以下内容来自《R语言游戏数据分析》,将于2017年出版,未经许可,不得转载。在做付费用户深度挖掘时,需要利用不同的算法从不同角度进行研究,当中的数据转换是令人头疼的工作。如果大家对数据转换感兴趣,请关注此书。
11月10日晚八点半视频公开课直播地址:https://edu.hellobi.com/course/117/lessons。
传统行业一直都崇尚“用户是上帝”、“用户中心论”的理念,如今此理念在手游领域同样适用。付费用户又是能给公司直接创造价值的用户群体,属于公司的核心用户,我们需要重点研究,给这批用户群提供VIP服务,延长其在游戏中的生命周期,或者进行精准营销,提高这批用户的ARPPU值。
付费玩家常用的分析方法如下图所示。
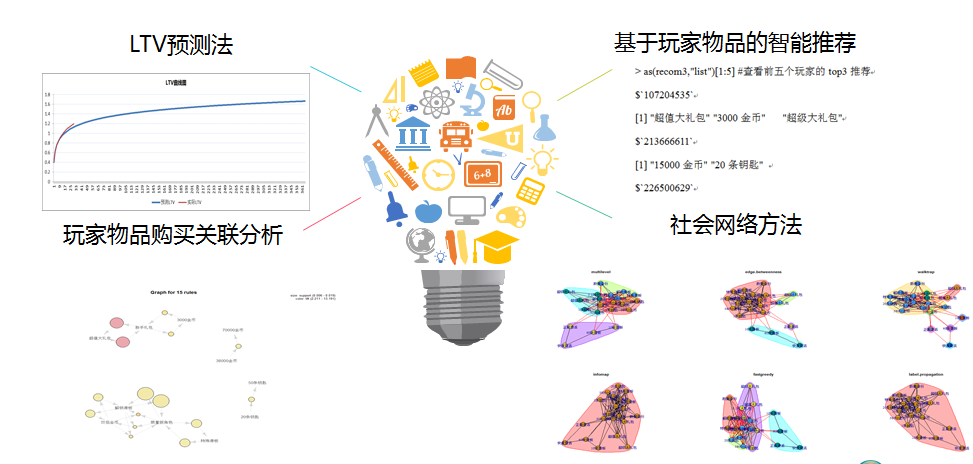
我们可以通过已知的LTV(用户生命周期价值)预测未来的LTV值,从而计算ROI,给市场投放人员在做广告投放时做到有的放矢;通过购物篮分析实现玩家物品购买关联分析;由于关联分析是发现不同物品之间的模式、关联和相关性;不能对每一个用户进行个性化推荐,所以利用智能推荐系统对每一个玩家实现topN商品推荐;还可以利用社会网络图对玩家的购买行为进行分析,发现社群。
接下来,我们就简单来介绍下各种算法在用户消费数据中的使用场景(由于LTV偏向游戏数据,这边就不展开来讲,如果各位看官感兴趣,可以留意《R语言游戏数据分析》一书,这本书将在2017年初出版)。
一、玩家物品购买关联分析
•关联规则是从事务数据库,关系数据库和其他信息存储中大量数据的项集之间发现有趣的、频繁出现的模式、关联和相关性。
•更确切的说,关联规则通过量化的数字描述物品甲的出现对物品乙的出现有多大的影响。
•Apriori算法是最常用也是最经典的挖掘频繁项集的算法,其核心思想是通过连接产生候选项及其支持度然后通过剪枝生成频繁项集,这里频繁项集指的是所有支持度大于最小支持度的项集。可以从支持度(Support)、置信度(Confidence)和提升度(Lift)三个指标来评估关联规则效果。
下面举一个小例子来简单理解下这三个度的计算:假设共有1000人购买了物品(事务集W),其中购买了5000金币的有100人,购买了8000金币的有150人,同时购买了5000金币和8000金币的有80人。

apriori算法在R中用apriori函数实现。
apriori(data, parameter = NULL,appearance = NULL, control = NULL),其中 parameter=list(supp=0.1,conf=0.8,maxlen=10,minlen=1,target=”rules”)
此外,还有很多有用的函数,比如说通过inspect函数查看事务型数据或者生成的关联规则,利用sort函数对规则进行排序,利用subset函数对关联规则子集进行提取,利用as函数将其他类型数据转换成事务型,利用itemFrequncyPlot函数对商品交易比例绘制柱状图,利用arulesViz包的plot函数对关联规则进行可视化展示。
假如手头现在有一份关于道具销售的数据,格式如下:
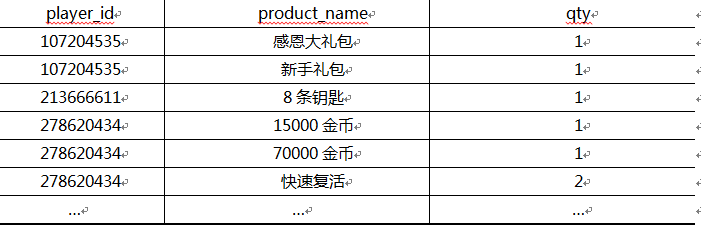
我们需要将此数据导入到R中,并对数据进行重组
> data <- read.csv("玩家购物数据.csv",T)
> # 利用cast函数对数据进行重组
> library(reshape)
> data_matrix <- cast(data,player_id~product_name)
Using qty as value column. Use the value argument to cast to override this choice
> # 查看前三行五列数据
> data_matrix[1:3,1:5]
player_id 0.1元大礼包 10块滑板 15000金币 15元大礼包
1 107204535 NA NA NA NA
2 213666611 NA NA NA NA
3 226500629 1 NA NA NA
可见,如果该玩家没有购买某一款道具,其用NA表示。接下来,我们需要将NA转化为0,其他数字都转化为1,为事务型数据构建稀疏矩阵。并利用as函数将稀疏矩阵转换成事务型数据,利用inspect查看转换结果。(此处直接给出转换结果)
> # 利用as函数将矩阵转换成事物型
>library(arules)
> data_class<- as(data_matrix_new,"transactions")
>inspect(data_class[1:6]) # 查看前六条交易记录
items transactionID
1 {感恩大礼包,新手礼包} 107204535
2 {8条钥匙} 213666611
3 {0.1元大礼包,8条钥匙,限量版角色}226500629
4 {38000金币,限量版角色,新手礼包} 230329140
5 {50条钥匙} 264162836
6{15000金币,70000金币,快速复活} 278620434
现在可以利用apriori函数建立关联规则,并通过sort函数查看前六条规则,按照lift进行降序排序。
> rules <- apriori(data_class,parameter=list(support=0.005,confidence=0.1,target="rules"))
> # 对规则按照提升度排序,并输出提升度最大的前六条规则
>inspect(sort(rules,by="lift")[1:6])
lhs rhs support confidence lift
6 {超值大礼包} => {新手礼包} 0.015994882 0.9009009 13.190708
7 {新手礼包} => {超值大礼包} 0.015994882 0.2341920 13.190708
50 {双倍金币,限量版角色} => {解锁滑板} 0.005918106 0.3523810 5.737202
48 {解锁滑板,双倍金币} => {限量版角色} 0.005918106 0.4933333 4.213552
49 {解锁滑板,限量版角色} => {双倍金币} 0.005918106 0.3083333 3.524132
8 {3000金币} => {新手礼包} 0.007677543 0.2330097 3.411655
最后,利用arulesViz包的plot函数对关联规则进行可视化展示。
> rules_lift <- subset(rules,subset=lift>2)
> library(arulesViz)
载入需要的程辑包:grid
>plot(rules_lift,method="graph") #绘制关联图形
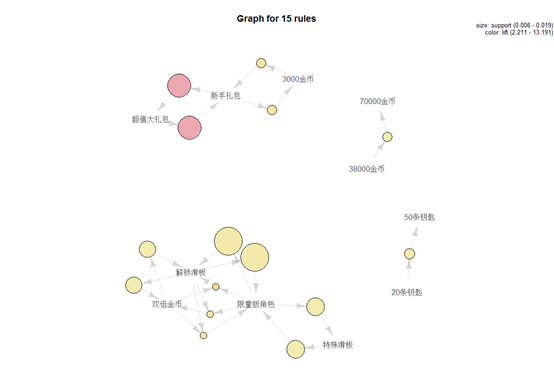
圆圈的大小表示规则的支持度(0.006-0.019),圆圈越大表示支持度越大;圆圈的颜色表示规则的提升度(2.211-13.191),颜色由黄色到粉色表示提升度由小到大;箭头方向表示从lhs => rhs。
二、基于玩家物品的智能推荐
关联规则只能反映一个事物与其他事物之间的关联性,有时候,我们想根据玩家的兴趣特点和购买行为,向玩家推荐他们感兴趣的信息和道具。
智能推荐的方法有很多,包括基于内容推荐、协同过滤推荐、基于规则推荐、基于效用推荐和基于知识推荐。各种推荐算法都有其优缺点。
在R语言中,常使用recommenderlab包中的函数构建和评估智能推荐模型。
Recommender(data, method, parameter=NULL)
其中data为一个ratingMatrix。ratingMatrix有两种:realRatingMatrix和binaryRatingMatrix,realRatingMatrix是一个评分矩阵,以真实的评分数据反映在矩阵中,而binaryRatingMatrix为布尔矩阵,相当于把realRatingMatrix中大于0的数值赋予1。
method的选项包括包括IBCF(基于物品的协同过滤推荐)、UBCF(基于用户的协同过滤推荐)、SVD(矩阵因子化)、PCA(主成分分析)、RANDOM(随机推荐)、POPULAR(基于流行度的推荐)。
predict(object, newdata, n = 10, data=NULL,type="topNList", ...)--预测推荐模型,得到模型的topN列表或者用户的预测评分。
其中object为recommender函数生成的推荐模型;newdata为待预测的数据;n为topN的值,默认为10,表示top10推荐;type的参数有"topNList"、"ratings",当type="topNList"时,predict函数直接返回用户评分最高的前N个item,当type="ratings"时,predict函数预测用户对所有未评分的item打分,返回一个RatingMatrix对象。
现在,需要将关联规则处理好的data_matrix_new转换成binaryRatingMatrix类型,选择IBCF建立推荐模型,对玩家进行top3推荐。
> library(recommenderlab)
> # 将矩阵转化为binaryRatingMatrix对象
> data_class <-as(data_matrix_new,"binaryRatingMatrix")
> as(data_class,"matrix")[1:3,1:5] #显示部分物品购买情
0.1元大礼包 10块滑板 15000金币 15元大礼包 1条钥匙
107204535 FALSE FALSE FALSE FALSE FALSE
213666611 FALSE FALSE FALSE FALSE FALSE
226500629 TRUE FALSE FALSE FALSE FALSE
> #选择IBCF作为最优模型
> model.best<- Recommender(data_class,method="IBCF")
> # 使用precict函数,对玩家进行Top3推荐
> data.predict<- predict(model.best,newdata=data_class,n=5)
> recom3 <-bestN(data.predict,3)
>as(recom3,"list")[1:5] #查看前五个玩家的top3推荐
$`107204535`
[1] "超值大礼包" "3000金币" "超级大礼包"
$`213666611`
[1] "15000金币" "20条钥匙"
$`226500629`
[1] "解锁滑板" "双倍金币" "特殊滑板"
$`230329140`
[1] "超值大礼包" "解锁滑板" "双倍金币"
$`264162836`
[1]"70000金币" "20条钥匙" "15000金币"
三、社会网络分析
社会网络分析(Social Netwrok Analysis,SNA)是在传统的图与网络的理论之上对社会网络数据进行分析的方法。随着人类进入了移动互联网时代,社会网络数据成了重要的数据资源。
•在R中,igraph包是专门用来处理网络图的。使用之前先通过install.packages("igraph")下载安装。
igraph包非常容易创建各种常规图,其中包括无边图(make_empty_graph函数)、星图(make_star函数)、环形图(make_ring函数)、完全图(make_full_graph函数)、树状图(make_tree函数)等图形。
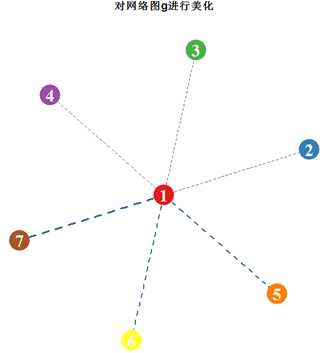
我们还可以通过对社会网络图进行美化。有两种方式。第一种可以用V(g)$parameter="value"来完成点的参数设置;利用E(g)$parameter="value"来完成边的参数设置。第二种方法是直接在plot函数中设置参数,达到美化网络图的目的。例如我们想对网络图g的点和线做一些调整,有两种方法实现。
> library(igraph)
> g <- graph(c(2,1,3,1,4,1,5,1,6,1,7,1),directed = F) #创建无向图g
> # 对网络图g进行美化
> library(RColorBrewer)
> weight <- seq(1,3,length.out=ecount(g)) #生成边的权重
> plot(g,vertex.color=brewer.pal(9,"Set1")[1:vcount(g)],
+ vertex.frame.color=NA,vertex.label.color="white",
+ vertex.label.font=2,vertex.label.cex=2,
+ edge.width=weight,edge.color="steelblue4",edge.lty=2,
+ main="对网络图g进行美化")
当然,我们也可以借助gephi轻松实现社会网络图的制作。下图是一款网游玩家之间的社会网路图。
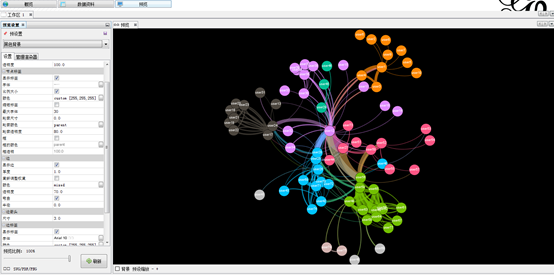
右上角橘色社群紧密围绕在user1周围。
igraph包在社群发现上有比较完善的算法支持,包括社群发现常用的五种算法:点连接、随机游走、自旋玻璃、中间中心度和标签传播等。
我们需要将关联规则时生成的data_matrix_new数据集转换成graph.data.frame函数能识别的格式类型。即以下格式:

然后,我们利用sqldf包中sqldf函数对数据进行统计汇总的工作,根据处理好的数据就能利用igraph包进行社群发现了。
> # 将数据转换为graph.object,并利用多种聚类算法发现社群结构
>library(igraph)
> G <-graph.data.frame(data_count[1:100,],directed = F)
> E(G)$weight<- data_count[1:100,"qty"]
> fc1 <-multilevel.community(G) # 多层次聚类
.......
>par(mfrow=c(2,3))
> for(i in1:6){
+ plot(fc_list[[i]],G,main=algorithm_list[[i]])
+ }
>par(mfrow=c(1,1))
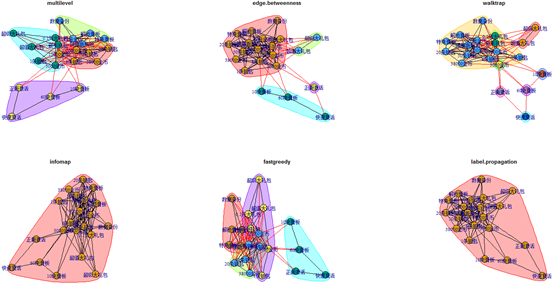
infomap和label.propagation算法不适合于份数据,通过另外四种算法发现的社群结构能帮助我们了解玩家购物喜好分类。
如果期望对R语言进行更深入地学习,了解更多的数据挖掘知识,请关注R语言十三式的团购,现正在火热进行中。