CBO概述
CBO 全称是Cost Based Optimization(基于代价的优化方式),是针对SQL执行计划进行优化的重要工具。CBO最初由开源Hive在0.14版本基于Apache Calcite项目引入,星环以此为基础对开源Hive CBO进行了功能增强和扩展,在Inceptor中实现了Inceptor CBO,进一步提升SQL兼容性和执行性能。
与Hive中原有的主要基于RBO(Rule Based Optimization)的优化器相比,Inceptor CBO优化框架通过Join Reordering、Bush Join Tree Generation等优化手段,对经过特殊转换后的执行计划进行了等价关系代数变换,对可能的等价执行计划,估算出量化的计划代价,最终选择出代价最小的作为最终的执行计划。
举例来说,对于table_A、table_B、table_C三张表的内关联,若提供如下两种执行顺序:1.table_A INNER JOIN table_B INNER JOIN table_C”;2.table_A INNER JOIN table_C INNER JOIN table_B,如果前者的代价是1000,后者的代价是500,那么优化器会选择后者为最终执行计划。
进行实际生产时,如不采用CBO,SQL的优化通常依靠人工重写语句。CBO优化器的优点体现在当面临大型数仓业务部署时,若采用原始手工方式修改海量业务层的SQL,代价将十分高昂,而CBO优化器则能够自动对执行计划进行评估和优化,不需要手动干预业务逻辑,比如更改JOIN顺序、加MapJoin Hint等,就可以在提供最优性能的同时,实现SQL业务的迁移并节省大量的部署时间。
Inceptor CBO目前最常用于多表JOIN案例的执行计划优化,可支持ORC和MEM表,支持数据分区分桶,可应对广泛的业务场景。我们将通过两篇系列文章分别介绍CBO优化器的使用方法和应用案例。本文将介绍CBO的使用方法和优化性能。
CBO的使用方法
第一步:收集统计信息
如开篇介绍,CBO是利用统计信息进行执行计划代价计算的,所以为了CBO的有效运行,用户必须在CBO优化之前进行信息收集工作。
Inceptor提供了以下两种方式实现统计信息收集:1. ANALYZE语句;2. 脚本工具preanalyze.sh。后者更常用,而且也更推荐使用。
ANALYZE语句可用于收集表级和列级的信息。表级信息指如numRows(表的行数)等关于整张表的信息。列级信息,指如NDV(Number of Distinct Values)等关于特定字段的信息。
ANALYZE的基本语法如下:

由于ANALYZE的结果服务于CBO优化,所以我们需要根据待执行的SQL语句,找到其统计信息对语句优化有帮助的对象,针对性的对这些对象进行分析。从而加快有效信息的统计,帮助提升信息收集的效率。
但是手动构造ANALYZE命令时,如果待优化的SQL语句十分复杂,用户可能需要在分析语句、选择分析对象、语句编写上花费很多时间和精力。所以建议使用下面的Preanalyze工具。
为了解放用户为编写ANALYZE语句付出的劳动力,提高对分析对象选择的准确性,Inceptor提供了脚本工具Preanalyze,以实现一键生成ANALYZE语句。
Preanalyze随Inceptor自动安装,具有分析待运行SQL语句,并根据分析结果自动生成ANALYZE命令且执行的能力。Preanalyze以SQL文件或者包含SQL文件的目录为分析对象。下面将介绍Preanalyze的使用方法。
Preanalyze是一个名为preanalyze.sh脚本工具,在TDH安装成功后,可以在此目录中找到它:

进入该目录,用形式如下的命令执行preanalyze.sh脚本:
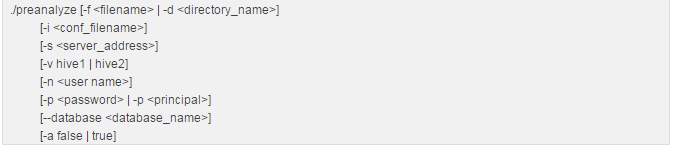
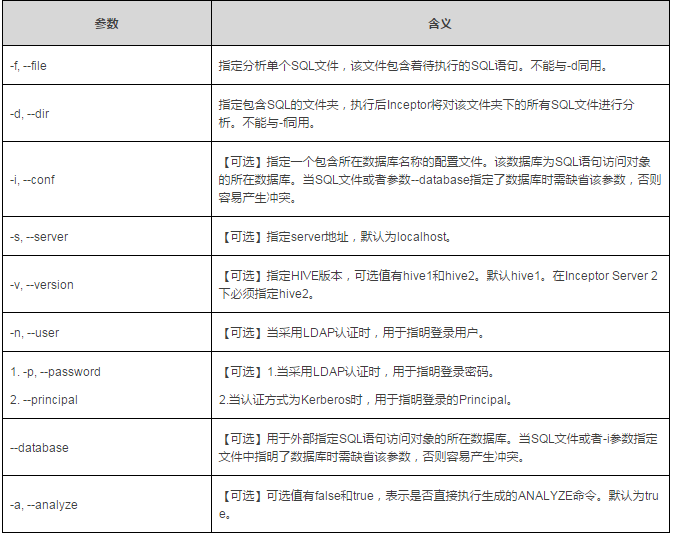
其支持的参数和对应含义如下:
Preanalyze可根据SQL语句生成表级和列级的ANALYZE语句,生成的语句被放在形如“username_analyzeResult_<某随机数>”的目录下,<某随机数>是一个三位-五位的随机数,用以区分不同的分析结果。该目录包含着名称为“<被分析文件名>.cmd”的文件以及一个all.merged.cmd文件。“<被分析文件名>.cmd”中的内容是根据<被分析文件名>.sql中的SQL语句生成的ANALYZE指令,all.merged.cmd文件是“<被分析文件名>.cmd”的汇总,是最终被Inceptor执行的文件。
下面是关于preanalyze.sh的使用示例。
【例1】分析getUsers.sql文件,获得统计信息,并执行。其中该文件已指明了语句访问对象的所在数据库:

其执行结果被放在目录root_analyzeResult_898,下图展示了该目录的文件。

由于只分析getUser.sql一个文件,所以all.merged.cmd和getUsers.sql.cmd的内容相同。
【例2】分析sqls文件夹下的所有文件,通过my.conf文件指明相关数据库,应执行如下语句:

my.conf文件中包含语句“USE <database_name>”,指定了访问对象所在数据库。sqls文件夹中存放着getUsers.sql和getUserNames两个文件,上面的语句表示分别对这两个文件进行分析,结果放在目录root_analyzeResult_13553下,下图展示了结果目录中的文件。

由于分析了多个文件,所以all.merged.cmd是getUsers.sql.cmd和getUserNames.sql.cmd内容的汇总,并会移除其中重复的语句和被分析对象。
【例3】分析指定getUsers.sql文件的信息,通过my.conf指定数据库,并执行,命令为:

【例4】下面的命令将分析sqls文件夹下的SQL文件信息,不执行:

该指令通过--database外部指定相关数据库,分析./sqls下的所有SQL文件,并通过“-a false”表明不要求立即执行生成的ANALYZE命令。
【例5】使用HIVE2+Kerberos方式执行preanalyze.sh,对./files文件夹进行分析,通过conf文件指明数据库,并执行:

在Inceptor Server 2中必须通过身份认证才能对目标对象进行分析。上述语句利用-v hive2切换至HIVE2版本,并用principal名称hive来验证身份。
Hive2中的身份验证
如有需要,用户可以自定义preanalyze.sh中的变量HIVE_CMD来指定认证方式。
Preanalyze的使用注意事项
1. -f 和-d 参数不能同时出现,且必须定义二者之一。
2. 要求必须指定数据库,有以下三种方式:
将“USE <database_name>”写入某个配置文件中,并用-i参数指定该配置文件;
在待分析的SQL中通过语句“USE <database_name>”指定;
使用--database 外部指定。
3. 不能对DDL生成ANALYZE命令,也没有实际意义。建议将DDL和DML分开放在不同文件。
4. 暂不支持带WITH-AS的SQL,需要手动剔除这些SQL。
5. 目前暂不支持对指定分区生成ANALYZE命令。
6. 实际使用中会有一些因素影响preanalyze.sh的运行,例如被分析语句中存在语法错误、没有去除WITH-AS子句或者LDAP/Kerberos认证失败,这些情况会导致preanalyze.sh分析过程失败。失败时,preanalyze.sh将根据具体情况作出应对,可能会退化为全表级的分析,或者在交互界面提示失败。
第二步:打开CBO开关

性能表现
下图提供了Hive CBO和Inceptor CBO在处理TPC-DS部分语句时的性能对比。
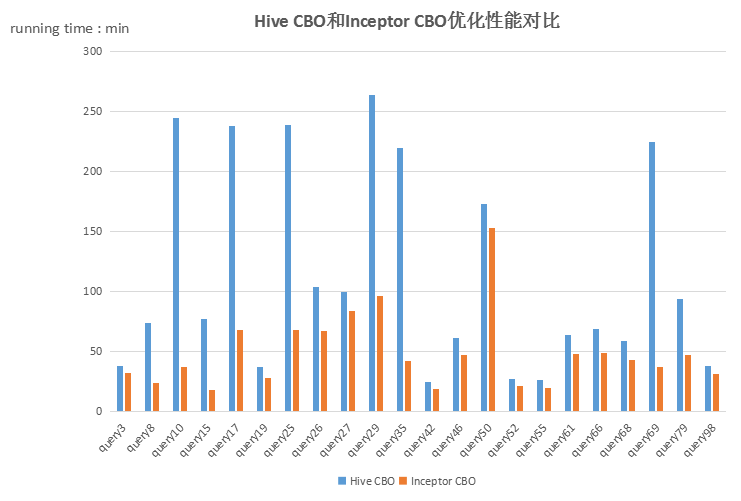
性能提升方面,开源Hive的报告显示,Hive CBO优化器使TPC-DS测试集的运行有平均2.5倍的性能提升。而同开源Hive CBO 相比,Inceptor CBO使接近10%的TPC-DS场景性能提升了3~4倍,接近20%的TPC-DS场景大约有40%的性能提升,约有80%的执行计划等于或接近最优计划。TPC-H的测试场景中,有多个场景可提供1倍左右的性能提升,部分场景最高可达3~4倍。在实际的海量数仓业务中,CBO也能够提供较好的优化性能。
总结
CBO是Inceptor中针对JOIN的重要且实用的优化器,由于很多SQL业务场景都会涉及JOIN关联操作,所以采用CBO优化对于处理海量数据以及面临数量庞大且复杂的业务时,能够有效且大幅节省时间开销。
本文对CBO的概念进行了讲解,并阐述了如何在使用它之前进行信息收集。另外,我们介绍了如何利用preanalyze脚本简化CBO的信息预收集过程,如何使CBO优化对于用户而言可用性和方便性更强。
下一节我们将继续介绍CBO,通过一则案例帮助读者了解需要在什么样的情况下使用CBO,具体应按照哪些步骤进行。以及CBO优化器在运行时会遇到哪些错误并提供对应的解决办法。
————————
往期回顾:
Transpedia的发布及其使用攻略
技术|Inceptor任务的图形化分析(三)
技术|Inceptor任务的图形化分析(二)
关于:本文由公众号大数据开放实验室原创
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。
————————
