个职位,其中分布在全国的工作有135个,看看详细的情况:
全国薪水均值区间:
9.6
16.195555555555554
擦,发现全国薪水均值区间在9K-16K之间,感觉还不错呐
再看看每个城市的薪水区间和职位数量:
各个城市分布:
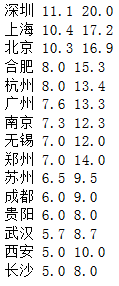
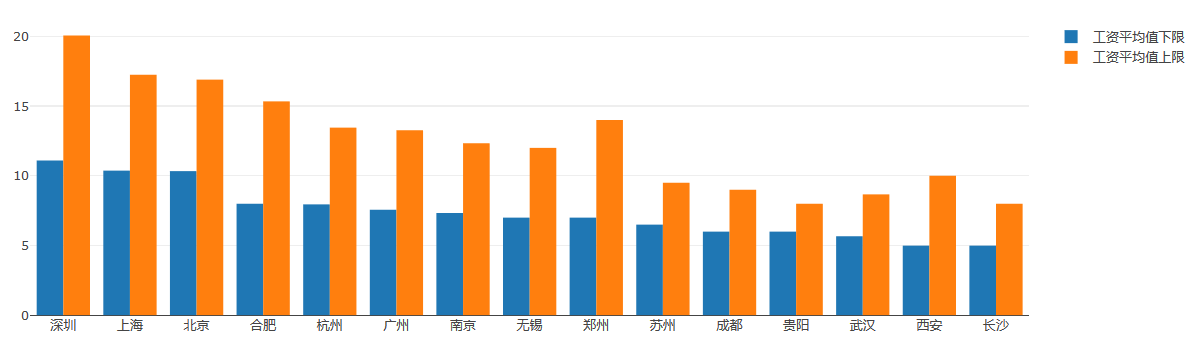
总的来说,不管上限还是下限的薪水,北上广都是在全国前列。
PS:爬取数据的时候发现爬取一定量数据,爬取的地区从全国变成上海的工作,后需再看看是什么原因导致只能爬取上海的工作,这样影响到30页最终只爬取到了16页数据。



