两天的爬虫线下培训结束了,感谢大伟老师和工作人员们的辛苦付出,以下为本次作业的简述:
一、先处理单页信息的爬取:

输出结果后发现网页被重定向至其他网页,并非需要爬取的排行榜,于是加入代理及异常机制尝试:
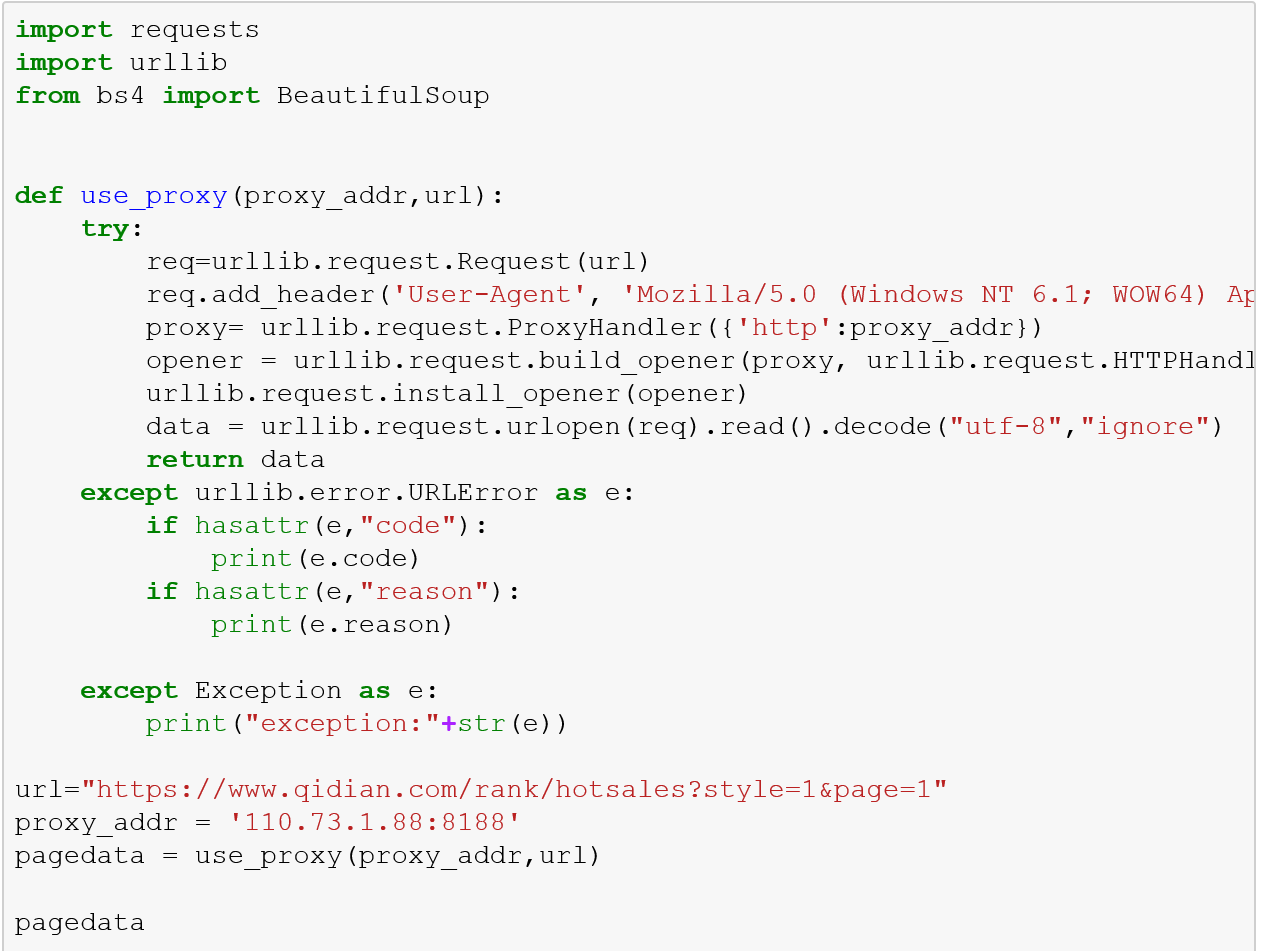
输出结果正常:

接着,加入解析器,通过循环,把需要的信息先放入字典,再将全部信息分类汇总入列表:
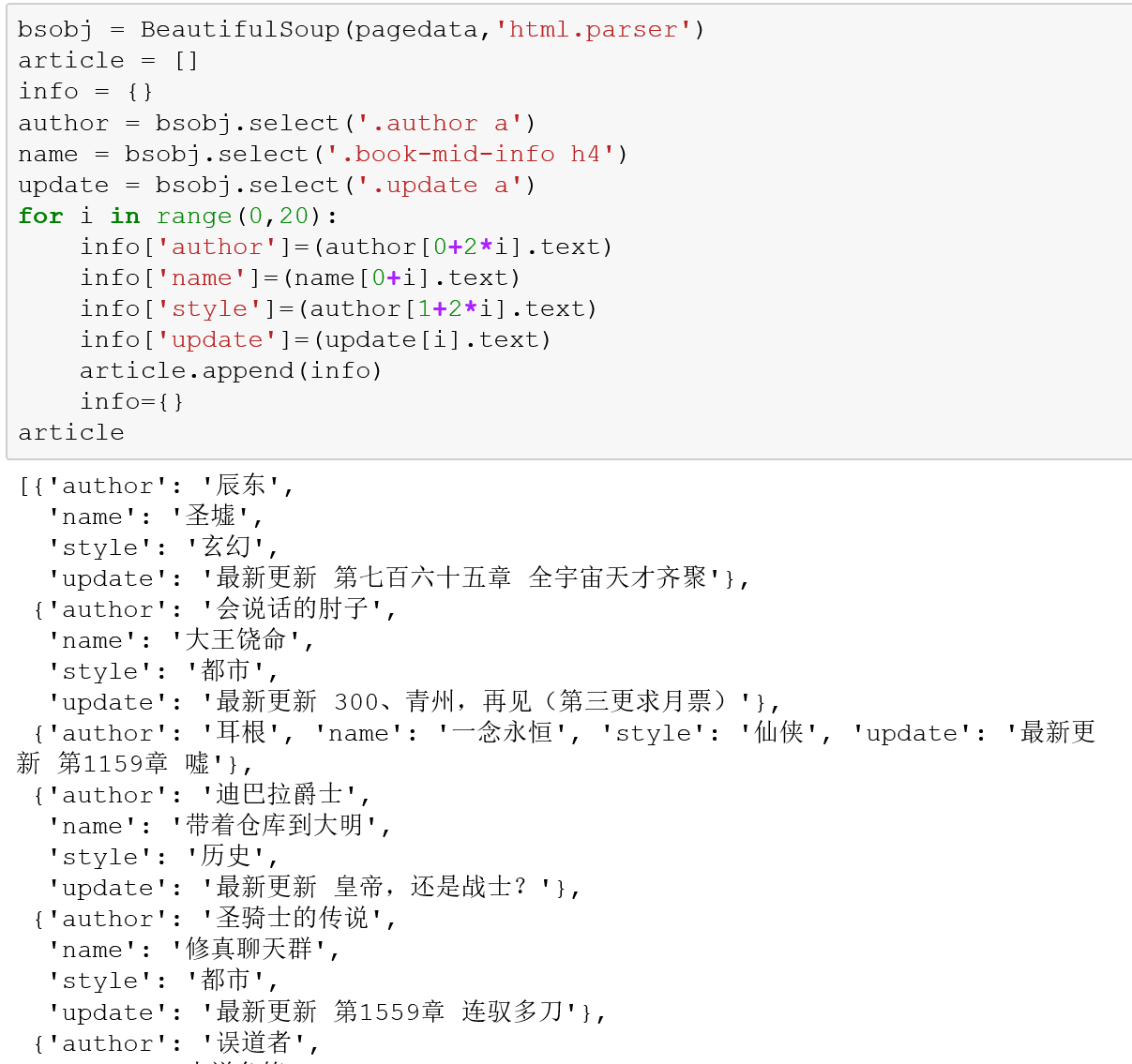
引入pandas,将信息转化为DataFrame:

输出结果第一页所需信息:
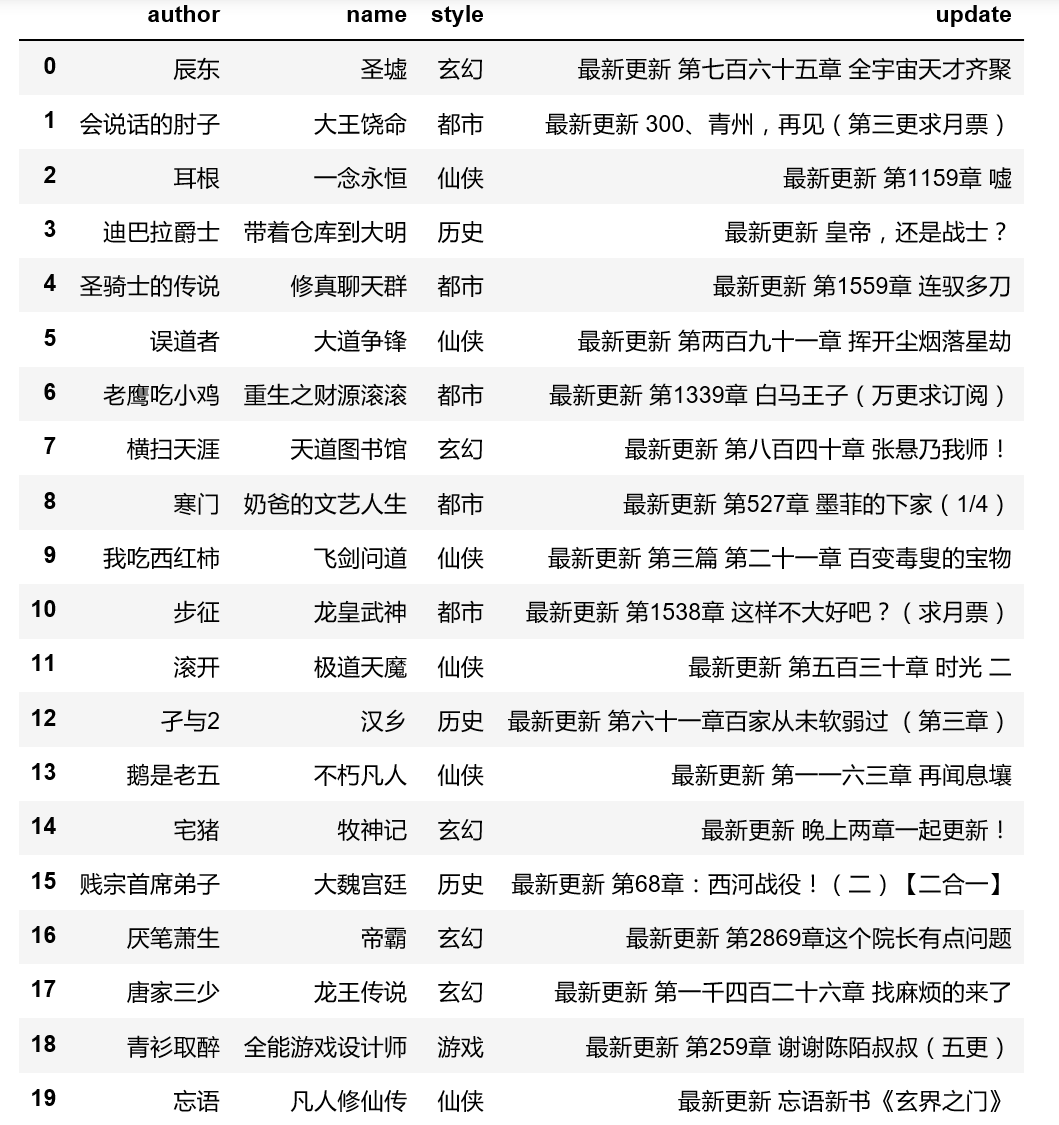
至此,单页爬取完成。
二、爬取前200名的信息:
单页爬取成功,加入循环,实现多页爬取,并输出结果,以下为完整代码:

以下为完整输出结果:
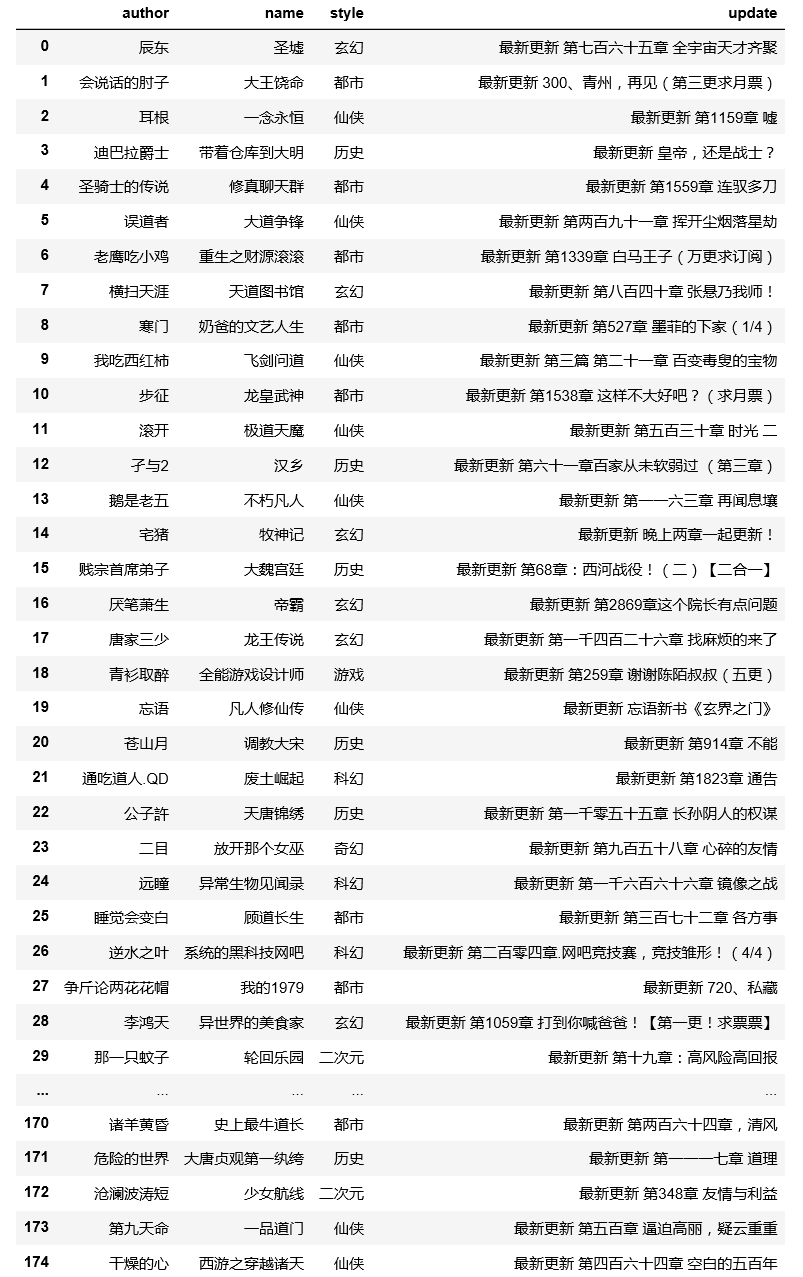
如有发现问题,欢迎各位老师同学的批评指正。
再次感谢大伟老师,各位天善的工作人员及各位同学!





