毫无疑问,数据的集中趋势和离散趋势是数据分布的最主要两个特征。因此,我们常常会借助算术平均数,中位数,方差,四分位数等指标进行描述性的统计分析,就正如我们经常讨论的正态分布,两个参数均值和标准差正是对应了集中趋势指标和离散趋势指标。但实际上,数据的分布形态各异,很可能偏离于我们原有的假设分布,例如可能数据分布并不对称,例如数据分布较为“陡峭”,而为了研究这些特征以及与正态分布的偏离程度,我们还需要其他的判定指标,偏度和峰度。
一些预备知识
对于随机变量X,假若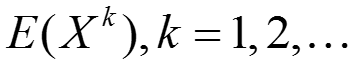 存在,则称它为随机变量X的k阶原点矩;若
存在,则称它为随机变量X的k阶原点矩;若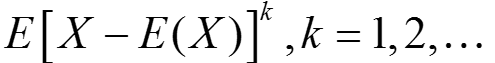 存在,则称它为随机变量X的k阶中心矩;一般,我们使用矩来描述随机变量的特征,例如随机变量的数学期望就是一阶原点矩
存在,则称它为随机变量X的k阶中心矩;一般,我们使用矩来描述随机变量的特征,例如随机变量的数学期望就是一阶原点矩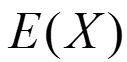 ,方差则是二阶中心矩
,方差则是二阶中心矩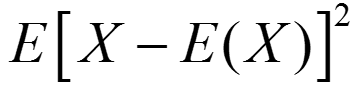 。
。
1. 偏度
偏度,Skewness,是研究数据分布对称的统计量。通过对偏度系数的测量,我们能够判定数据分布的不对称程度以及方向。
具体来说,对于随机变量X,我们定义偏度为其的三阶标准中心矩:
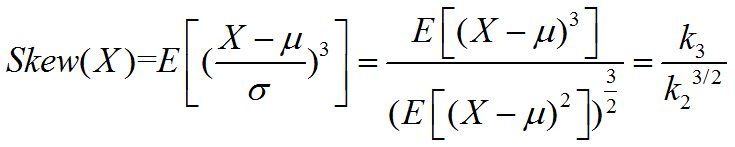
而对于样本的偏度,我们一般简记为SK,我们可以基于矩估计,得到有:
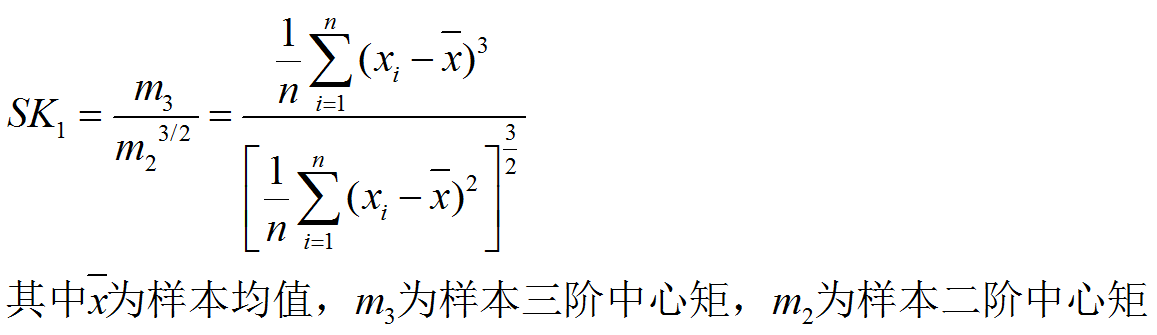
但考虑到,上式的分子分母都不是无偏估计量,因此也有计算公式为:

值得注意的是,上述两种样本偏度的最后计算结果都属于有偏估计。
偏度的衡量是相对于正态分布来说,正态分布的偏度为0。因此我们说,若数据分布是对称的,偏度为0.若偏度>0,则可认为分布为右偏,即分布有一条长尾在右;若偏度<0,则可认为分布为左偏,即分布有一条长尾在左,同时偏度的绝对值越大,说明分布的偏移程度越严重。
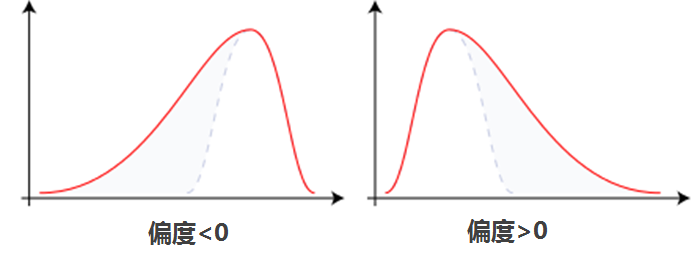
另外,偏度>0,分布右偏,长尾在右,高峰在左,这似乎与一般认知不太一致。但其实我们可以发现偏度实际上是三阶标准中心矩,而一个数据距离“中心”越远,对中心矩的计算影响越大。而当数据长尾在右,即有更多正偏的离群值,因此偏度>0;
2.峰度
峰度,Kurtosis,是研究数据分布陡峭或平滑的统计量,通过对峰度系数的测量,我们能够判定数据分布相对于正态分布而言是更陡峭还是平缓。
具体来说,对于随机变量X,我们定峰度为其的四阶标准中心矩:
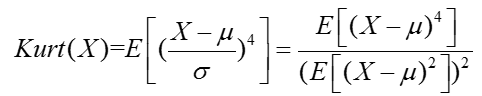
而对于样本的峰度,我们一般简记为K,可通过如下公式计算样本的峰度系数:

同样考虑到,上式的分子分母都不是无偏估计量,因此也有计算公式为:

特别需要注意的是,峰度其实也是一个相对于正态分布的对比量,正态分布的峰度系数为0,而均匀分布的峰度为-1.2,指数分布的峰度为6。
当峰度系数>0,从形态上看,它相比于正态分布要更陡峭或尾部更厚;而峰度系数<0,从形态山看,则它相比于正态分布更平缓或尾部更薄。在实际环境当中,如果一个分部是厚尾的,这个分布往往比正态分布的尾部具有更大的“质量”,即含又更多的极端值。
从下图可以看到,拉帕拉斯,双曲正割,逻辑斯底分布的峰度系数均大于0,且他们的峰更陡峭,同时尾部也更厚。而像升余弦分布,半圆形分布,以及均匀分布则是峰度系数<0,同时也可以看到他们更加的平缓。

3.峰度的影响实验
为了进一步验证分布中各处的值如何影响峰度变化,浩彬老撕构造了如下实验:
(1)新增数据加在尾部:原有总体分布:N(0,3^2),1000000样本+新增数据N(9,3^2),1000个样本。新增比例为原有的0.001,峰度从0增加为0.073;
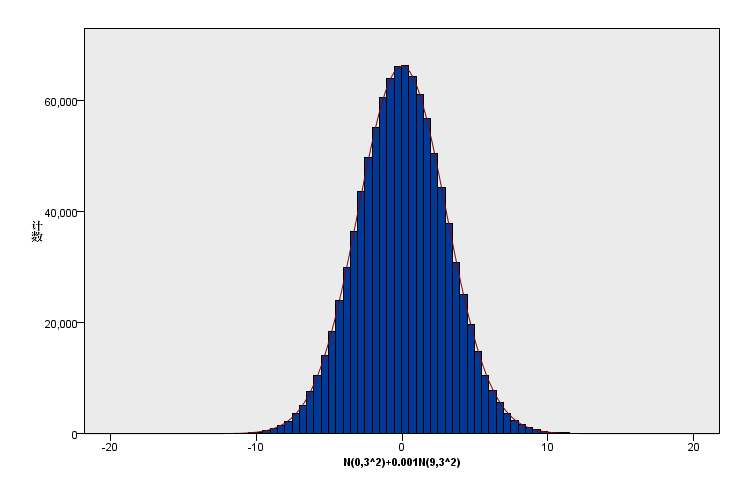
(2)新增数据加在尾部:原有总体分布:N(0,3^2),1000000样本+新增数据N(9,3^2),20000个样本。新增比例为原有的0.02,峰度从0增加为0.996;
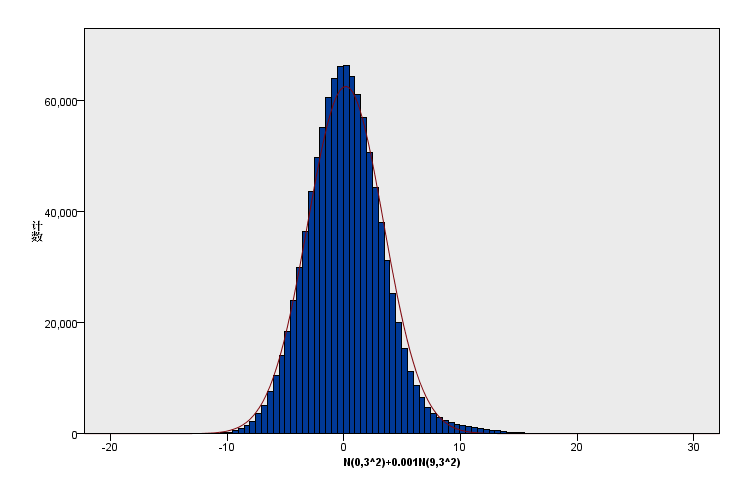
(3)新增数据加在峰部(高峰更高):原有总体分布:N(0,3^2),1000000样本+新增数据N(0,1),1000个样本。新增比例为原有的0.001,峰度从0增加为0.004;
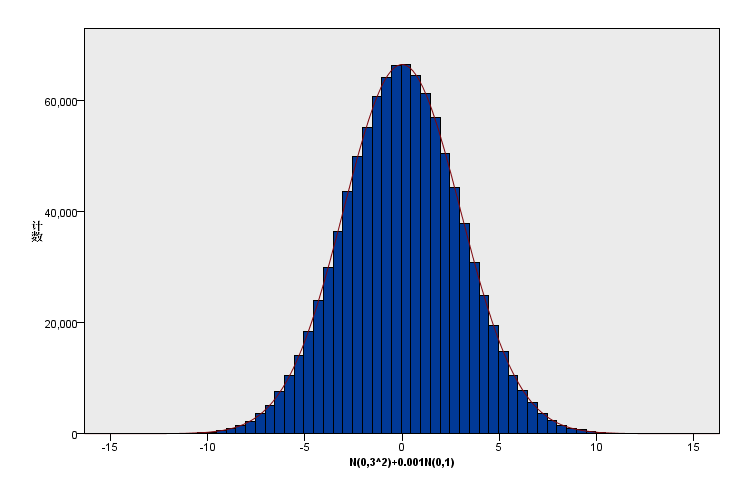
(4)新增数据加在峰部:原有总体分布:N(0,3^2),1000000样本+新增数据N(0,1),20000个样本。新增比例为原有的0.02,峰度从0增加为0.049;
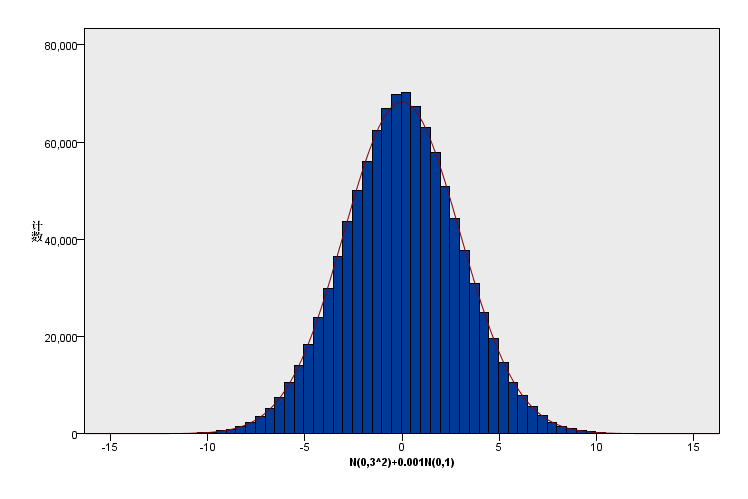
(5)新增数据加在山腰中部位置:原有总体分布:N(0,3^2),1000000样本+新增数据N(4.5,1),1000个样本。新增比例为原有的0.001,峰度从0降低为-0.003;
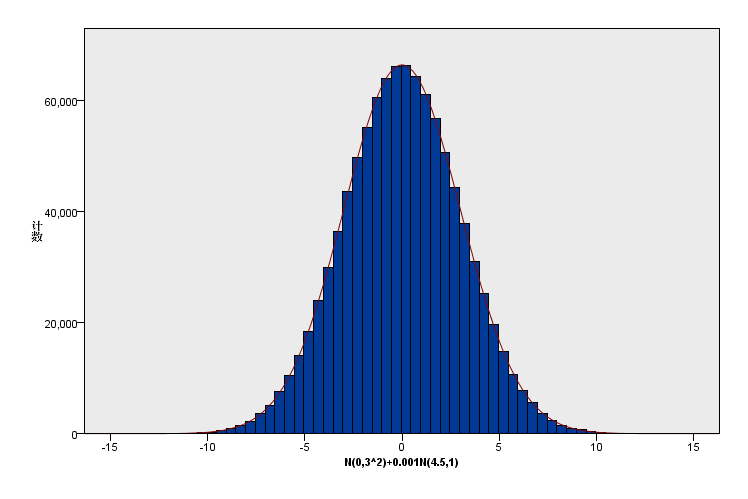
(6)新增数据加在山腰中部位置:原有总体分布:N(0,3^2),1000000样本+新增数据N(4.5,1),20000个样本。新增比例为原有的0.02,峰度从0降低为-0.084;
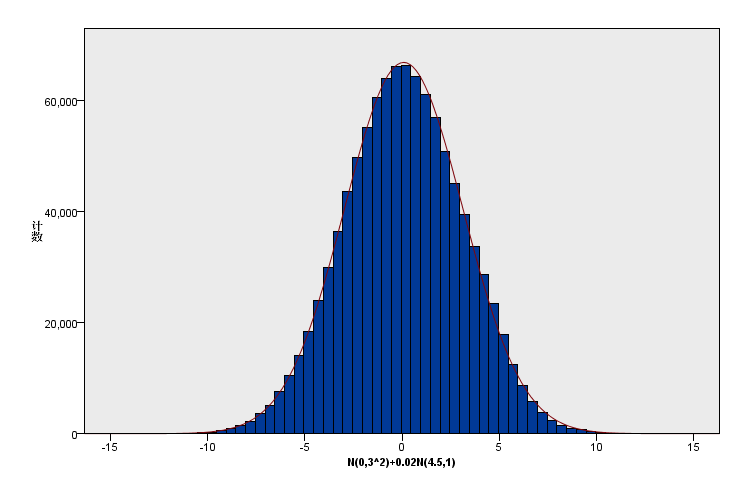
从上述实验可知,尾部或离群点对峰度影响为正向,且影响程度最大。而高概率区对峰度影响也为正向,但是比较少;而山腰位置,中等概率区域则影响为负向。
近期热门文章精选(点击标题即可阅读):
1.R vs Python:R是现在最好的数据科学语言吗?
2.干货教程|可能是最方便好用的文字云工具
3.可视化干货|可能是最好玩的像素地图
4.(理论+案例)如何通俗地理解极大似然估计?
5.XGBoost 与 Boosted Tree

作者简介:浩彬老撕
好玩的IBM数据工程师,
立志做数据科学界的段子手,
致力知识分享,每月至少一次送书活动
