周末参加了一个名叫“程序媛计划”的线下小组活动,学习了如何用python爬取某度公司的招聘页面信息。
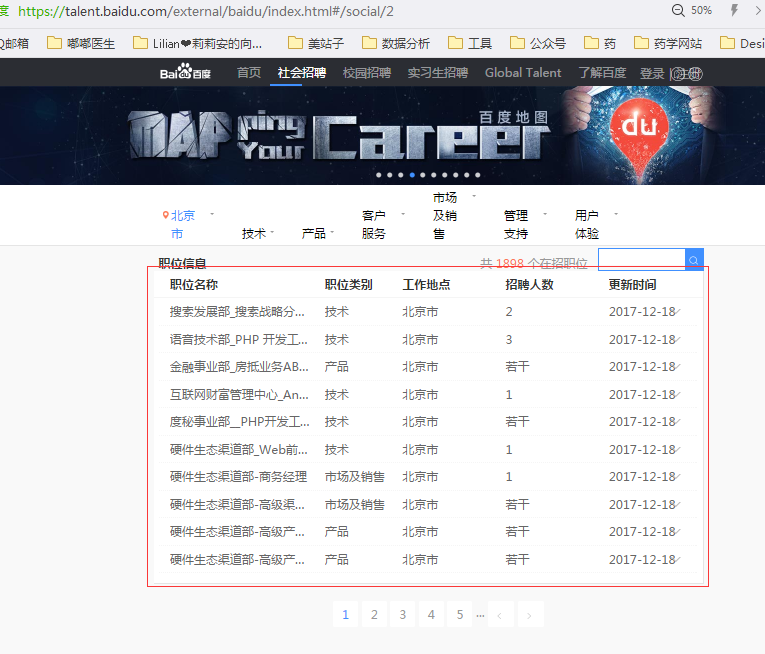
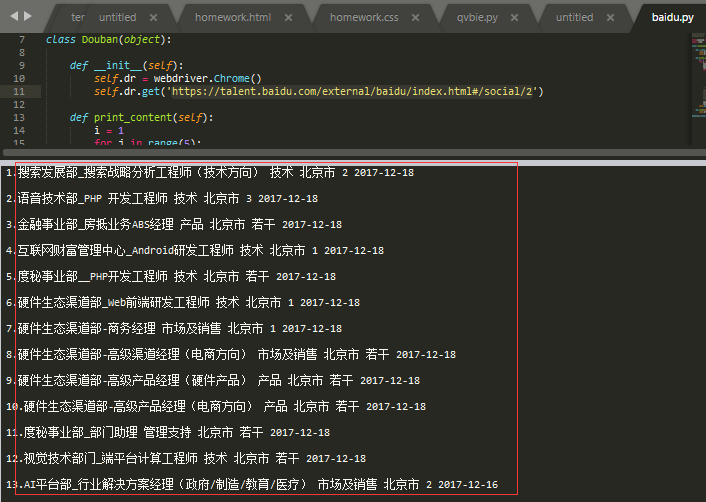
效果就是这样,目前还没有学到如何把这些数据存放起来。我想之后在秦老师这边学了数据库,就可以操作了吧。
回家后复习了一下,练习在某疼的招聘页面爬取信息,整理了一下写代码的过程,一方面是自己记录一下,另一方面也想和大家一起分享~
(如果你是程序大佬,围观一下就好了,不要嘲笑我这个小小白呀~如果我有哪里说错了,恳请帮忙指正!)
建议先了解一下基础的html语言和python语言,html只要知道有标签<></>这种东西,网页大概是怎么排布的就ok了,python的话按秦老师的课程,学到“第三方包”这一节就差不多了。
也可以在廖雪峰老师或w3school上了解。
首先你要有python和Sublime(直接在Jupyter Notebook也阔以哦~),并且要有Chromedriver插件。
程序和环境变量
https://ask.hellobi.com/blog/toughsummer/10834
包和chrome插件
https://ask.hellobi.com/blog/toughsummer/10740
做好准备工作,我们开工啦!(搓手)
#!/usr/bin/env python
#coding:utf-8
首先输入灰色的两行。这是每个py文件前面都要加的“声明”,复制一下就好啦。
然后是加载包。你可以把包当成python的插件(反正现阶段我是这么理解的……),用到什么功能,就加载相应的包。
from selenium import webdriver
import time
from……import……和import……都是加载包的语句。关于这两个句子的区别,知乎上有个回答很形象,可以戳链接了解一下:
https://www.zhihu.com/question/38857862/answer/90981260
第一句的selenium包,准确来说是一个python实现自动化操作的包。自动化操作就是,告诉电脑该干嘛,让你的电脑自己干。比如自己开个软件,自己关掉窗口,当然也包括自己打开网页并且把网页上的内容摘下来。所以我们可以用selenium包来做爬虫。
能用来做爬虫的包有很多,天善的视频课程里有个免费爬虫课用的beautifulsoup,也很好。但是它操作很快,有时候会被对方发现是机器人,从而被禁掉。所以我们一开始还是用selenium入门学习比较好。
Webdriver就是selenium包里的一个类,用来进行网页相关操作。
载入以后,我们第一步是让电脑认识浏览器,打开网页。
dr = webdriver.Chrome()
dr.get("http://hr.tencent.com/position.php?keywords=&lid=0&tid=87&start=0#a")
我们用了一个变量dr,用chrome方法让它打开chrome。注意chrome的C要大写。
然后我们用get方法让dr访问招聘网页的地址,就是某疼社招技术岗页面。
代码先写到这里,下一步我们来分析一下页面上的内容。
我们自己用chrome浏览器打开这个网页,看到页面是这样的。
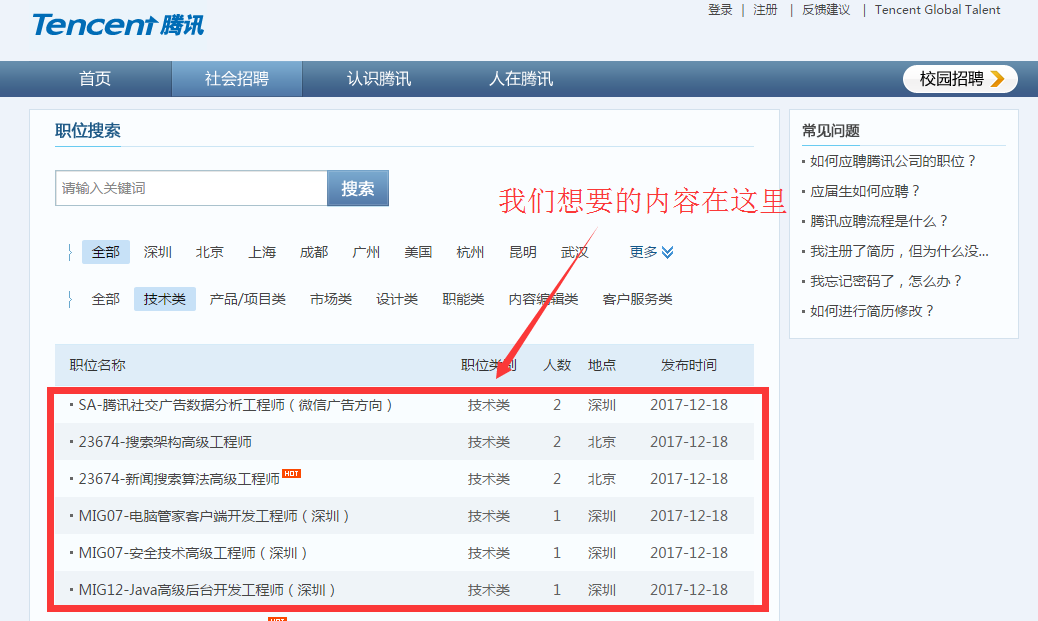
怎么让程序看到这一部分的内容,并抓到它呢?
我们按F12(右键-检查也可以),用开发者模式看一看它的代码。
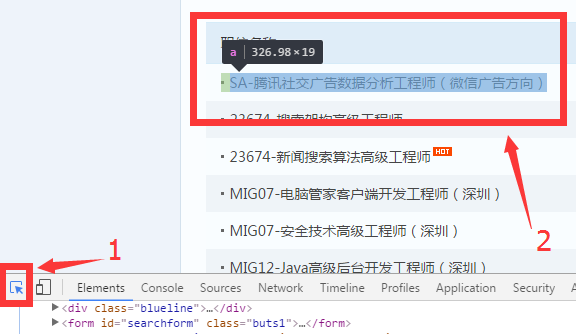
点“1”这个小鼠标,再把鼠标移到网页上我们要找的内容,发现文字的底色改变了。
这个功能就是用来定位网页上的元素,找到对应的代码。
点一下变色的内容,发现下面的代码也跳转到了对应位置。
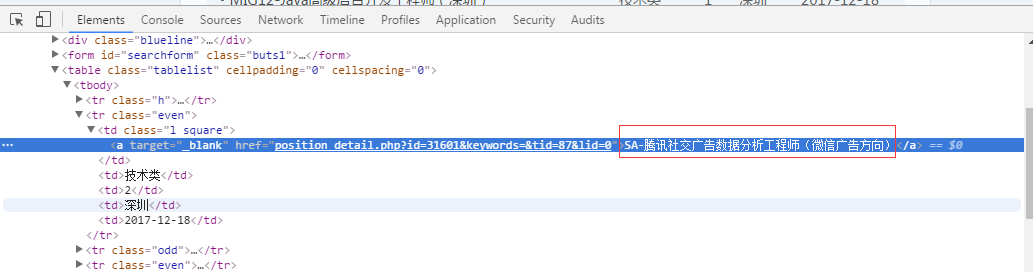
我们把鼠标在这附近移动,看到对应元素的变化。
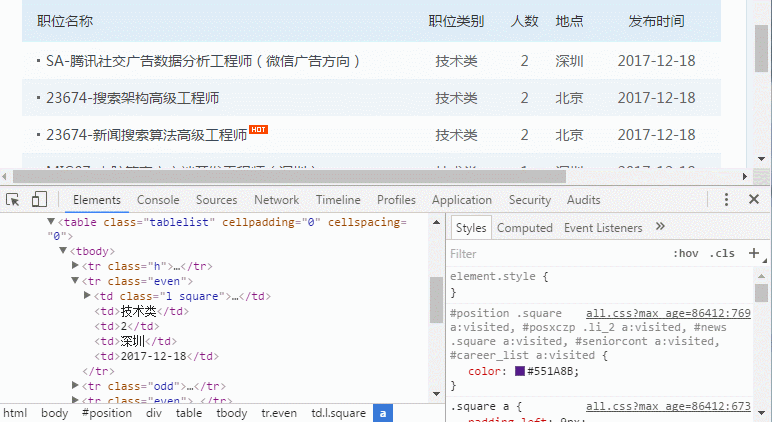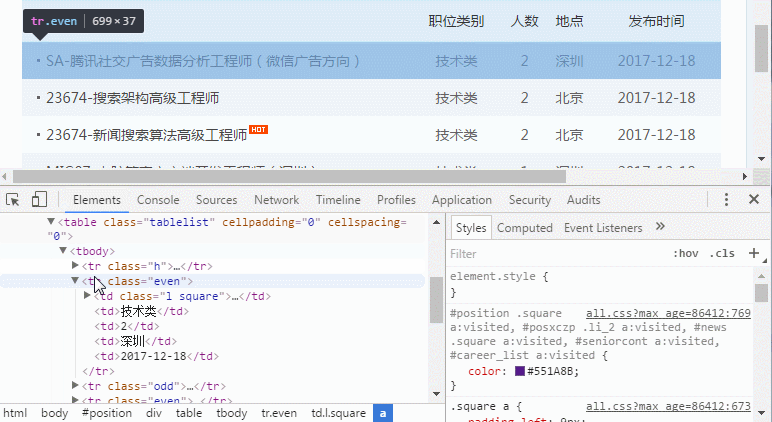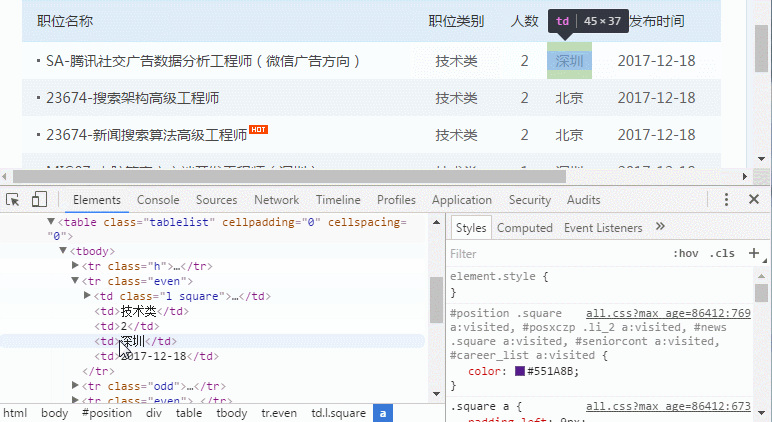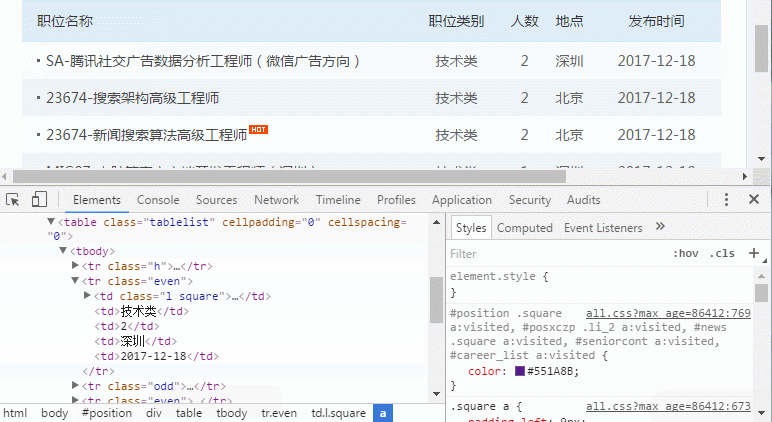
可以看到,这块其实是个表格,每个”<tr></tr>”标签都是一行,class名为“h”的行是标题行,class名为even的是奇数行,odd是偶数行。
一开始看到这个奇偶数,非常生气!为什么它要把行弄得不一样呢!如果每行同一个名字,我一句话就可以找到它,可偏偏不同!
后来仔细看了一下页面,发现奇数行是白底,偶数行是蓝底,看来是为了表格更美观而设计的。那没办法,我们只好后面稍微辛苦一点了。
接下来我们就定位到相应的元素去。
写代码:
time.sleep(3)
main_content =dr.find_element_by_class_name("tablelist")
evens =main_content.find_elements_by_class_name("even")
我们先让程序停顿3秒,给网页一点时间加载出来。
接着用main_content这个变量获取网页中class名为“tablelist”的元素。
Evens则是名为“even”的元素们。
要注意,因为每一个奇数行都叫“even”,所以我们要find_elements_by_class_name,这一步得到的结果也是多个元素,所以evens是一个list列表,里面存了好多个元素。
然后我们要从evens里的每个元素中,提取到每一列的对应信息。
所以先写个for循环,遍历evens里的每个even
for even in evens:
接着我们发现,
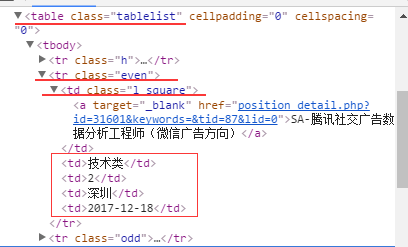
后面四列很好弄,就是单元格里的纯字符串或数值而已,第一列的话有个超链接,看起来非常复杂。Ok,那我们先搞下面的。
但问题来了,现在没有class或者id了,咋办捏。没事,我们还有个by xpath方法。
Xpath就是<*></*>的这个*,很好理解的。
代码如下:
tds= even.find_elements_by_xpath("td")
career_position= tds[1].text
career_num= tds[2].text
career_city= tds[3].text
career_time= tds[4].text
(.text是获得元素的文本信息的方法,就是会把<**>??</**>里的??拿出来)
好了,后面四个信息都拿到了。
其实第一个也拿到了,因为第一列就是第一个td元素,所以存放在td[0]里面。那么我们只要在td[0]里面,用xpath再找到下面的<a……></a>,然后取出里面的文本就可以了。
career_name= tds[0].find_element_by_xpath("a").text
最后打印
print(career_name,'',career_position,' ',career_num,' ',career_city,' ',career_time,'\n')
好了我们来试一下:
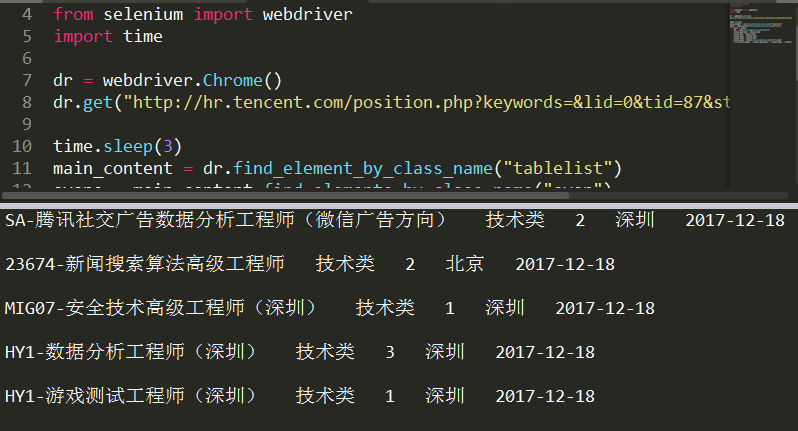
心情愉悦!!
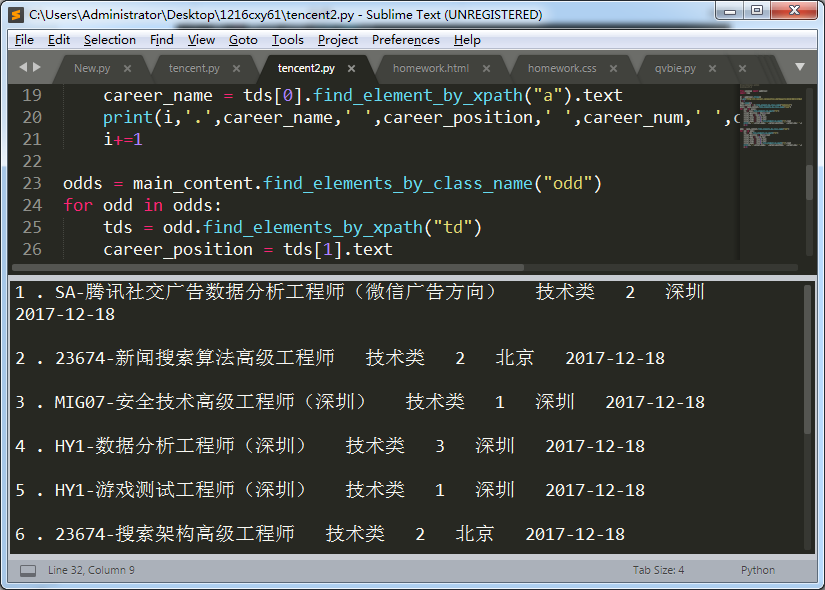
接着加上序号,再把odd行也抓下来~
大家可以自己试着写一写odd行的抓取代码,其实一样的哦~我就不重复了。还可以给它们加上编号:
接着我们学怎么翻页。类似的,找到翻页的按钮
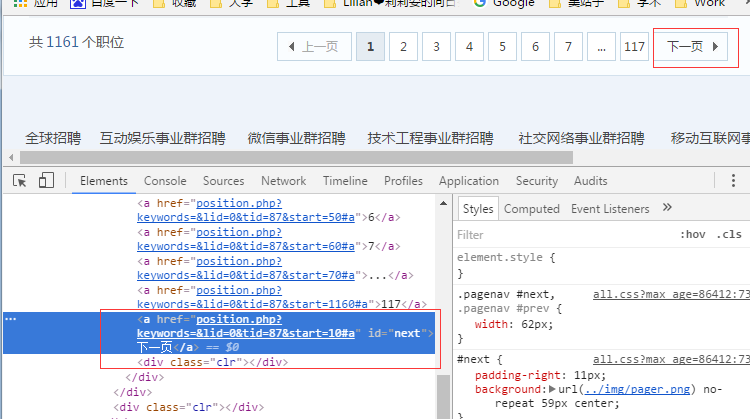
哟!发现它有个id属性!id是最开心的,因为每个网页上元素的id必须唯一,不用担心有重复值。我们通过next这个id定位到按钮,然后用click()方法点击它就可以啦。
next_bottom =main_content.find_element_by_id("next")
next_bottom.click()
那点击之后,就是套一个循环,让程序在每一页里自动点击了。
好啦,这个程序就写完啦,你还可以把它整合成类和方法。我对类和方法还不怎么懂,还在学习中,只会照着老师的程序改,所以就不瞎说了。
放一下整合前的代码和整合后的代码,都只抓取前5页信息。
看到最后的你辛苦了!希望对你有所帮助!我们一起学习呀!!
(PS:打个广告,如果你也是想成为程序媛的女生,加入程序媛计划吧~是真心推荐的,木有广告费TAT)

