fasttext,从名字就是可以看得出来这个是一个快速文本分类器,该算法由facebook在2016年开源,提供了简单高效的文本分类,效果堪比深度学习;这些比较在作者的原始paper上可以得出结果;
这里只是做一个简短的介绍,这个是words2vec衍生出来的一个算法;这个算法的作者也是words2vec作者,他认为
原始论文:https://arxiv.org/pdf/1607.01759v3.pdf
模型图如下
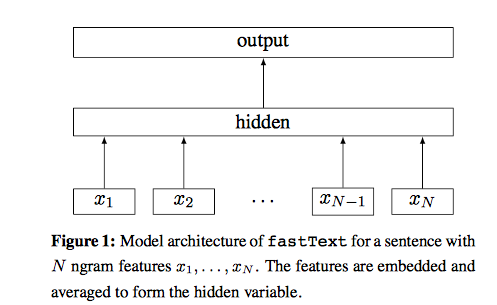
从这个模型图上来看是属于一个一层的神经网络,也分收入层,隐藏层,和输出层;输入层中的词和词组构成特征向量,再将特征向量通过线性变换映射到隐藏层,隐藏层通过求解softmax函数求解各个类别的概率,水平有限,具体各位可以直接看paper;
这里主要讲解在python中如何安装这个fasttext,使用的话我环境因为win和linux两边的环境还未一致,所以,就暂时不介绍使用,目前我查阅资料的话目前是在win上还没找到在解决方案,所以要装fasttext这个第三方包需要在linux上和Mac上,python的版本必须也要2.7以上,必须支持编译C++11;
因为在centos上,默认的gcc版本为4.4.7,这样就没办法编译,所以查找资料如何升级gcc就是重中之重;因为有个社区专家说是没在centos上装成功的时候,自己的心是凉了一大截的,不过我不信邪;所以就尝试了centos上,因为自己的工作环境就是centos上;
所以一开始我是请求百度的
结果美如画,因为很多,觉得大众的智慧是不可战胜的;

点进去看,大部分的流程都是这样,感觉好像没什么问题一样;不过安装到后面的时候,就当我make install 这个步骤的时候,事实告诉我,很多东西想得太简单;
不好意思,好像没保存bug,不过好像是某个工具没装,然后自己又百度一下,发现真的太复杂了,好像感觉fasttext的使用和我好遥远;
 4
4
然后找打了一个清新脱俗的升级gcc的方法,文章简短,没有太多复杂的流程,一看就觉得我发现了我的初恋;心花怒放,不过还没试试一下结果如何;反正死马当活马医。如果用不了fasttext,那我就用朴素贝叶斯模型去给文本分类,反正这个模型效果应该也不差;

这里使用的是devtools工具;这个工具很方便;直接上linux命令
wget http://people.centos.org/tru/devtools-2/devtools-2.repo
mv devtools-2.repo /etc/yum.repos.d
yum install devtoolset-2-gcc devtoolset-2-binutils devtoolset-2-gcc-c++
三个安装包会被装在 /opt/rh/devtoolset-2/root/ 中
mv /usr/bin/gcc /usr/bin/gcc-4.4.7
mv /usr/bin/g++ /usr/bin/g++-4.4.7
mv /usr/bin/c++ /usr/bin/c++-4.4.7
ln -s /opt/rh/devtoolset-2/root/usr/bin/gcc /usr/bin/gcc
ln -s /opt/rh/devtoolset-2/root/usr/bin/c++ /usr/bin/c++
ln -s /opt/rh/devtoolset-2/root/usr/bin/g++ /usr/bin/g++
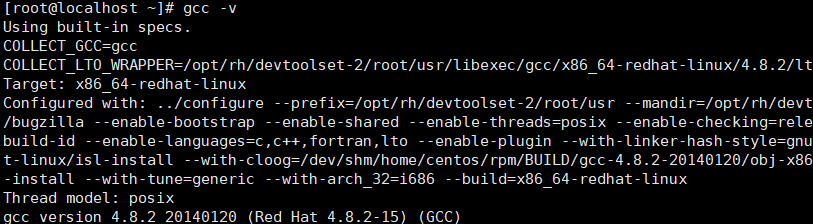
gcc --v
就这几行的命令,就解决我的难题,百度大神真的好多;最后查看我的版本gcc版本
在看看我们使用Pip 安装fasttext情况


好了,大功告成;今天可以给自己加个鸡腿了,明天再使用fasttext训练模型看看

文章中如果有错还请指出,可能打字太快出现错别字,或者说的不对的地方纯属失误,请以paper为主
