前言
这篇文章会接着上篇分词文章讲,内容也是比较简单,并没有做太多的深究,主要是为了让自己尽快熟悉PYTHON的语言环境,至于算法之类的讲解这里就不多说了
工具:pycharm
环境:python2.7
在这里我导入习惯常用的包
# -*- coding: UTF-8 -*-
import sys
import os
from sklearn.datasets.base import Bunch
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
import cPickle as pickle
import scipy as sp
from numpy import *
设置一下我们的中文语言环境
#设中文语言环境
reload(sys)
sys.setdefaultencoding("utf-8")
编写一个读文文本的函数
def readfile(path):
fp = open(path, "rb")
content = fp.read()
fp.close()
return content
这里我们需要构建一下我们的词空间永久化对象,这个是为了方便我们保存对象信息到文件里面去,当然,这里不做太多的操作,只是为了方便读取
tfidfspase = Bunch(target_name=[], label=[], filenames=[], contents=[],tdm=[],vocabulary={})
这里读取一下停用词表
stopword=r'E:\python_txt/stoplist.txt'
stplist=readfile(stopword).splitlines()
接来下是读取一下我们以前就已经分词好的文本
seg_path=r'E:\python_txt\answer\test/'
catelist=os.listdir(seg_path)
#将各个分类目录保存到词空间对象中
tfidfspase.target_name.extend(catelist)#循环读取分词后的文本,并保存到
print tfidfspase.target_name
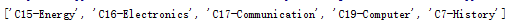
#循环读取分词后的文本,并保存列表中
for mydir in catelist:
class_path=seg_path+mydir+'/'
file_list = os.listdir(class_path)
for file_path in file_list:
full_name=class_path+file_path
tfidfspase.label.append(mydir) # 保存文件分类标签
tfidfspase.filenames.append(full_name) # 保存当前文件的文件路径
tfidfspase.contents.append(readfile(full_name).strip())
开始计算TF-IDF权值
科普TF-IDF:http://baike.baidu.com/link?url=85TvB8SSt9CLTNDJVGvZPpHeWQpVHwXeLitUSYUJs1vAS4yhMN7vtn2iF0anPgvvc-1jhqOmFzbV_QUu9qOtt_
这时候我们的词空间持久化对象就已经构建好了,接下来就是使用sklearn中的TfidfVectorizer初始化词空间了 ,这里的停用词参数就是我们上面加载的数据,顺便打印一下我们才词频向量
vectorizer=TfidfVectorizer(stop_words=stplist,sublinear_tf=True)
transformer=TfidfTransformer()#该类会统计每个词语的IF-IDF权值
#文本转为词频矩阵,单独保存字典文件
tfidfspase.tdm=vectorizer.fit_transform(tfidfspase.contents)
tfidfspase.vocabulary=vectorizer.vocabulary
um_sample,num_features=tfidfspase.tdm.shape
print "sample:%d,features: %d"%(num_sample,num_features)

这里我们总共有862个文本,35万多个属性;
接下来就是就是我们的建模了,建模的这个步骤写的很简单,大神们就稍微看一下笑话吧,本人也在学习中;
这里设置分的簇的大小为5,因为目录分类就为5类,提前知道的
#构建K-MEAN模型
k=5
from sklearn.cluster import KMeans
km=KMeans(n_clusters=k,init="random",n_init=1,verbose=1)
km.fit(tfidfspase.tdm)
接下来我们对一个文档进行测试,这个文档是我们已经提前为它分好了词的。
#测试模型效果
test_path=r"E:\python_txt\answer\test\C7-History/C7-History001.txt"
test_content=[]
test_content.append(readfile(test_path).strip())
test_tfidf =vectorizer.transform(test_content)
print test_tfidf.shape

向量已经成功的生成,接下来就是我们给这个文档进行分类了,并打印类别
new_label=km.predict(test_tfidf)[0]
print "new_label:",new_label

OK!建模就讲到了这里,有兴趣的东西可以深究下去;
参考书籍
《机器学习系统设计》

