有一件特别有意思的事情,和大家分享一下。
上周,有个面试,我陪同技术负责人一起去了,来面试的是一个985的硕士毕业生,做了2年开发,之后2年做的NLP算法,现在来面试我们公司的NLP算法岗位。看了一下他的简历,做过挺多项目,其中也有两个NLP相关项目。
面试时候问到了很多NLP的任务如何解决,例如文本分类、实体识别,面试者都说用BERT,我们问到GPT,问了几个简单的问题,他竟然一脸茫然,全然不知。
之前面试的一些985和211应届毕业生,对这些算法原理掌握的还是很不错的,这位面试者可能长期忙于项目,感觉他论文读的比较少。
当时的问题如下:
GPT效果没之后提出的BERT效果好,可以说说原因么?
GPT中的半监督是怎样体现的?
GPT和Transformer有什么异同点?
其实这些问题并不难,只要你读过GPT的论文。
我们趁此机会详细讲讲GPT吧。
GPT是Generative Pre-Training的缩写,出自于2018年OpenAi发布的论文《Improving Language Understandingby Generative Pre-Training》之中,论文链接是:https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
GPT采用了Pre-training(预训练)和Fine-tuning(微调)的训练方法,目标是学习一种通用的表示形式,该表示形式几乎不需要怎么调整就可以适用于各种NLP下游任务。首先,对未标记的数据建立语言模型,学习神经网络模型的初始参数。
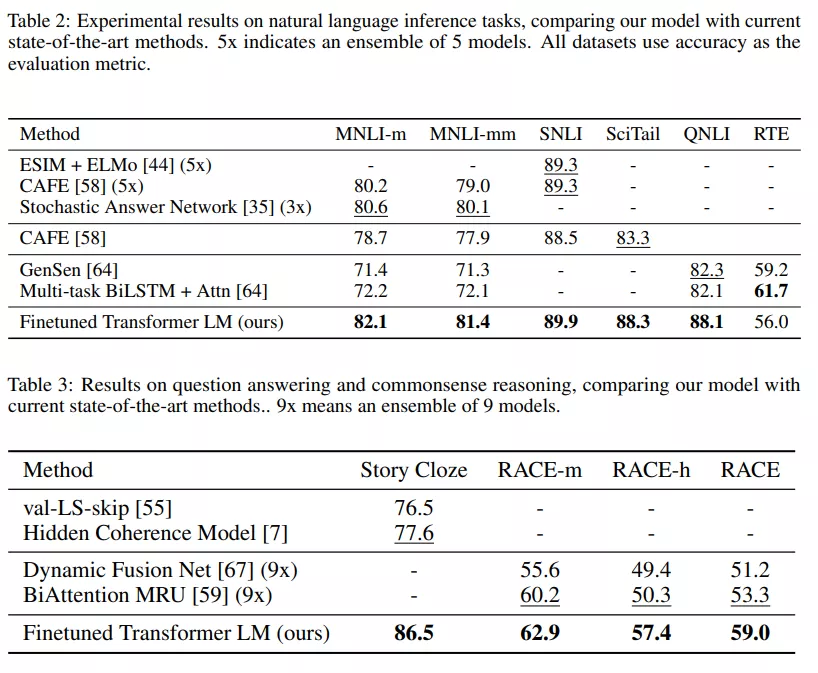
随后,使用相应的有监督的方式将这些参数调整为NLP下游任务所需要。在四种类型的语言理解任务上评估该方法,分别是:自然语言推理,问题回答,语义相似性和文本分类任务。在12个子任务中有9个达到了当时的最先进水平(state of the art)。
整个训练过程包括两个阶段,第一阶段是在大型语料库上使用无监督的方式训练。随后是微调阶段,使用的是当前任务的有监督数据。无监督预训练
首先是有大量的语料,其中的token(词语)可以以如下方式表示: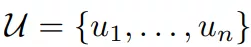 我们使用标准的语言模型的求解目标,来最大化下面式子:
我们使用标准的语言模型的求解目标,来最大化下面式子:
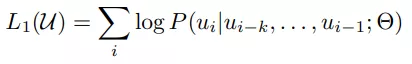
其中k是内容窗口大小,也就是在预测第i个词的时候,可以看到的是i之前的k个词,同时,Θ在预测中也被考虑进去了,Θ是神经网络的参数。参数使用SGD的方法训练。论文使用的是多层的Transformer的decoder作为语言模型结构,结构如下,基本和Transformer的decoder一致,层数不太一样:
具体过程可以由下式表示:
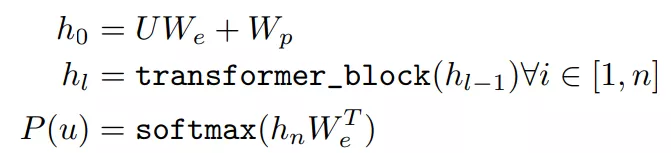 其中
其中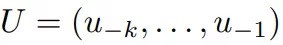 U是不同词语的词向量组成的,n是层数,上面论文中的图显示的是12层,输入的数据经过乘以词嵌入参数We,再加上位置参数Wp。再经过i个层,最后经过softmax层输出。有监督微调
U是不同词语的词向量组成的,n是层数,上面论文中的图显示的是12层,输入的数据经过乘以词嵌入参数We,再加上位置参数Wp。再经过i个层,最后经过softmax层输出。有监督微调
当我们拿到了无监督预训练好的模型后,我们在其基础上进行有监督微调,前面的部分公式和上面一样,以下这部分不同:
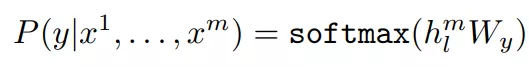
需要最大化的是:
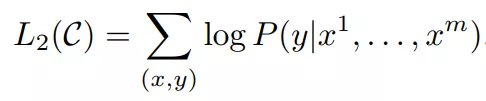
作者发现,将语言模型也纳入微调时有帮助,可以提高监督模型的通用性,还能加速收敛,如下:
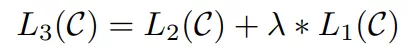
所以优化的目标从L2变成了L3。微调时只需要训练Wy这个参数集合。
对于不同的任务进行微调,将所有结构化输入转换为token序列,由预训练模型进行处理,然后再进行线性+softmax层。下图是不同NLP任务的处理过程: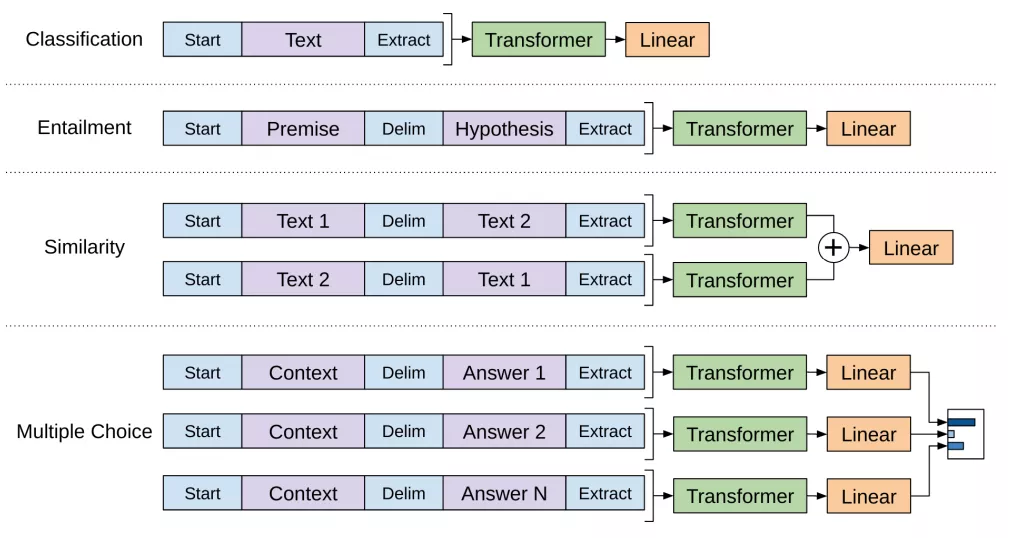 我们仔细看看上面这幅图,对于不同任务,处理的方式不同,例如文本分类任务,我们直接在预训练模型基础上微调输入线性输出层即可;对于文本蕴涵任务,将前提 p 和假设 h 序列连在一起,中间有一个分隔符($);对于相似性任务,被比较的两个句子没有固有的排序,为了反映这一点,修改输入序列,使其包含两种可能的句子排序(在两者之间有一个定界符),并对每一个序列进行独立处理,以产生两个序列表示,在输入线性输出层之前,按元素添加;对于问题回答和常识推理任务,有一个上下文文档 z 、一个问题 q和一组可能的答案{ak} 。我们将文档上下文和问题与每一个可能的答案组合,组合时中间加一个分隔符,得到 [z; q; $; ak],如上图,这些序列中的每一个都是用模型独立处理的,然后通过一个softmax层,在可能的答案上产生一个输出分布。GPT在当时的多项NLP任务中都达到了当时最好的效果。
我们仔细看看上面这幅图,对于不同任务,处理的方式不同,例如文本分类任务,我们直接在预训练模型基础上微调输入线性输出层即可;对于文本蕴涵任务,将前提 p 和假设 h 序列连在一起,中间有一个分隔符($);对于相似性任务,被比较的两个句子没有固有的排序,为了反映这一点,修改输入序列,使其包含两种可能的句子排序(在两者之间有一个定界符),并对每一个序列进行独立处理,以产生两个序列表示,在输入线性输出层之前,按元素添加;对于问题回答和常识推理任务,有一个上下文文档 z 、一个问题 q和一组可能的答案{ak} 。我们将文档上下文和问题与每一个可能的答案组合,组合时中间加一个分隔符,得到 [z; q; $; ak],如上图,这些序列中的每一个都是用模型独立处理的,然后通过一个softmax层,在可能的答案上产生一个输出分布。GPT在当时的多项NLP任务中都达到了当时最好的效果。
下面分别是自然语言推理任务和问题回答和常识推理任务:
下图是语义相似性和文本分类任务: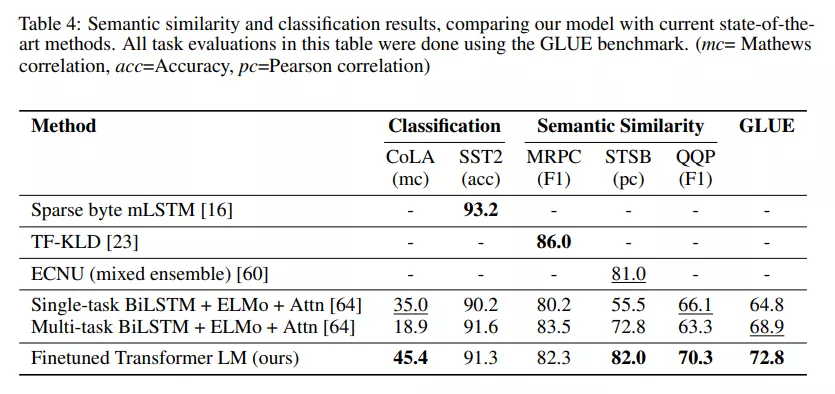
关于GPT为什么没有BERT效果好的问题,我们在之前的文章中已经写过:面了一个工作3年程序员,这些常见面试题竟一个都答不出来!相信讲完GPT的内容后,大家对本文开始的那些问题都可以回答啦~
扫码下图关注我们不会让你失望!


