本周新开一个SPSS的工具系列,会结合算法和工具使用持续更新,欢迎广大SPSS使用爱好者共同交流!

初步认识数据科学,这只是一个起点,远的真谈不上,也不合适。至于角度,为什么从spss谈起?
说实话,咱们做项目也好或者只是学习一个技能,远大目标是要有,但是有一个切入点更为重要。所以这里,远大目标是数据科学,那切入点就是spss。
而这个切入点是spss,是某类挖掘算法,还是数据可视化,这个问题是重要,但并不是决定性的。这些切入点只要能够在早期激发起学习者的兴趣而且能够帮助大家快一点的找到手感,我觉得都好。所以这样看来的话,从spss谈起,这肯定不会是一个差的开局,因为SPSSModele确实是业界中既具备专业性也具备易用性的强大工具。
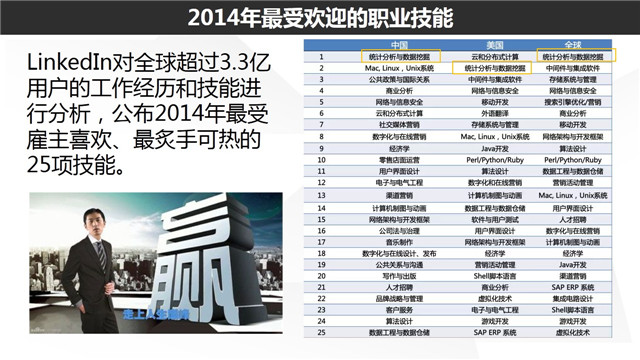
曾经说过,待准备好,这页材料准备好至少能讲30分钟,其实不是说这个主标题,或者说副标题,而是下面这25张图片的人物。全球顶尖的25位数据科学家。这些人离我们这么远又那么近,谁不想以后成为当中的一员呢?


大数据火了这么久,尽管不要求每个人都要学会数据挖掘,但是确实数据科学已经逐渐成为一门通用技能,甚至都已经出漫画了!
欧姆社学习漫画:这是一个系列,系列豆瓣平均评分7.5以上,大部分平均高于8分,以漫画诙谐有趣的方式为讲述统计学知识,绝对不会让你打瞌睡;
统计数字会撒谎:豆瓣评分7.5;百科介绍“这本书是美国统计专家达莱尔·哈夫的传世之作,该书引发的“编造虚假信息”话题受到美国社会持续普遍的关注和美国权威媒体的激烈争论。
一句话总结就是,嗯,其实就是教你怎么操纵统计结果,以及一本统计结果防骗指南,通俗读物。
这不仅仅是一个通用必备技能,它还能让你职场炙手可热:
据Glassdoor网站报告,现在数据科学家的平均年薪是118709美元,比程序员的64537美元还要多。
最后,精通它,还能让你摆脱单身狗的身份!

男猪脚名字叫McKinlay(麦金利),35岁,体型偏瘦,怎们看都是一个一头蓬乱头发的中年男子。
自从去年分手以后,他已经在社交相亲网站上搜索了9个月,可惜毫无结果。他已经给几十个网站推荐为潜在配偶的女性们发去了自我介绍信息,但大部分都被忽略了,在洛杉矶,McKinlay与女性的匹配度简直是糟糕透顶。
但是他们没有忘记他是一个数学家的本事,他先是通过爬虫技术获取大量的女性样本,再通过keams聚类算法把所有女性划分为7个有效群体,同时通过对这些女性群体的分析,他特意为自己建了两份不同的档案(当然也是基于真实经历,但是侧重点略有不同)。经过一系列分析后,他每天都能收到上百个女性打招呼。最后通过不断改进模型(当然也要不断改进约会策略啦),他终于找到生命中的另一半~
McKinlay现在已经摆脱单身狗的身份并且已经求婚成功了!
嗯,打完鸡血,咱们正式进入正题:
先给大家介绍SPSS光辉的历史:


在今年IBM SPSS开发实验室已经在SPSS Modeler 18.0版本中加入了MAC版(至于Statistics之前就已经发布了Mac版本)!



虽然SPSS家族庞大,但是胖子也得一口一口饭吃成:

在正式进入之前,先为大家介绍一个方法论:
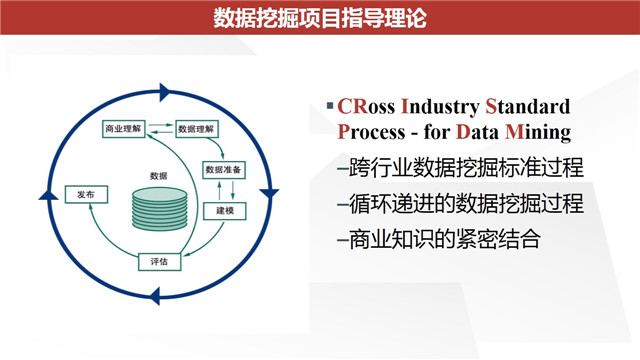
一般我们认为数据挖掘会是一个持续性的项目过程,尤其是在商业数据挖掘当中。在这个过程中,毫无疑问的是数据挖掘的各种算法是数据挖掘过程的核心步骤,但我们也要明白算法并不是整个项目的全部决定性因素。而为了使得整个数据挖掘过程更加标准化,也就催生出很多指数数据挖掘过程的方法论,其中IBM SPSS Modeler使用的就是CRISP-DM(CRoss IndustryStandard Process- for Data Mining,跨行业数据挖掘标准流程),其中一共分为6个步骤:商业理解,数据理解,数据准备,建模,评估,发布。在这里介绍CRISP-DM方法论的原因是因为稍后我们能够看到IBMSPSS Modeler的项目过程也是用这个设置的,关于具体方法论的介绍,浩彬老撕可以在以后单独发文介绍。
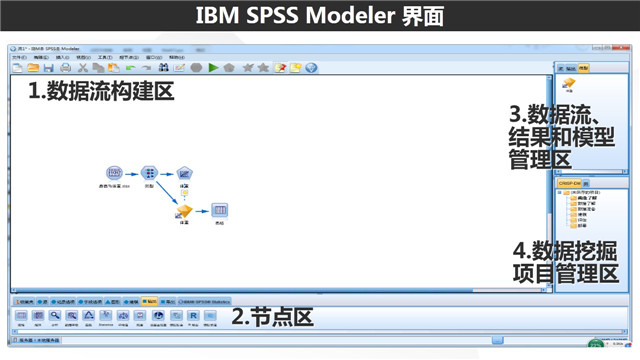
上面就是IBM SPSS Modeler的主界面。可以看出来IBM SPSS Modeler的思想是希望能够以简洁,简单的方式帮助用户进行数据挖掘。事实上,SPSS Modeler一直是希望能够尽可能屏蔽数据挖掘挖掘算法的复杂性以及操作的繁琐,希望让使用者尽可能地聚焦于如何选择数据挖掘技术去解决当前的商业问题。
如上图,我们可以看到整个假面可以分为4个区域(1)数据流构建区(2)数据流、结果和模型管理区(3)数据挖掘项目管理区(4)节点区
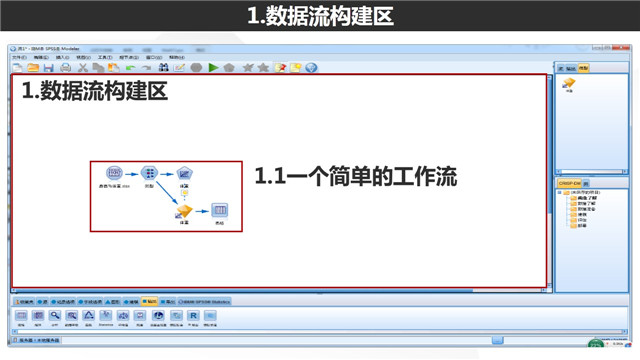
数据流构建区是分析人员的主要工作区域,如上图展示了一个简单的工作流,我们通过构建一个个工作流帮助我们完成数据探索,数据清洗以及数据建模等工作。
工作流在Modeler中,我们称之为stream,因此我们也可以看到moderl保存的文件也是以.str结尾的。从上面的工作流中,我们可以看到有5个节点,以及节点之间的连接构成。这些工作节点可以由下方节点区拖拽到数据流区。实际上,我们可以看到一次数据挖掘过程(或者说构建一个工作流),就是由分析人员通过拖动一个一个节点,完成的一系列过程。
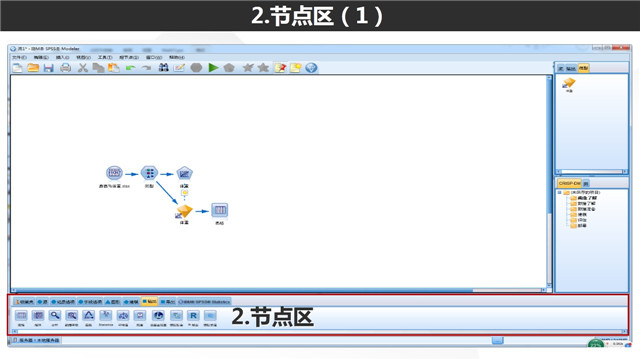
如果说上面的数据流构建区是咱们分析师的工作室,那么节点区就是为我们构建数据流的弹药室了。我们知道数据流是由一系列节点连接而成,而所有这些节点都来源于下方的这个节点区。按照数据挖掘过程来说,我们也大体可以把下面的节点分为三类:
(1)起始节点,这类节点是整个数据流的开端,等同于实际类别的源节点(即数据读取节点),这类节点之前不能再连接其他节点;
(2)中间节点,这类节点往往是数据挖掘过程的一个步骤,可以在它之前以及之后都可以接其他类型的节点;
(3)终端节点:这类节点代表了数据流(或者数据流的一个分支)的结束,图形/输出/导出节点都属于这类,这类节点后面不能再接其他类型的节点。
一个最简单的数据流可以只包含一个起始节点和一个终端阶段,进一步地,Modeler按照具体划分,把所有节点划分为8大类。
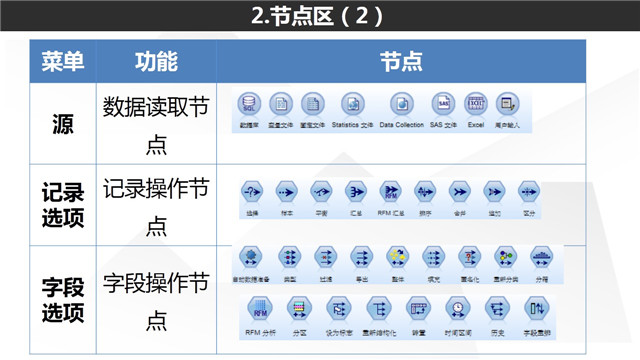
(1)源节点:属于起始节点。源节点包含了各类型数据源接入的方式,例如数据库节点可以帮助我们直接读取数据库里面的数据文件,Excel节点则可以帮助我们读取excel文件等;
(2)记录选项:属于中中间节点。该节节点提供了对数据宽表进行记录层面(即对数据从行的角度)的处理,例如我们拥有包含100个男女学生成绩记录的数据,选择节点可以帮助我们从100个包含记录当中选择当中的男性记录;
(3)字段选择:属于中中间节点。该节节点提供了对数据宽表进行字段(也称变量,属性)层面(即对数据从列的角度)的处理,例如我们拥有包含100个男女学生成绩记录的数据,过滤节点可以帮助我们过滤掉语文成绩以及英语成绩,只保留数学成绩;
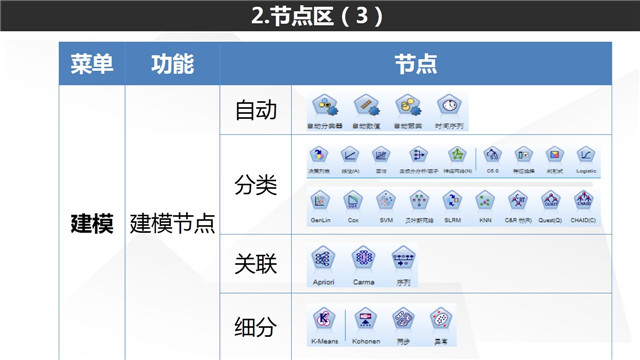
(4)建模节点:建模节点属于终端节点。各位可能觉得奇怪,建模并不是数据挖掘的结束,为什么属于终端节点?实际上,Modeler的建模节点为我们提供数据挖掘模型的参数调整,待该节点运行后会生成一个金黄色的“模型节点”,而该节点就属于中间节点,可以供我们后续调用了。Modeler建模节点分为4个部分分类节点;关联节点;细分(即聚类);自动;
值得注意的是自动节点能够批量选择算法自动运行,例如选择自动分类器,我们就可以一次选多个分类算法(如一次性运行knn,C5.0,神经网络),并各自设置参数,运行后,该节点将自动选择报告最优模型,非常的方便。

(5)图形节点:属于终端节点。图形选项卡下为我们提供了多种的图形功能,让我们可以很简单地通过图形展示的方式进行数据探索,结果展示乃至于结果评估;
(6)输出节点:属于终端节点。输出选项卡下为我们提供了多种的数据以及结果的展示能力,如表格,矩阵,交叉表,统计结果等,可以帮助我借助统计分析来进行适当的数据探索以及结果评估;
(7)导出节点:属于终端节点。提供与源节点帮助我们读取数据相反的能力,帮助我们把数据结果导出到各种格式的文件进行保存,如写回数据库,如导出为excel文件;值得注意的是,输出节点用不同方式在modeler上展示结果,而导出节点则是导出数据结果为文件进行保存。
(8)Statistics节点:属于终端节点。正如咱们所有,作为spss曾经的两大支柱产品之一的Statistics,我们可以在modeler的statistics选项下的各种节点很方便地调用statistics的功能了。
另外,细心的读者可能也发现了在节点区我们还有一个收藏夹选项卡,该选项卡下,咱们可以把常用的功能节点放进去,方便日常使用。
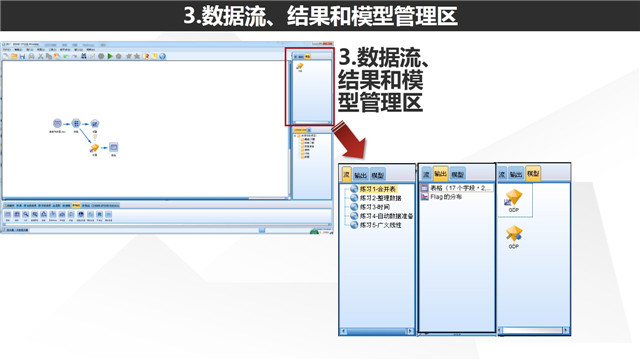
在主界面的右上方有一个对建模过程的管理区,该管理区下分为3个选项卡:
(1)流:流管理区,有些情况下,我们通常会同时构建/编辑多个模型流,这样的情况下,在流管理区中,我们就可以非常轻松地对多个流进行切换;
(2)输出:在上文我们知道节点区有一个输出选项卡以及图形选项卡,通过输出/图形选项卡我们可以输出多种结果。因此在一次建模过程当中,我们可能会产生多种结果,那么通过输出选项卡,我们可以对每个选择结果进行编辑命名,随意切换,甚至把特定的结果保存为文件供下次查看;
(3)模型:在该选项卡下,modeler所建立的所有模型都将出现在这里,我们可以通过该选项卡随时查看生产的模型,甚至把模型结果单独保存。
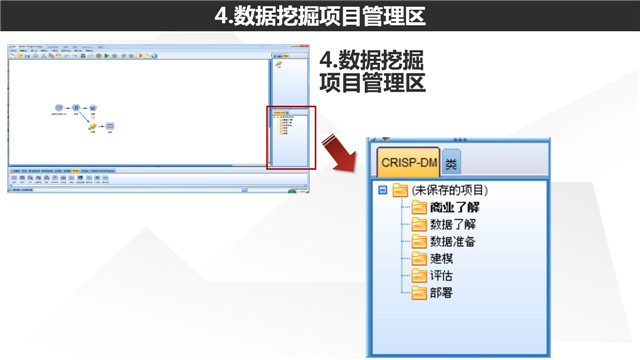
在主界面的右下方就是我们的数据挖掘项目管理区,正如咱们在前面介绍方法论时所谈到的“数据挖掘会是一个持续性的项目过程,尤其是在商业数据挖掘当中。”可以看到,这里面的阶段设置就是按照CRISP-DM方法论进行划分的,因此可能在商业理解过程中我们特意构建一个数据流,在数据准备过程中,我们可能构建了两个数据流。而通过这个项目管理区,我们就可以很方便把相应的内容(无论是str文件,结果,模型乃至于word文档都可以归纳进来)对号入座,在每次开展或者继续项目的时候就可以很容易进行查看操作,非常方便我们分析人员进行管理。


有些朋友可能会疑问,为什么需要特定介绍鼠标操作,这是因为利用Modeler进行日常挖掘的过程中,鼠标操作占了70%以上,同时记住一些常用功能也能大大增加效率,咱们现在以日常使用的三键鼠标为例,解释一些典型使用功能。
左键:用于节点选择,按住此键可以将节点进行随时拖动;
右键:用于挑出菜单,菜单中包含一系列诸如连接,编辑,复制,删除等功能;
滚轮:按住此键移动鼠标可以用于节点间进行连接,非常好用的一个功能!



浩彬老撕正在努力做一些事情,希望能够以比较轻松的方式为大家讲述一些统计学,数据挖掘的知识,包括算法,包括工具使用问题,也包括一些科技八卦,同时也会举办一些送书活动(咱第一期送的是《数学之美》),希望大家能够喜欢。另外如果你想联系我,欢迎在公众号中直接发送你想说的话与浩彬老撕直接交流~
长按二维码即可关注!如果你觉得浩彬老撕的内容还不错,希望你可以推荐给其他小伙伴↓↓↓



