
作者:数加大数据
DT时代人们想变美的心愿可以更快的被实现,可以实现的途径非常多,美颜相机、美妆教程、美妆直播。。。。。。数不胜数的变美途径可以让人们越来越美。有这么一个平台,让我们看看,他们是怎样利用数据,让大家变得更美。
说到的这家公司就是小红唇,想具体了解小红唇可以去官网了解,在这里要讲的是,小红唇是怎样利用数据,为千千万万想要变美的人们提供更加贴心的服务。
小红唇的数据之路要从他们的一个个性化功能需求提起。
随着小红唇业务的发展,用户量和内容量不断增加,迫切需要推出个性化功能,增加用户的使用时长和用户粘度。对于一个没有大数据/机器学习经验和技术储备,并且开发人员有限的年轻团队,在业务快速发展的情况下,如何在非常有限的开发资源和不影响正常业务开发的前提下,快速建立起自己的推荐系统,成为摆在小红唇技术团队面前一个不小的挑战。这便是小红唇和阿里云大数据数加平台的第一次牵手预热。
小红唇的技术团队在收到产品关于个性化推荐的需求后,开始了技术调研,其中包括了主流的开源技术栈和阿里云在2016年年初发布的数加平台。两位毫无大数据技术背景和经验的工程师并行化工作,都希望能快速切入到大数据的核心并快速产出。于是小红唇和大数据的第一次邂逅就这样不期的开始了,如同相亲,在众多的对象中,怎么找到合适的那一位一定是故事里精彩的部分。
在这第一次邂逅的比赛中,调研阿里云数加平台的工程师只用了一天时间,就利用阿里云数加平台的推荐引擎搭建起了推荐系统,该系统使用了业界流行的协同过滤算法,基于最新的用户对短视频的行为,计算出推荐列表。而另一位工程师还在熟悉陌生的大数据技术栈和编程语言。这第一次与阿里云大数据平台的邂逅堪称完美,在对仅用一天时间就搭建起来的推荐系统稍作修改,并设计了如何嵌入到自身业务系统中后,个性化推荐就和其他普通业务需求一样,在产品提出需求后的第一个发版中就快速上线了。整个推荐系统中数据采集,数据清洗,推荐计算以及结果获取如下图1所示。
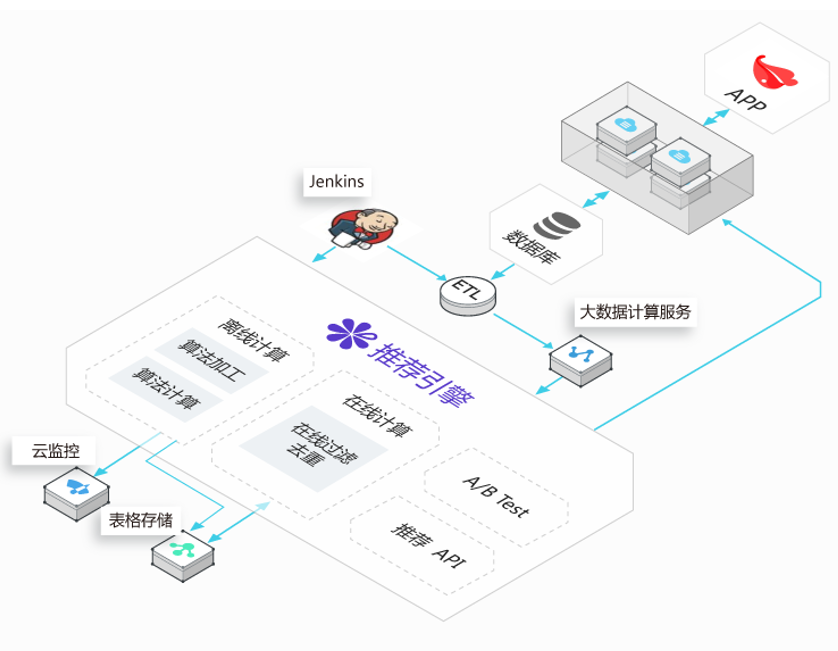
图1. 推荐系统架构图
在这个架构中,我们选择了非常流行的开源ETL 工具来对用户行为,物品,用户等推荐系统依赖的数据进行清洗,并按照推荐引擎要求的格式同步到大数据计算服务中。由持续集成工具Jenkins 触发数据的清洗和上传到数加MaxCompute(原名ODPS)中。推荐系统从大数据计算服务中获取数据并进行离线计算,计算的结果存储于阿里云的表格存储中,用于在线计算的结果二次处理和返回。业务服务器通过推荐系统暴露的推荐接口获取对某个用户的推荐列表。
我们是数加平台推荐引擎的第一批内测用户,得到了数加平台的大力的支持,使得整个推荐系统的接入都非常的顺利,也解答了很多关于大数据和推荐系统的小白问题。小红唇的团队在和数加平台的推荐引擎团队合作中快速的学习了大数据和推荐系统的相关知识,可以说是数加的推荐引擎为小红唇技术团队开启了大数据这扇神秘的大门。
这个架构简单清晰,但也有着很多不完美的地方,特别在数据的采集和清洗方面,还显得比较初级和脆弱。首先用户行为数据完全依赖了在APP中的埋点,而埋点的最初的设计也存在了一些问题导致数据缺失。另外,推荐引擎没有一个很好的触发机制,通过外部的持续集成工具Jenkins 的触发,在初期有时会遇到推荐引擎系统不稳定的问题,导致离线计算失败,用户的推荐列表没有得到及时的更新。
随着推荐系统的上线,小红唇也开启了大数据的探索之旅。得益于数加平台完整的大数据计算和应用设计,小红唇的技术团队在熟悉和上线推荐系统的过程中,也逐渐收获了大数据的核心理念,对大数据完整技术栈也有了更深的认识。
2016年是小红唇快速发展的一年,随着业务的不断增长,各种产品、市场运营活动的设计和决策也需要有各种各样的数据作为支撑了。于是在快速上线了推荐系统之后,摆在小红唇面前的另一个大数据挑战就是搭建自己的数据仓库。
在推荐系统的建设中,小红唇技术团队也意识到阿里云数加平台在普惠大数据理念上的前瞻性,整个数加平台产品线的布局对于像小红唇这样的初创公司,在大数据实践上是容易实现弯道超车的。
数据仓库的重要性毋庸置疑,在云计算和大数据时代,数据仓库的建设也在不断的进化中。开源生态中基于Hadoop/Hive搭建数据仓库的成功案例不胜枚举。数加平台基于MaxCompute的强大计算能力,也正是对这一理念的完美诠释。于是小红唇技术团队也在横向对比之后,毅然决定在数加平台上进行数据仓库的建设。
小红唇基于数加平台的数据仓库搭建分成了两个阶段。第一阶段由于主要的业务服务器并没有部署在阿里云上,使得数据的采集和清洗变得比较麻烦,跨网的数据传输和备份,各种周期任务比较复杂。如图2所示。
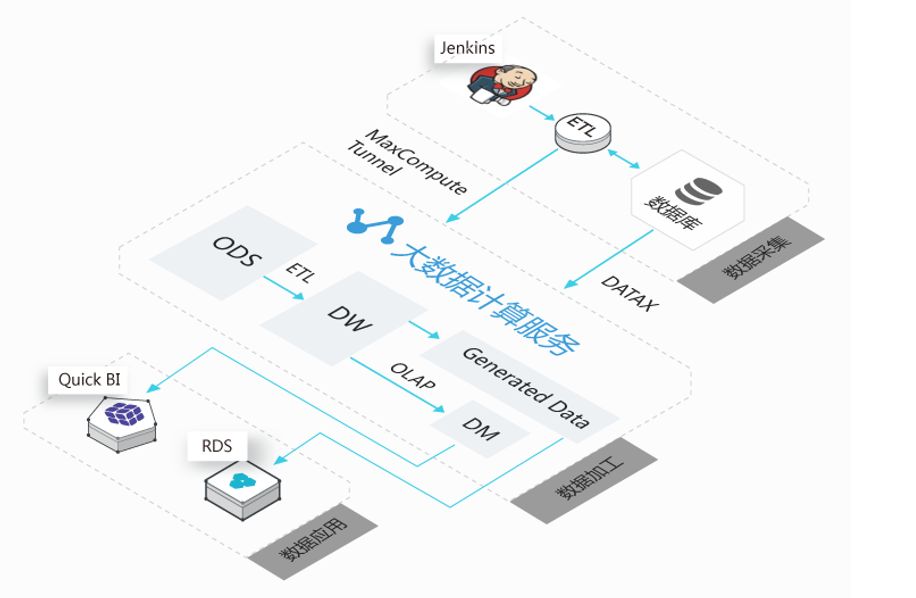
图2. 第一阶段数仓架构
在第一阶段的数仓建设中我们已经在计划业务服务器向阿里云搬迁了,所以把数据需求最紧要的数据做了向MaxCompute的同步(同步方式也有用DataX 和MaxCompute 的tunnel),在数据开发IDE中对数据进行ETL和OLAP,最后利用QuickBI产出BI报表。另外还有一些数据会应用到业务系统中,我们通过RDS 进行存储。
在数据仓库第一阶段的建设和使用中,我们已经在积极的筹备业务系统向阿里云的搬迁。随着搬迁的完成,我们也迅速开始了第二阶段的改造。同时更多的数加产品也在不断的内测和发布中,借助于新的产品和上下游的不断打通,我们的架构也进行了演进,如图3所示。
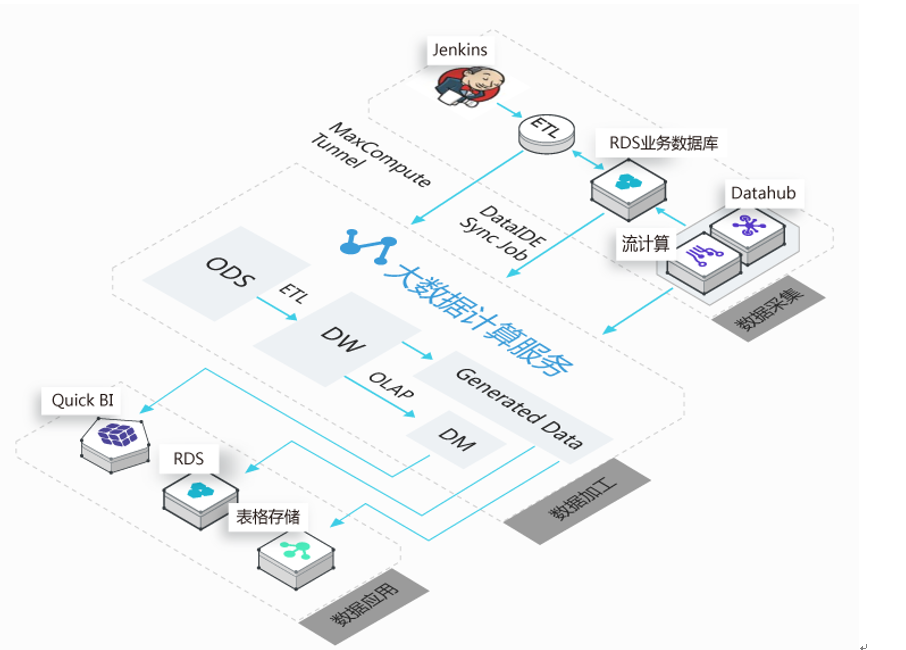
图3. 第二阶段数仓架构
第二阶段与第一阶段主要的区别就在于数据采集和清洗部分是否直接纳入在数加平台内部,而对于数据仓库的建设而言,这两个环节又是非常重要的部分。在第二阶段中,我们的业务数据库已经在阿里云的RDS上了,通过DataIDE就可以方便的把需要的数据同步到大数据开发平台中,这也是小红唇目前的架构。在把数据采集,数据清洗,数据开发和数据应用形成完整闭环后,小红唇在大数据领域的各种尝试和产出得到了巨大的发展:
首先,我们基于数据仓库的方法论在数加平台上建设的数据仓库,通过简单的命名规则就构建起各种层级和维度的数据,依赖MaxCompute的强大计算能力,和简单的SQL处理语言,小红唇技术团队只有一名数据工程师就能快速生产出各种数据,以支撑各种BI报表。
第二,流计算的引入,提高了小红唇业务的实时表达能力而又没有增大开发成本。对某些业务还起到了异步,解耦和降级的作用,大大降低了对线上已有的复杂业务的影响,因而降低了开发和维护成本。
第三,与机器学习算法平台PAI的对接也帮助了小红唇技术团队在机器学习等高难度领域大数据应用的探索,比如我们尝试了训练回归模型对用户上传视频的打分,还有对文本的处理聚类等。
第四,基于统一的数据存储和计算,我们通过对用户的特征抽取,开发了自己的一套基于内容的推荐模型(通过用户对内容的行为,在MaxCompute中通过SQL/MR的计算生成用户特征,通过DataX 存储在OTS 中,在实时的计算中获取并对用户进行基于兴趣的内容推荐),和阿里云推荐引擎一起,为用户提供个性化内容,也取得了不错的效果。同时也在智能搜索方面做了初步的尝试。
当然,小红唇在数加平台上的大数据实践也并非一帆风顺,期间也有对于产品理解和数加平台自身的一些问题,比如初期大量的数据搬运和同步工作掣肘了业务的快速开发,MaxCompute提供的算子不太丰富,需要自行开发udf(MaxCompute2.0将会有巨大的改进,同时更多的上下游产品被打通),初期数加平台和其它上下游产品打通不够等等。但是数加平台强大的计算能力和完整的产品布局对小红唇的业务扩展和决策支撑起到了关键的作用。
技术的不断进化和升级需要匹配业务的水平和规模,对于小红唇这样的初创企业,背靠阿里云强大的平台,能够快速应用新技术并得到价值的转化,实现弯道超车,并不断完善自身技术架构和能力,在不断的创新中得到发展。

