本文作者韦玮原创,转载请注明出处。
项目需求与问题引入
有时,我们想爬取腾讯动漫中的漫画,比如,我们不妨打开腾讯动漫中某一个动漫的网址http://ac.qq.com/Comic/comicInfo/id/539443,如下图所示:
然后,我们点击“开始阅读”,出现如下所示界面:
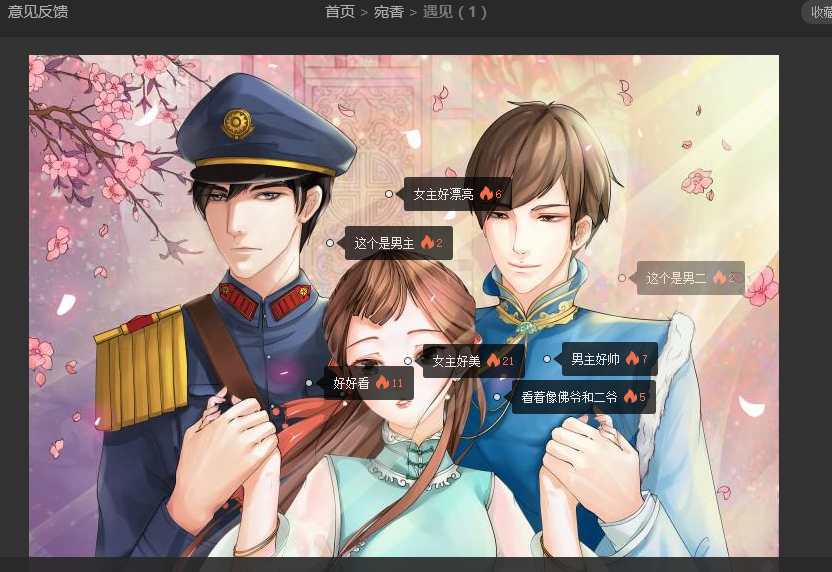
可以看到,在此有一副漫画,我们可以按常规方式尝试进行处理,我们查看该网页对应的源代码,可以发现在源代码中并不能找到这副漫画的图片地址,并且,当我们鼠标往下滑动的时候,才会触发加载后续的漫画,所以,我们可以初步断定,这种数据是通过异步加载动态触发出来的。
按照一贯的解决思路,我们接下来尝试使用抓包分析进行解决这个问题,所以我们打开Fiddler。
打开Fiddler之后,我们再次打开动漫页拖动触发出相应的漫画,与此同时,Fiddler中会依次出现新触发的资源信息,如下所示:
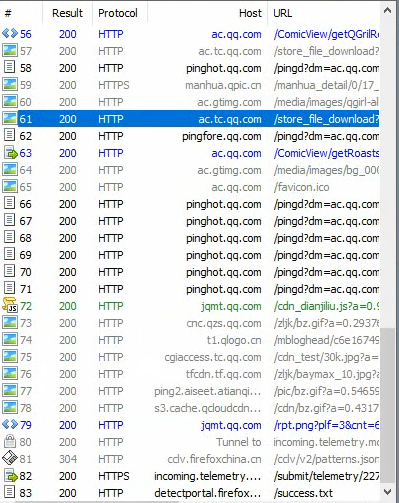
我们依次分析这些网址,并把漫画相关的网址整理复制出来,放到word中,如下所示:

通过对比观察,我们可以看到漫画资源的网址规律。
对应的规律如下:
http://ac.qq.com/store_file_download?buid=动漫ID&uin=uin值&dir_path=/&name=日期_随机数_漫画图片ID.jpg
我们可以看到,其地址中有一段是随机数,这一段网址我们很难通过以往的网址构造的方法构造出来,所以,即使分析出了网址规律也无济于事,因为这个网址的规律中有一部分是随机数,即无规律的字段。
所以,显然,这种网址动态触发+资源随机存储的反爬策略我们采用以往的反爬攻关技巧很难解决,这一点大家可以先按常规的方法尝试写一遍便会有深刻感触。
问题的解决办法总是有的,只要我们思考,接下来,我们就为大家讲解这一种反爬策略应该如何攻克解决,今天我们的主要需求与目的是使用Python自动爬取腾讯动漫里面的各个漫画,实现自动加载触发漫画并得到随机地址的功能,以此为例为大家讲解网址动态触发+资源随机存储的反爬策略的攻克方式。
问题难点与解决思路
由上面的介绍,我们可以知道,目前问题的难点在于:
1、漫画图片动态触发,异步加载,无法通过漫画的主网址获得这些各漫画图片的网址,而没有漫画图片的网址,我们无法爬取这些漫画图片。
2、漫画图片网址中含有随机参数,即使我们通过抓包分析分析出各漫画网址的规律,也无法主动构造出这些漫画图片的地址。
这些问题其实我们可以解决,先为大家介绍一下解决思路,解决思路如下:
1、通过PhantomJS(无界面浏览器)自动触发出漫画图片。
2、通过JS代码实现页面滑动,以自动触发出剩下的多张漫画图片。
3、触发出漫画图片之后,将漫画地址通过正则表达式提取出来。
4、交给Urllib或者Scrapy普通爬虫,对相关资源进行自动爬取,在这里我们使用Urllib模块编写相关爬虫。
在这里稍微解释一下,PhantomJS虽然可以触发相关的数据,因为其本质就是浏览器,但是其效率是比较慢的,所以,一般情况下,我们会将主要爬虫处理部分交给Urllib或者Scrapy等常规爬虫,这样效率高,而如果常规爬虫不能处理的部分,我们可以将这一部分交给PhantomJS等处理,处理完成后交由常规爬虫处理,也就是不同的技术负责不同的部分,整合起来写,这样可以让爬虫的效率更高,并且不影响爬虫的功能。
使用PhantomJS实现动态触发动漫图片地址的获取
接下来,我们就来编写实现相关的项目。
首先,我们导入相关模块:
from selenium import webdriver
import time
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
然后,我们需要基于PhantomJS创建一个浏览器,并且设置一下用户代理,否则可能出现界面不兼容的情况,如下所示:
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ("Mozilla/4.0 (compatible; MSIE 5.5; windows NT)" )
browser = webdriver.PhantomJS(desired_capabilities=dcap)
然后,我们通过PhantomJS打开相关动漫网页,将相关动漫图片地址触发出来,如下所示:
#打开动漫的第一页
browser.get("http://ac.qq.com/ComicView/index/id/539443/cid/1")
#将打开的界面截图保存,方便观察
a=browser.get_screenshot_as_file("D:/Python35/test.jpg")
#获取当前页面所有源码(此时包含触发出来的异步加载的资源)
data=browser.page_source
#将相关网页源码写入本地文件中,方便分析
fh=open("D:/Python35/dongman.html","w",encoding="utf-8")
fh.write(data)
fh.close()
随后,我们运行相关代码,运行完成后,会发现对应的截图D:/Python35/test.jpg如下所示:

可以看到,前面几幅漫画图片成功加载,可是后面的漫画图片却没有加载出来,为什么呢?
显然后面的漫画图片我们需要触发才能加载,所以我们可以使用JS代码实现自动拖动触发后面的漫画的功能。
在没有触发后续的漫画图片之前,我们不妨看一下此时的网页源代码,我们在源代码中搜索“ac.tc.qq.com/store_file_download”,即搜索满足漫画图片资源的网址格式的地址,看看源码中有没有,如下所示:
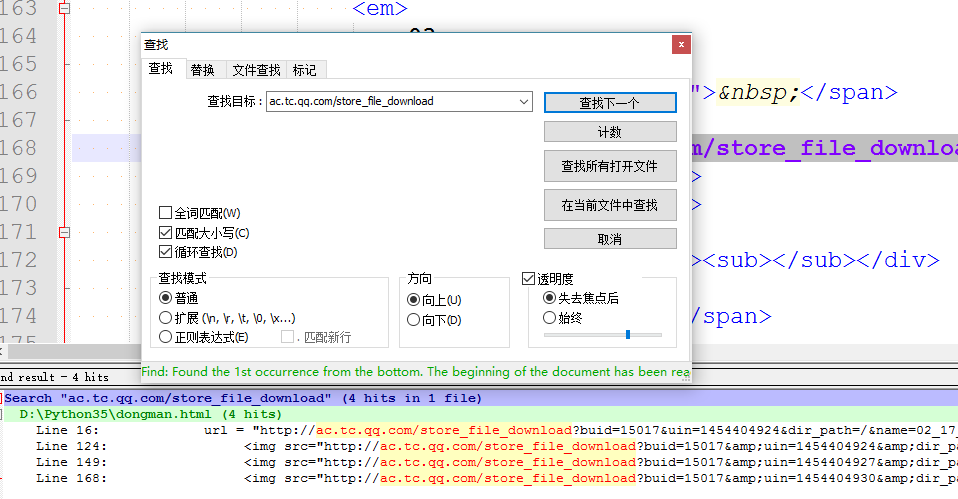
可以看到,此时只有4各匹配的网址,说明此时确实没有加载出相关的剩下的动漫图片资源网址。
接下来,我们可以通过window.scrollTo(位置1,位置2)实现自动滑动页面,触发后续的网址,我们可以在上面的:
browser.get("http://ac.qq.com/ComicView/index/id/539443/cid/1")
代码下面插入如下补充代码:
for i in range(10):
js='window.scrollTo('+str(i*1280)+','+str((i+1)*1280)+')'
browser.execute_script(js)
time.sleep(1)
通过该循环,我们可以依次进行自动滑动,模拟滑动后自然会触发后续的图片资源。
随后,我们再次执行代码,执行完代码后,截图中你可以看到剩下的动漫图片资源已经加载出来了,并且源码中,匹配的网址也变多了,源码中网址的匹配情况现在如下所示:
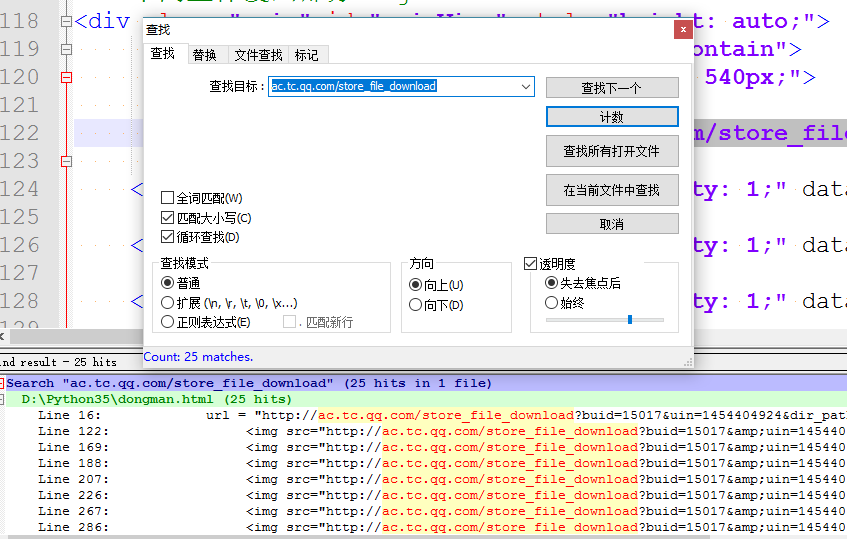
可以看到,此时符合规律的网址已经变成了25个,所以,现在,当前页面中的所有图片资源已经加载出来了。
显然,我们通过PhantomJS已经实现了异步资源触发与随机网址获取的功能了。接下来我们将需要提取出相关动漫图片的网址,并交由Urllib模块进行后续爬取。
结束了PhantomJS的使用之后,我们需要关闭一下浏览器,所以,我们在代码后添加如下一行代码:
browser.quit()
编写完整爬虫项目
随后,我们继续编写该爬虫项目。
我们可以通过正则表达式'<img src="(http:..ac.tc.qq.com.store_file_download.buid=.*?name=.*?).jpg"'将所有动漫资源图片网址提取出来,提取出来之后,通过urllib对这些图片进行爬取,爬到本地。
具体代码实现如下:
import re
import urllib
#构造正则表达式提取动漫图片资源网址
pat='<img src="(http:..ac.tc.qq.com.store_file_download.buid=.*?name=.*?).jpg"'
#获取所有动漫图片资源网址
allid=re.compile(pat).findall(data)
for i in range(0,len(allid)):
#得到当前网址
thisurl=allid[i]
#去除网址中的多余元素amp;
thisurl2=thisurl.replace("amp;","")+".jpg"
#输出当前爬取的网址
print(thisurl2)
#设置将动漫存储到本地的本地目录
localpath="D:/Python35/dongman/"+str(i)+".jpg"
#通过urllib对动漫图片资源进行爬取
urllib.request.urlretrieve(thisurl2,filename=localpath)
随后,我们运行该代码,便可以在本地目录D:/Python35/dongman/下看到如下信息:
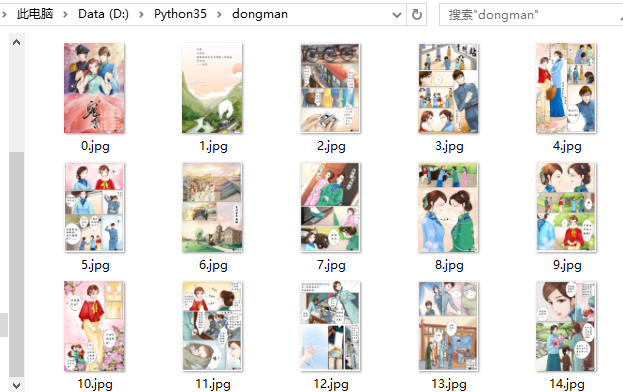
可以看到,相关动漫图片资源已经爬到本地了。
为了方便大家调试,我们提供完整代码,完整代码如下所示:
from selenium import webdriver
import time
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import re
import urllib.request
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ("Mozilla/4.0 (compatible; MSIE 5.5; windows NT)" )
browser = webdriver.PhantomJS(desired_capabilities=dcap)
#打开动漫的第一页
browser.get("http://ac.qq.com/ComicView/index/id/539443/cid/1")
for i in range(10):
js='window.scrollTo('+str(i*1280)+','+str((i+1)*1280)+')'
browser.execute_script(js)
time.sleep(1)
#将打开的界面截图保存,方便观察
a=browser.get_screenshot_as_file("D:/Python35/test.jpg")
#获取当前页面所有源码(此时包含触发出来的异步加载的资源)
data=browser.page_source
#将相关网页源码写入本地文件中,方便分析
fh=open("D:/Python35/dongman.html","w",encoding="utf-8")
fh.write(data)
fh.close()
browser.quit()
#构造正则表达式提取动漫图片资源网址
pat='<img src="(http:..ac.tc.qq.com.store_file_download.buid=.*?name=.*?).jpg"'
#获取所有动漫图片资源网址
allid=re.compile(pat).findall(data)
for i in range(0,len(allid)):
#得到当前网址
thisurl=allid[i]
#去除网址中的多余元素amp;
thisurl2=thisurl.replace("amp;","")+".jpg"
#输出当前爬取的网址
print(thisurl2)
#设置将动漫存储到本地的本地目录
localpath="D:/Python35/dongman/"+str(i)+".jpg"
#通过urllib对动漫图片资源进行爬取
urllib.request.urlretrieve(thisurl2,filename=localpath)
可以看到,当我们直到了解决方法之后,项目实现起来并不难,在这里,大家需要通过这一个例子,掌握这一类问题的解决思路,即掌握网址动态触发+资源随机存储的反爬策略的攻克解决方案。希望大家可以多多练习,希望这篇文章能够让遇到这一类问题的同学获得解决的思路与启发。
作者新书推荐

《精通Python网络爬虫》,机械工业出版社2017年4月出版,已经全仓到货。
本书从技术、工具与实战3个维度讲解了Python网络爬虫:
技术维度:详细讲解了Python网络爬虫实现的核心技术,包括网络爬虫的工作原理、如何用urllib库编写网络爬虫、爬虫的异常处理、正则表达式、爬虫中Cookie的使用、爬虫的浏览器伪装技术、定向爬取技术、反爬虫技术,以及如何自己动手编写网络爬虫;
工具维度:以流行的Python网络爬虫框架Scrapy为对象,详细讲解了Scrapy的功能使用、高级技巧、架构设计、实现原理,以及如何通过Scrapy来更便捷、高效地编写网络爬虫;
实战维度:以实战为导向,是本书的主旨,除了完全通过手动编程实现网络爬虫和通过Scrapy框架实现网络爬虫的实战案例以外,本书还有博客爬取、图片爬取、模拟登录等多个综合性的网络爬虫实践案例。
作者在Python领域有非常深厚的积累,不仅精通Python网络爬虫,在Python机器学习、Python数据分析与挖掘、Python Web开发等多个领域都有丰富的实战经验。
京东正版购买入口(推荐):点击进入
当当正版购买入口:点击进入
天猫正版购买入口:点击进入
.jpg){kind=link}



