前言
前文传送门:
【解读】从官方Titanic案例打开kaggle机器学习之路(上)
【解读】从官方Titanic案例打开kaggle机器学习之路(中)
模型,预测和解决问题
现在我们准备好训练一个模型并且用它做预测来解决问题。有60多种预测模型可以选择。我们必须了解问题类型和求解要求以便缩小选择空间,选择少数几个模型做预测。
我们的问题是分类和回归问题。我们想要确定输出情况(生存与否)和一些变量特征(性别,年龄,登船港口等)之间的关系。
我们正在做的机器学习是有监督的,因为我们正在使用给定的数据集来训练我们的模型。
有了这两个标准 —— 监督学习 加 分类&回归,我们可以将我们的模型选择缩小到几个。 这些包括:
1. 逻辑斯特回归(Logistic回归)
2. KNN
3. 支持向量机(SVM)
4. 朴素贝叶斯
5. 决策树
6. 随机森林
7. 感知器
8. 人工神经网络
9. RVM

Logistic回归
Logistic回归是在工作流程早期运行的有用模型。 逻辑回归通过使用逻辑函数估计概率来度量分类因变量(特征)与一个或多个自变量(特征)之间的关系,该逻辑函数是累积逻辑分布(参考维基百科)。

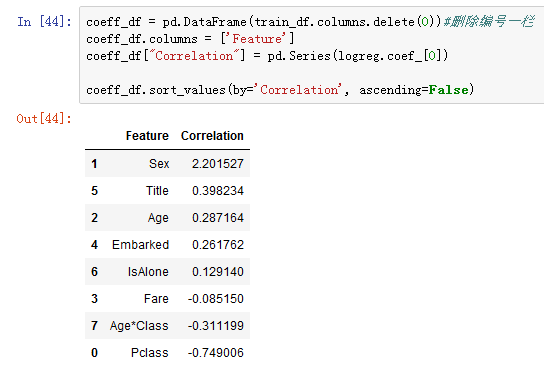
我们可以使用Logistic回归来验证我们对特征创建和完成目标的假设和决策,这可以通过计算决策函数中的相关系数来完成。
正相关系数增加了响应的对数几率(从而增加了概率),负相关系数会降低响应的对数几率(从而降低概率)。
性别有着最高的正相关系数,意味着性别特征值增加(男性:0,女性:1),生存几率增加最多。
反之,仓位增加,生存几率下降越快。
Age * Class是一个很好的人造特征,因为它与生存几率具有第二高的负相关性。
称谓是第二高的正相关性。
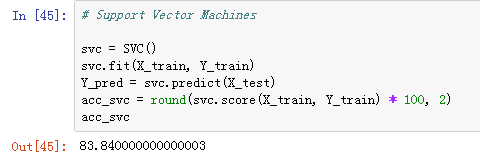
支持向量机
接下来,我们使用支持向量机进行建模,所述支持向量机是具有关联学习算法的监督学习模型,用于分类和回归分析的数据。
给定一组训练样本,每个样本标记为属于两个类别中的一个或另一个,SVM训练算法建立一个模型,将新的测试样本分配给一个类别或另一个类别,使其成为非概率二元线性分类器(参考维基百科)。
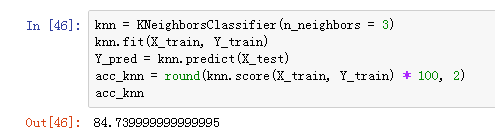
KNN算法
在模式识别领域中,k-最近邻居算法(简称k-NN)是一种用于分类和回归的无参数方法。
样本通过邻居的多数投票进行分类,样本被分配到k个最近邻居中最常见的类别(k是一个正整数,通常很小)。
如果k = 1,则将该对象简单地分配给该单个最近邻居的类别。(参考维基百科)。
朴素贝叶斯
在机器学习中,朴素贝叶斯分类器是一组简单的概率分类器。
它基于运用贝叶斯定理和特征之间强大(朴素一词的含义)的独立性假设。
朴素贝叶斯分类器具有高度可扩展性,在学习训练中需要许多变量(特征)的参数(参考维基百科)。

感知器
感知器是用于二元分类器的监督学习的算法(函数可以由各种输入决定,输入可以是数字向量,属于某个特定类别的类型)。
它是一种线性分类器,即一种分类算法,它基于将一组权重与特征向量相结合的线性预测函数进行预测。
该算法允许在线学习,因为它一次处理训练集中的元素(参考维基百科)。

线性SVC

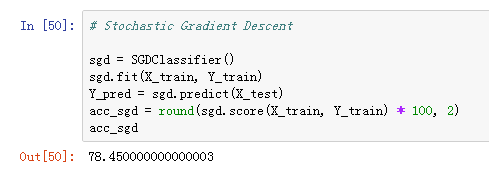
随机梯度下降
决策树
该模型使用决策树作为预测模型,将特征(树分支)映射为关于目标值(树叶)的结论。
目标变量可以采用有限的一组值的树模型称为分类树; 在这些树结构中,叶代表类标签,分支代表通往这些类标签的特征的连接。
目标变量可以采用连续值(通常是实数)的决策树被称为回归树(参考维基百科)。

随机森林
下一个模型——随机森林是最受欢迎的模型之一。
随机森林或随机决策森林是一种用于分类,回归和其他任务的集合学习方法,
通过在训练时构造多个决策树并将输出取为各个树的类(分类)模式或平均预测(回归)的类(参考维基百科)。

迄今为止评估的模型中,随机森林模型置信度得分最高。 我们决定使用这个模型的输出(Y_pred)来创建竞赛结果提交。
模型评估
我们现在可以对所有使用的模型进行评估,以便为我们的问题选择最好的模型。
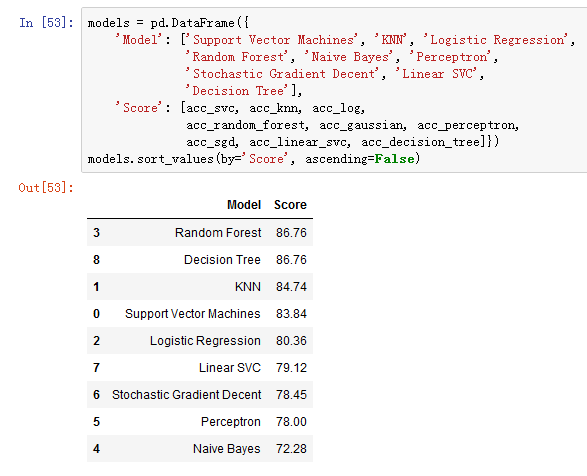
虽然决策树和随机森林评分都相同,但我们选择使用随机森林来纠正决策树过拟合训练集的可能。

......
我们提交给竞赛网站Kaggle的结果是在6,082项参赛作品中得到3,883名。
这个结果在比赛进行时是指示性的。 该结果仅占提交数据集的一部分。
我们的第一次尝试不错。 任何建议,以提高我们的分数都是受欢迎的。
参考文献
1. A journey through Titanic
2. Getting Started with Pandas: Kaggle's Titanic Competition
3. Titanic Best Working Classifier
写本文(翻译+整理)的目的:
哈哈,本次的kaggle入门之旅结束啦,你学会kaggle竞赛的常见流程了么?
无非是:数据探索(可视化等)——特征工程(特征筛选,缺失值填充,生成新特征)——数据建模(选择合适算法)——提交结果
希望本文翻译对你的kaggle入门有帮助啦~

