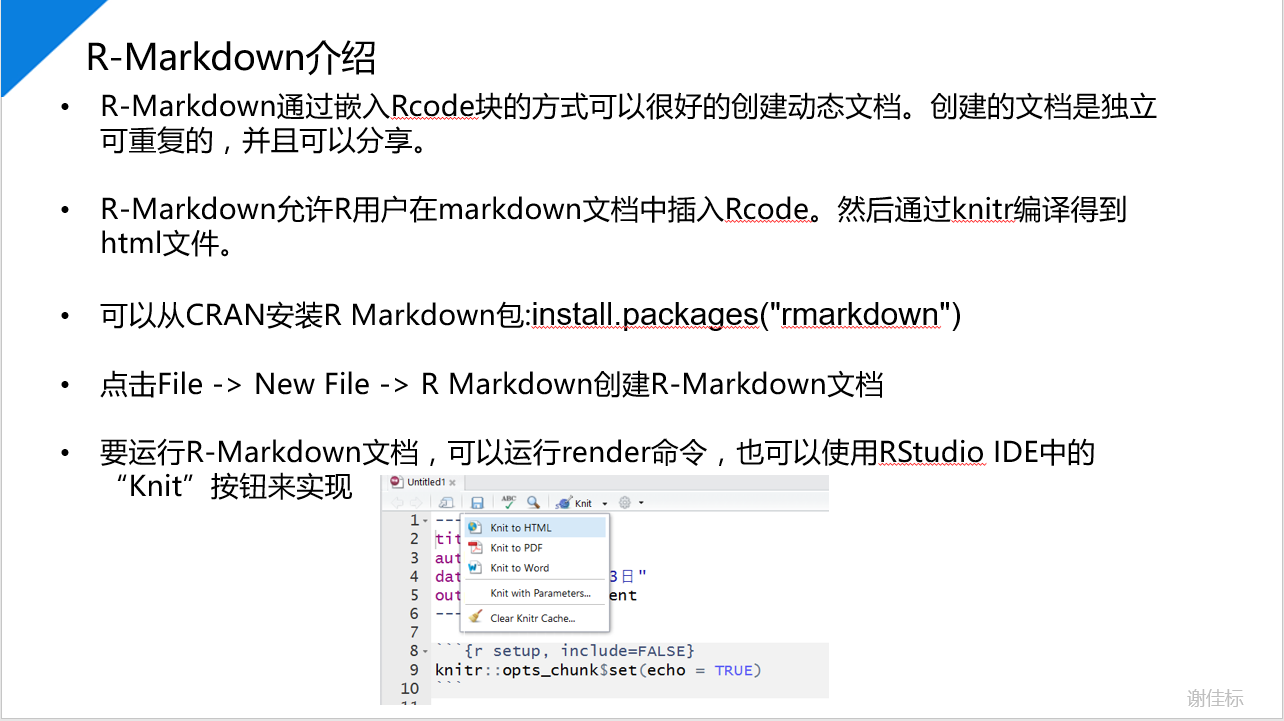

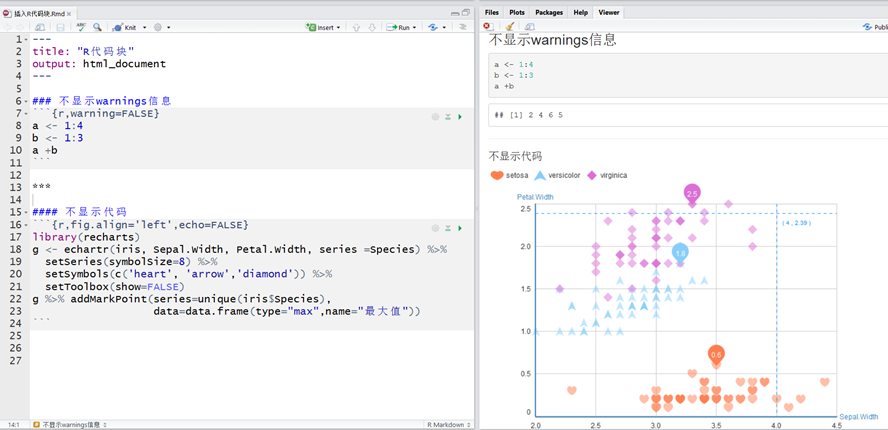
插入R代码样例展示:
---
title: "R代码块"
output: html_document
---
### 不显示warnings信息
```{r,warning=FALSE}
a <- 1:4
b <- 1:3
a +b
```
***
#### 不显示代码
```{r,fig.align='left',echo=FALSE}
library(recharts)
g <- echartr(iris, Sepal.Width, Petal.Width, series =Species) %>%
setSeries(symbolSize=8) %>%
setSymbols(c('heart', 'arrow','diamond')) %>%
setToolbox(show=FALSE)
g %>% addMarkPoint(series=unique(iris$Species),
data=data.frame(type="max",name="最大值"))
```
•Rmarkdown通常以html、word、pdf格式输出,但是也可实现slidy输出。只需将output设置为“slidy_presentation” 即可。
---
title: "Presentations with Slidy"
author: "Daniel xie"
date: "November 14, 2017"
output:
slidy_presentation:
incremental: yes
---
#### 使用 Markdown 的优点
- 专注你的文字内容而不是排版样式。
- 轻松的导出 HTML、PDF 和本身的 .md 文件。
- 纯文本内容,兼容所有的文本编辑器与字处理软件。
- 可读,直观。
- 适合所有人的写作语言。
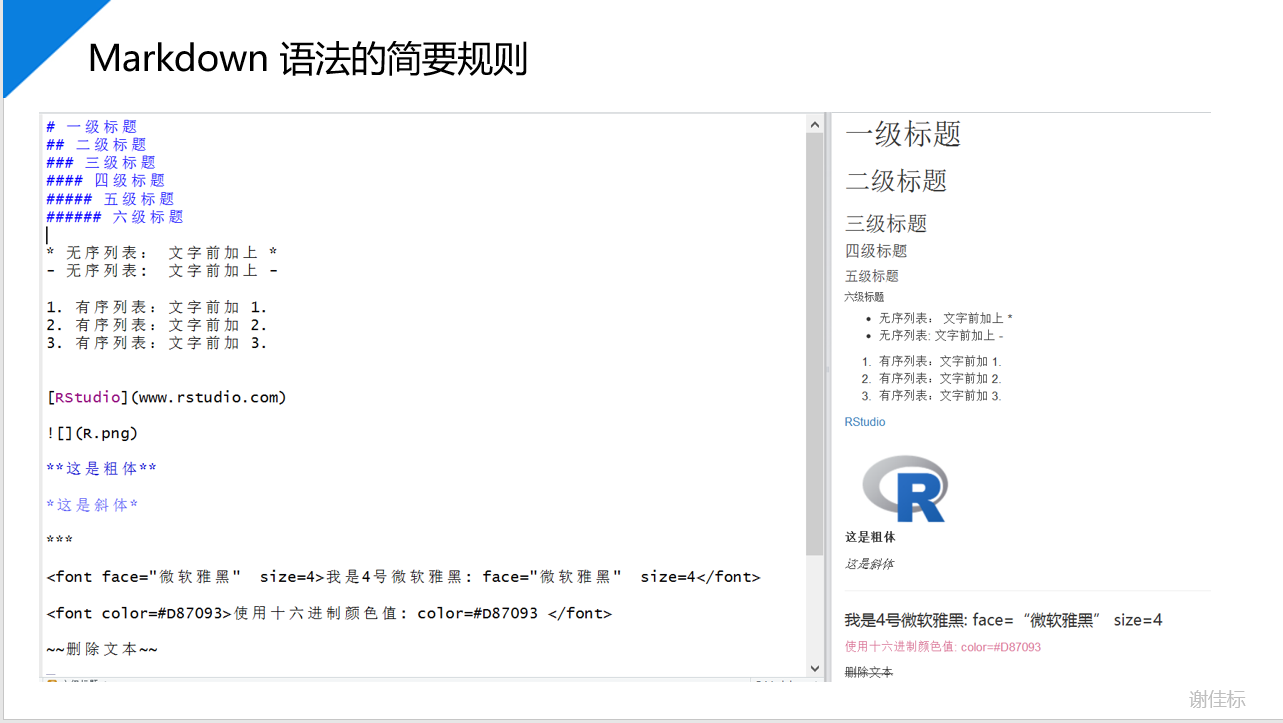
#### RMarkdown简要语法
[RStudio](www.rstudio.com)

**这是粗体**
*这是斜体*
<font color=#D87093>使用十六进制颜色值: color=#D87093 </font>
~~删除文本~~
#### 插入表格
```{r}
library(DT)
datatable(iris)
```
#### 输出模型结果
```{r}
fit <-lm(women)
summary(fit)
```
#### 打印图形
```{r,fig.align='center'}
par(mfrow=c(2,2))
plot(fit)
par(mfrow=c(1,1))
```
#### 交互可视化
```{r}
library(rpivotTable)
rpivotTable(mtcars)
```
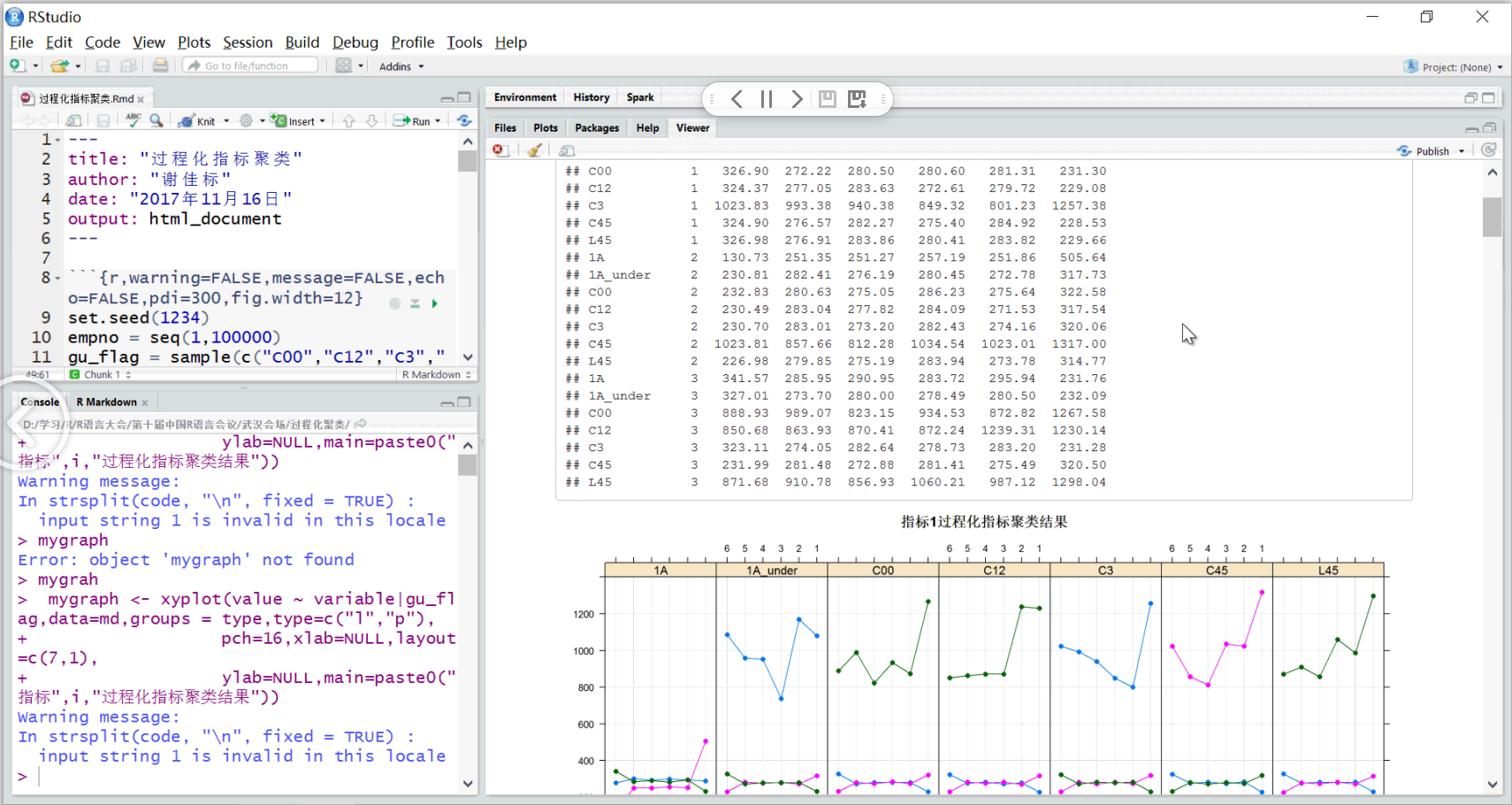
实例:构建自动化报表
•Rmarkdown最大的优势是可以制作自动化报表,将人从繁琐的重复性工作中解放出来,更专注创造性的工作。
•头有这样的需求,针对大量的指标,需要对每个指标的时间序列进行研究,且需要区分不同的用户群,此时用rmarkdown来构建报表是最适宜的。
•模拟一份数据集,一共有10万个业务员,有10个过程指标(共60个字段),且业务员分为7种不同的类型:
•构建衡量时间序列的指标:波动性和幅度(利用差分和均值进行组合构建)
•然后利用衍生指标,分别对每个人群建立K均值聚类,查看不同组别的业务员在最近6个月的变化趋势,找出规律
•对于聚类结果,根据不同组别的簇中心,进行可视化展示。
---
title: "过程化指标聚类"
author: "谢佳标"
date: "2017年11月16日"
output: html_document
---
```{r,warning=FALSE,message=FALSE,echo=FALSE,pdi=300,fig.width=12}
set.seed(1234)
empno = seq(1,100000)
gu_flag = sample(c("C00","C12","C3","C45","L45","1A_under","1A"),100000,replace = T)
dat <- matrix(sample(c(1,2,3,50:500,1000,2000,5000),100000*60,replace = T),100000,60)
customer <- data.frame(empno,gu_flag,dat)
for(n in 1:10){
customer_new <- customer[,c(1,2,(6*n-3):(6*n+2))]
# 计算差分
customer_diff1 <- t(apply(customer_new[,c(-1,-2)],1,diff))
# 增加实际值均值、(差分/上月)均值和差分为正的个数
customer_data1 <- data.frame(empno = customer_new$empno,
gu_flag = customer_new$gu_flag,
mean = rowMeans(customer_new[,3:8],na.rm = T),
diff = rowMeans(customer_diff1/rowMeans(customer_new[,3:7]),na.rm = T),
positive = rowSums(ifelse(customer_diff1 > 0,1,0)))
# 将diff变量中的-Inf与Inf、NA设置为0
customer_data1$diff <- ifelse(is.infinite(customer_data1$diff),0,customer_data1$diff)
customer_data1$diff <- ifelse(is.na(customer_data1$diff),0,customer_data1$diff)
# 按照gu_flag进行分组、分别建立K均值聚类模型
gu_flag1 <- c("C00","C12","C3","C45","L45","1A_under","1A")
for(i in 1:length(gu_flag1)){
customer_data1_sub1 <- customer_data1[customer_data1$gu_flag==gu_flag1[i],]
set.seed(1234)
km_model <- kmeans(scale(customer_data1_sub1[,3:5]),3)
# 给原始数据打上标签
customer_new[customer_new$gu_flag==gu_flag1[i],'type'] <- km_model$cluster
}
# 按照gu_flag、type进行分组,分别统计最近六个月的平均值(按列求平均值)
customer_sub_mean1 <- data.frame(aggregate(customer_new[,3:8],list(gu_flag=customer_new[,2],type=customer_new[,9]),
FUN=function(x){mean(x,na.rm = T)}))
colnames(customer_sub_mean1)[3:8] <- seq(6,1,-1)
# 展示数据集
print(knitr::kable(customer_sub_mean1,digits = 2,padding=0))
# 绘图
library(reshape)
md <- melt(customer_sub_mean1,id=c("gu_flag","type"))
library(lattice)
mygraph <- xyplot(value ~ variable|gu_flag,data=md,groups = type,type=c("l","p"),
pch=16,xlab=NULL,layout=c(7,1),
ylab=NULL,main=paste0("指标",n,"过程化指标聚类结果"))
print(update(mygraph,
panel = function(...){
panel.grid(h=-1,v=-1)
panel.xyplot(...,border="transparent")
}))
}
```
效果如下: