如在上篇文章《ETL调优的一些分享(上)》中已介绍的,ETL是构建数据仓库的必经一环,它的执行性能对于数据仓库构建性能有重要意义,因此对它进行有效的调优将十分重要。ETL业务的调优可以从若干思路开展,上文我们已经介绍了其中三点,本文我们将再分享如下几点建议。
减少不必要的事务表的使用
减少事务性操作的窗口时间
从最影响总体性能的case开始分析
步骤迭代,直至最优
减少不必要的事务表的使用
由于ORC事务表读取和操作较慢,为确保执行效率,对于业务中不涉及事务操作的表,建议使用普通ORC表,而非ORC事务表。另外,必要时建议手动进行Major compact,可以减少因Delta文件过多导致的查询速度慢的问题。
Case Study:
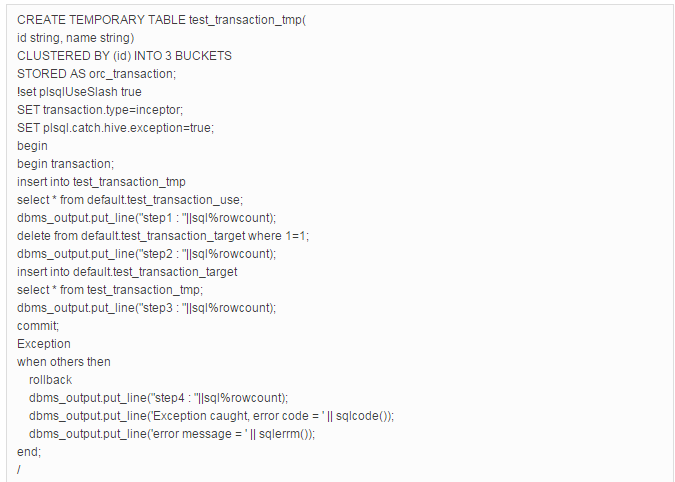
该案例中的业务人员将此语句中临时表test_transaction_tmp建成了事务表。但是分析业务发现,test_transaction_tmp表仅仅进行了insert into和查询操作,并未进行update/delete/merge等事务性操作,完全可以用普通ORC表替代。替代后的读取速度会比事务ORC表快,并会减少因事务性操作带来的干扰。
减少事务性操作的窗口时间
Inceptor的事务性实现是基于表级锁,而非行级锁。所以在高并发业务场景下,减少事务性操作的互斥区域的执行时间就很重要。优化业务性能时应该优先考虑这部分的时间。
Case Study:SQL同上节。
由上述SQL可见,对于事务表test_transaction_target的事务操作,从语句“delete from default.test_transaction_target where 1=1;”开始,拿到表test_transaction_target的锁,直至commit语句执行完才会释放。所以高并发场景下就会遇到类似这种互斥区域带来的串行问题。为了减少因事务性功能的互斥实现导致的串行问题影响,需要重点优化从delete from语句开始,到commit语句结束,此窗口的SQL执行总时间,减少因串行带来的影响。
从最影响总体性能的Case开始分析
处理了前五步(包括上文的三步)的影响因素后,接下来对执行依然很慢的业务,需要从耗时的业务开始进行case by case的迭代分析。
首先通过Explain检查执行计划的合理性。如查看过滤下推是否成功,Join顺序是否合理等。对于过滤下推的检查,若处于未被Inceptor优化覆盖的场景,可通过适当手工修改SQL解决。Join顺序的问题,在之前收集的数据特征的基础上,判断Join顺序是否合理,如大表和大表先Join即为不合理的情况。对于此类情况,可以考虑enable CBO来统一解决Join顺序问题。另外,如果在多表Join的案例中发现Join过程较慢,并发度不高,需要考虑是否应该disable MapJoin。一般来说,大表很大时,为节省Shuffle effort,优先默认使用MapJoin。对于中小表同多个小表Join,为提升并发度,减少MapJoin的串行执行影响,可以考虑关掉autoconvert开关。
其次,确定执行计划无误之后,可以进一步通过jstack观察执行热点,进一步定位性能瓶颈。
迭代步骤,直至最优
不断迭代上步,参考语句的性能分析(例如观察Inceptor的4040界面),发现性能瓶颈并解决。直至总体性能满足要求。
总结
我们通过上次和本次两篇文章分享了一些关于ETL调优的经验想法,这些都是从生产实施实践中所总结出的,希望在提升数仓构建的整体效率的过程中,各个读者能从这些思路获得帮助。
————————
往期回顾:
ETL调优的一些分享(上)
从阅读量看大数据技术关注热点
技术 | 如何让Kafka集群免受黑客攻击
关于:本文由公众号大数据开放实验室原创
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。
————————
