昨晚和一个朋友吃饭,他是一家公司的部门技术负责人,因为我们都是做自然语言处理的,我问他最近找工作的应该挺多的吧,他点了点头,然后和我吐槽前两天面试的一个工作3年的程序员,原来是做NLP的,这次也是面试NLP工程师,问到BERT,竟然一问三不知!我问这个朋友,你当时问了哪些问题?他说是以下几个:
1. BERT为什么效果这么好?
2. 同是“双向”的,ELMo和BERT有啥区别?
3. BERT的MASK语料具体如何处理的?
我想,这些确实不算难,接触过BERT的人都应该知道。
BERT是近年来NLP领域备受关注的顶流了!BERT发表于论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,作者来自谷歌。
BERT是Bidirectional Encoder Representations from Transformers的缩写,BERT在11项NLP任务上刷新了记录,并且相比原有最好成绩提升了很多!
BERT使用了Transformer作为其主要框架,关于Transformer,我们之前详细讲解过了:今日头条面试,这几个坑爹问题让我与50w年薪擦肩而过...,所以BERT有着更彻底的双向训练语言模型,能够更好捕获语句的上下文信息。BERT使用了Mask Language Model(MLM)这一技术,使得BERT能够训练双向语言模型。除此之外,BERT使用了更多机器和更多语料训练模型。
BERT使用Transformer的Encoder部分,和Transformer一样,彻底抛弃了RNN结构,可以并行加速。

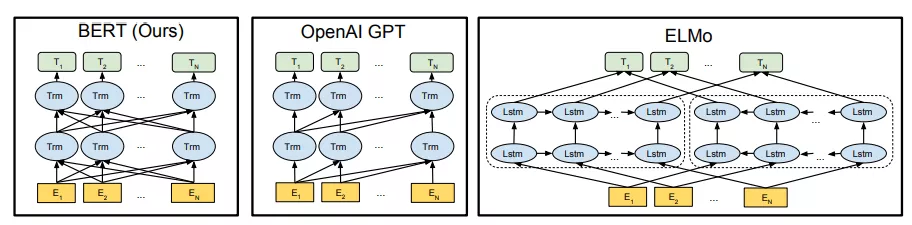
在之前,我们提到过ELMo,虽然都说是“双向”的,但目标函数其实是不同的。ELMo是分别以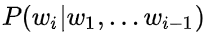 和
和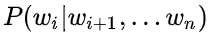 作为目标函数,训练后拼接在一起,而BERT则是以
作为目标函数,训练后拼接在一起,而BERT则是以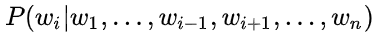 直接作为目标函数训练,所以可以理解为BERT是真正的双向!
直接作为目标函数训练,所以可以理解为BERT是真正的双向!
Embedding
对于一个给定的token,输入可以表示为WordPiece 嵌入、分割嵌入和位置嵌入。
WordPiece 嵌入:指将单词划分成一组有限的公共子词,能在单词的有效性和字符的灵活性之间取得一个折中的平衡,例如下图第一行中的‘playing’被拆分成了‘play’和‘ing’。
位置嵌入(Position Embedding):位置嵌入是指将单词的位置信息编码成特征向量,这些特征向量可以代表单词的位置关系,类似之前Transformer中的位置向量,但是使用的并不是三角函数生成位置向量。
分割嵌入(Segment Embedding):用于区分两个句子。
三种嵌入对应位置相加,如下图所示:
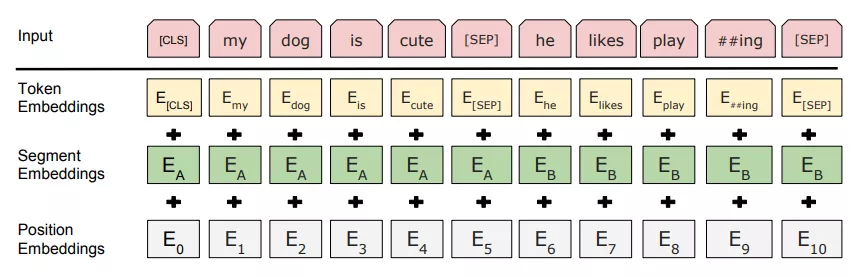
在BERT中,句子的第一个token是一个特殊的用来标记分类的token([CLS]),[SEP]表示分句符号,用于分隔不同的句子。
BERT的Masked LM
在BERT中,随机MASK掉语料中15%的token,然后来预测这些token,这很像我们做过的完形填空。又因为这个MASK的特殊标记在NLP的下游任务中不存在,为了和下游任务保持一致,作者按照如下的比例将原始15%MASK的位置替换如下,例如对于“my doy is hairy”这句话:
有80%的概率用[MASK]标记来替换,替换后:“my dog is [MASK]"
有10%的概率用随机的一个单词(token)来替换,替换后:“my doy is apple”
有10%的概率不做替换,仍然为:“my doy is hairy”
BERT的Next Sentence Prediction (NSP) 下一句预测
BERT为了让下游的问答(QA)和自然语言推理(NLI)任务能够进行,增加了另一个预训练任务,在 BERT 的训练过程中,模型将两个句子为一对作为输入,预测第二个句子是否在原始文档中是第一句的后续句子。
其中,50% 的输入句子对是在原始文档中确实是前后句子关系(标注为IsNext),而另50% 中的第一个句子的下一句是从语料库中随机选择的(标注为NotNext),如下图所示:

微调(Fine-tuning)
在大量语料上训练完BERT之后,就可以将预训练的BERT应用在各个任务中了,在BERT的基础上增加一个输出层,就可以对特定任务微调,如下图所示, 表示第
表示第  个Token在经过BERT处理之后得到的特征向量。
个Token在经过BERT处理之后得到的特征向量。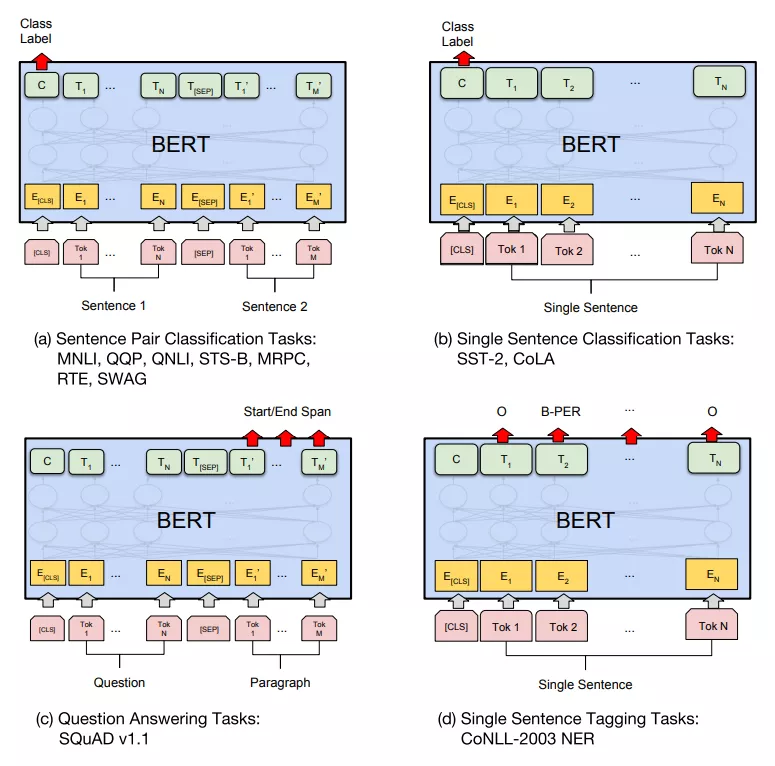
例如我们做的是分类任务,我们需要做以下操作:
在 BERT的输出上添加一个分类层(用某维度矩阵乘以输出向量,将其转换为分类类别的维度),用 softmax 计算每个类别的概率。
论文使用了两种模型:
BERT(BASE): L=12, H=768, A=12, Total Parameters=110M
BERT(LARGE): L=24, H=1024, A=16, Total Parameters=340M
这里 L 是 layers 层数(也就是Transformer 中编码器部分的blocks个数),H是词向量Embedding的维度, A 是多头self-attention 的“头数”。
最后看看BERT在各个任务上的表现吧,各种碾压了!
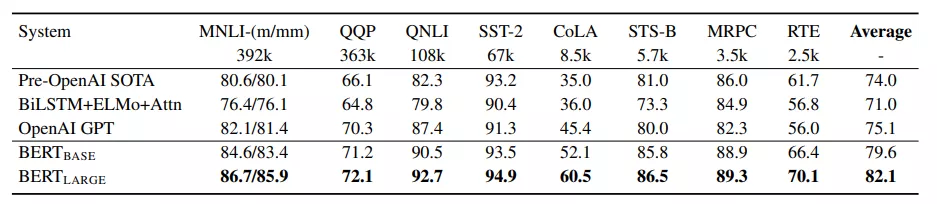

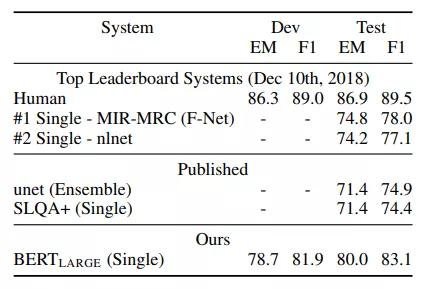

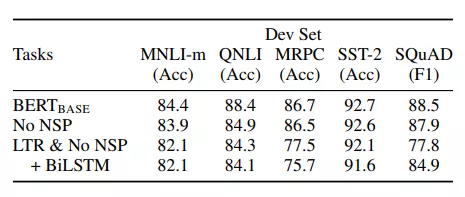
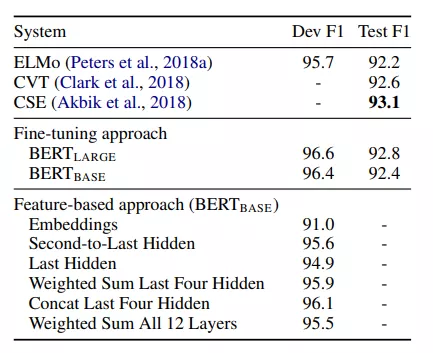
相信文章开头的面试题大家心里都有答案了~
