1、本文是4月18日(周二晚)数据挖掘快速上手之R语言实践的应用的课件;
2、4月18日谢佳标老师主讲《数据挖掘快速上手之R语言实践》直播地址:https://edu.hellobi.com/course/178/lessons (友情提醒:打开就可以看,建议PC端浏览器);
3、加微信直播管理员微信:hellobilive(请注明:公司+姓名+行业) ,可以进入到微信群跟老师交流;
直播中用到的代码:
# 利用xlsx包读取Excel数据
library(xlsx)
res<- read.xlsx("sample.xlsx",1)
res
# 利用XLConnect包读取Excel数据
rm(list=ls())
library(XLConnect)
wb <- loadWorkbook("sample.xlsx")
xlds <- readWorksheet(wb,"mysheet")
xlds
# 利用readxl包来读取Excel数据
library(readxl)
xlread <- read_excel("sample.xlsx",1)
xlread
### 数据变换 ###
library(ggplot2)
set.seed(1234)
dsmall <- diamonds[sample(1:nrow(diamonds),1000,replace = F),] #数据抽样
head(dsmall)
par(mfrow = c(1,2))
plot(density(dsmall$carat),main = "carat变量的正态分布曲线") # 绘制carat变量的正态分布曲线
plot(density(dsmall$price),main = "price变量的正态分布曲线") # 绘制price变量的正态分布曲线
par(mfrow = c(1,1))
par(mfrow = c(1,2))
plot(density(log(dsmall$carat)),main = "carat变量取对数后的正态分布曲线")
plot(density(log(dsmall$price)),main = "price变量取对数后的正态分布曲线")
par(mfrow = c(1,1))
# 可见,经过对数处理后,两者的正态分布密度曲线就对称很多
# 建立线性回归模型
fit1 <- lm(dsmall$price~dsmall$carat,data = dsmall) # 对原始变量进行建模
summary(fit1) # 查看模型详细结果
fit2 <-lm(log(dsmall$price)~log(dsmall$carat),data=dsmall) # 对两者进行曲对数后再建模
summary(fit2) # 查看模型结果
# 在散点图中 绘制拟合曲线
par(mfrow=c(1,2))
plot(dsmall$carat,dsmall$price,
main = "未处理的散点图及拟合直线")
abline(fit1,col="red",lwd=2)
plot(log(dsmall$carat),log(dsmall$price),
main = "取对数后的散点图及拟合直线")
abline(fit2,col="red",lwd=2)
par(mfrow=c(1,1))
#### 数据清洗 ###
# 以睡眠数据sleep为例识别缺失值
# 加载sleep数据集
data(sleep,package="VIM")
attach(sleep)
# 查看数据结构
# is.na( )判断变量Dream各值是否为缺失值,TRUE为缺失值,FALSE为非缺失值
is.na(Dream)
table(is.na(Dream))
# complete.cases( )判断变量Dream各值是否为缺失值,FALSE为缺失值,TRUE为非缺失值
complete.cases(Dream)
table(complete.cases(Dream))
# 探索缺失值模式
# 列表显示缺失值
# mice包中的md.pattern()函数
# 将函数应用到sleep数据集
library(mice)
md.pattern(sleep)
# 图形探究缺失数据
# aggr()函数
library(VIM)
aggr(sleep,prop=FALSE,numbers=TRUE)
# 直接删除缺失值
sleep_clean <- na.omit(sleep)
## 数据抽样 ####
# 简单抽样
# sample小例子
set.seed(1234)
# 创建对象x,有1~10组成
x <- seq(1,10);x
# 利用sample函数对x进行无放回抽样
a <- sample(x,8,replace=FALSE);a
# 利用sample函数对x进行有放回抽样
b <- sample(x,8,replace=TRUE);b
# 加载DMwR包
if(!require(DMwR)) install.packages("DMwR")
dat <- iris[, c(1, 2, 5)]
dat$Species <- factor(ifelse(dat$Species == "setosa","rare","common"))
table(dat$Species)
# 进行类失衡处理
# perc.over=600:表示少数样本数=50+50*600%=350
# perc.under=100:表示多数样本数(新增少数样本数*100%=300*100%=300)
newData <- SMOTE(Species ~ ., dat, perc.over = 600,perc.under=100)
table(newData$Species)
# perc.over=100:表示少数样本数=50+50*100%=100
# perc.under=200:表示多数样本数(新增少数样本数*200%=50*200%=100)
newData <- SMOTE(Species ~ ., dat, perc.over = 100,perc.under=200)
table(newData$Species)
### 哑变量处理 ###
customers <- data.frame(
id=c(10,20,30,40,50),
gender=c('male','female','female','male','female'),
mood=c('happy','sad','happy','sad','happy'),
outcome=c(1,1,0,0,0))
customers
library(caret)
# 哑变量处理
dmy <- dummyVars(" ~ .", data = customers)
trsf <- data.frame(predict(dmy, newdata = customers))
print(trsf)
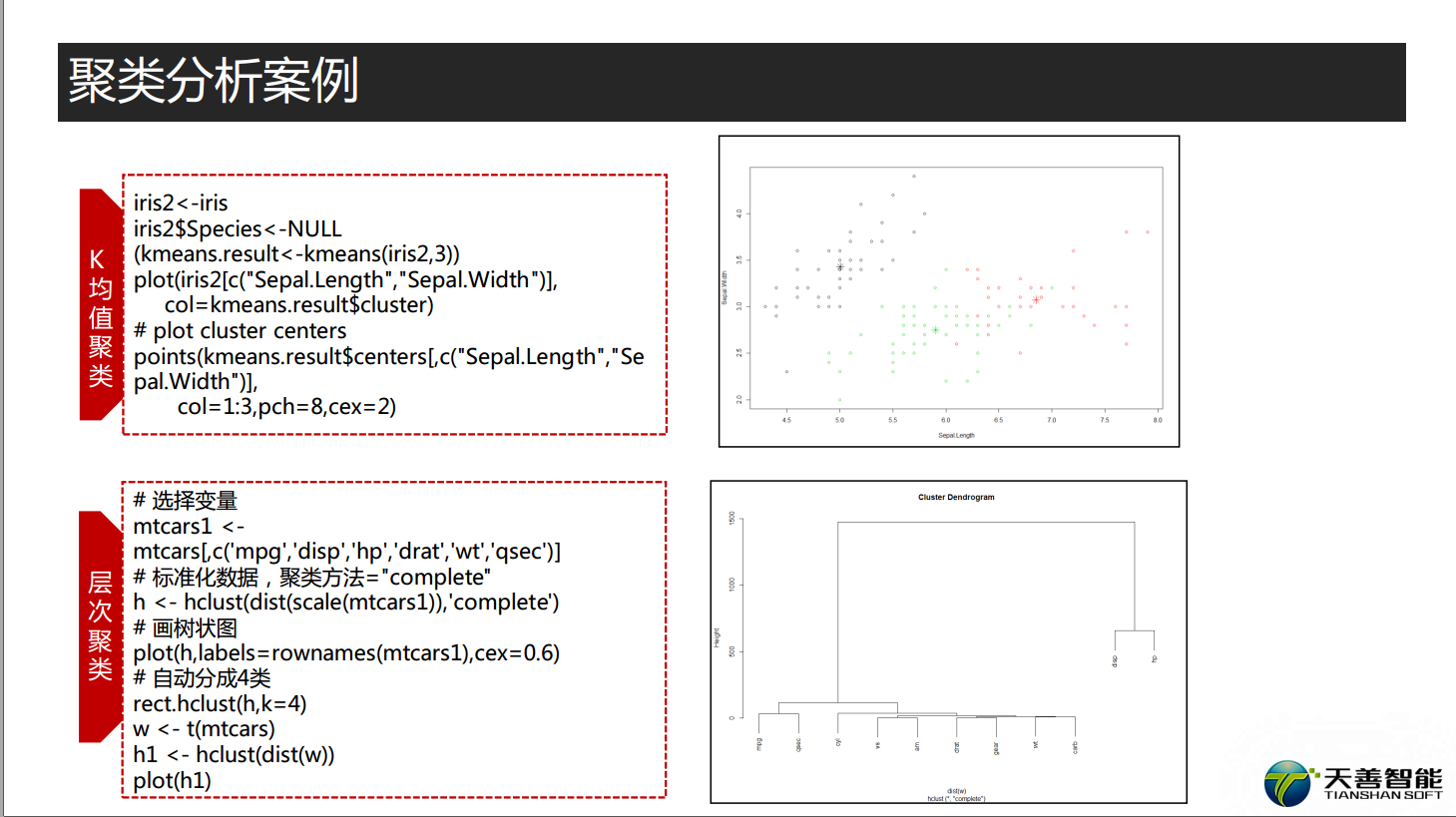
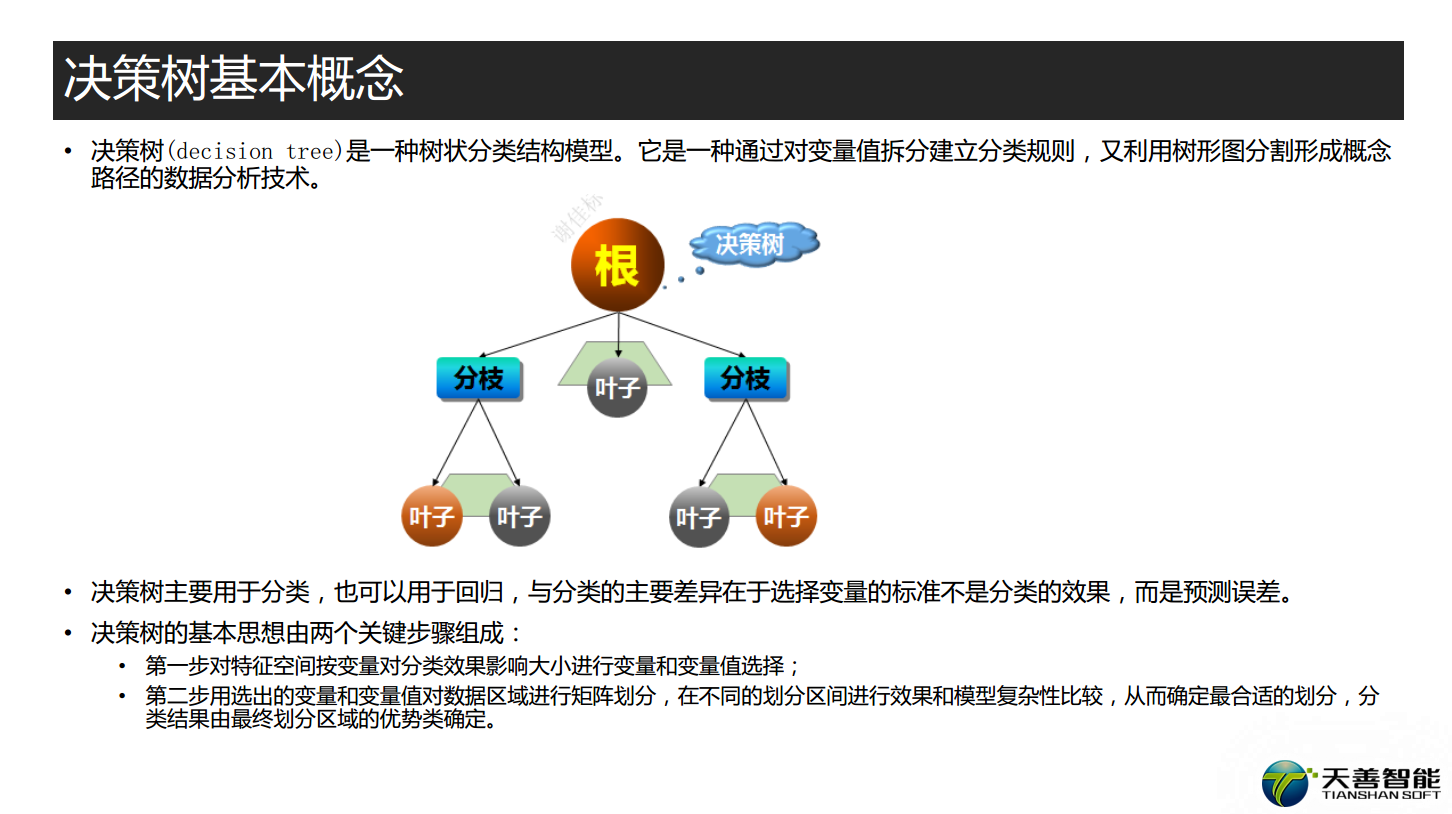
#### 聚类分析 ###
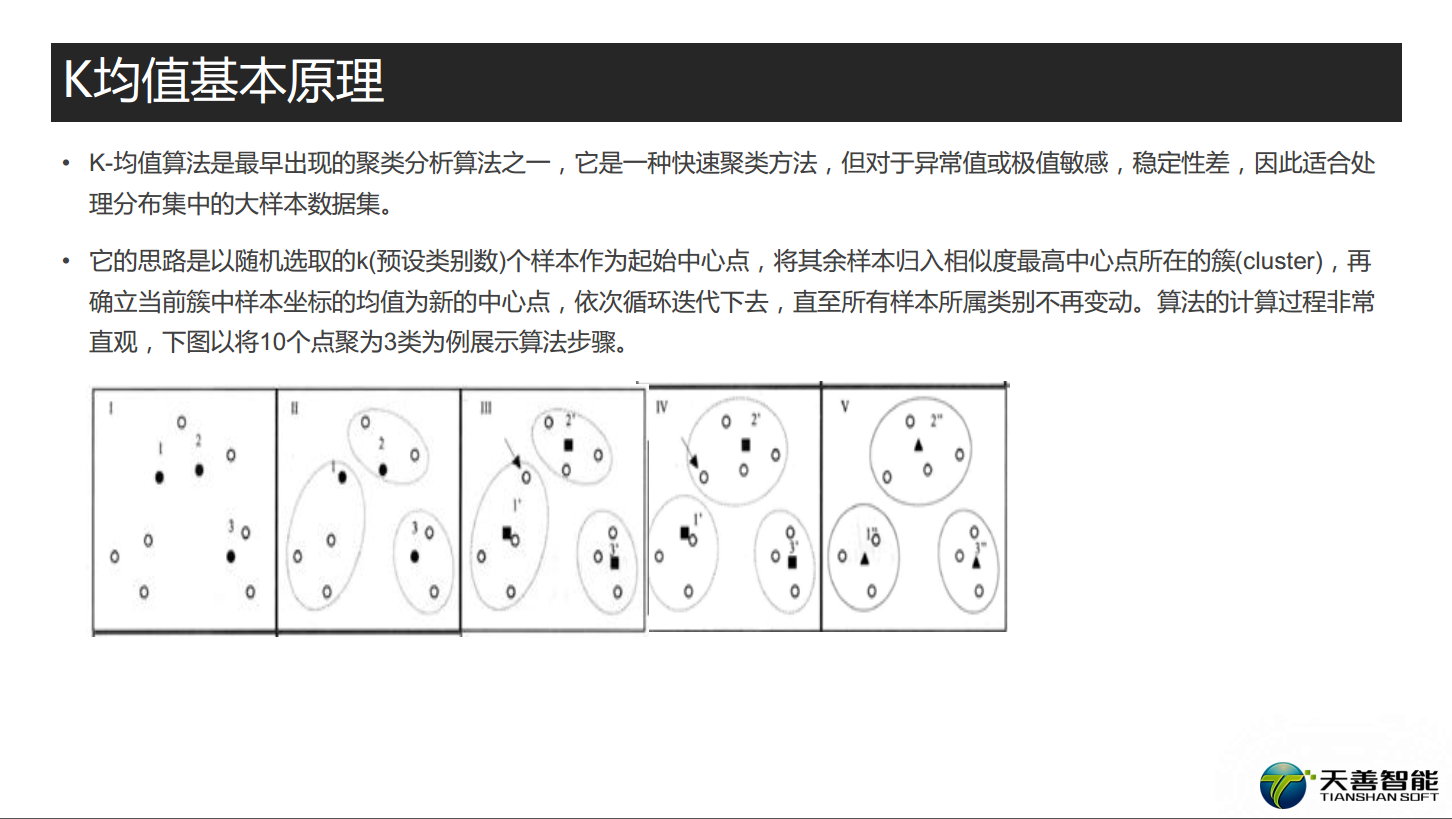
# 应用案例—K-均值聚类
# 在本例中,我们使用iris数据集演示k-means聚类的过程。
iris2<-iris
# 移除Species属性
iris2$Species<-NULL # 等价于 iris2 <- iris2[,1:4]
# 利用kmeans()函数进行k-means聚类,并将聚类结果储存在变量kmeans.result中。
(kmeans.result<-kmeans(iris2,3))
# 查看划分效果
table(iris$Species,kmeans.result$cluster)
# 然后,绘制所有的簇和簇中心。
plot(iris2[c("Sepal.Length","Sepal.Width")],
col=kmeans.result$cluster)
# plot cluster centers
points(kmeans.result$centers[,c("Sepal.Length","Sepal.Width")],
col=1:3,pch=8,cex=2)
#应用案例 mtcars数据集-层次聚类
# 选择变量
mtcars1 <- mtcars[,c('mpg','disp','hp','drat','wt','qsec')]
# 标准化数据,聚类方法="complete"
h <- hclust(dist(scale(mtcars1)),'complete')
# 画树状图
plot(h,labels=rownames(mtcars1),cex=0.6)
# 自动分成4类
rect.hclust(h,k=4)
w <- t(mtcars)
h1 <- hclust(dist(w))
plot(h1)
### 关联规则 ####
# 超市购物例子
# 数据理解
library(arules)
data(Groceries)
summary(Groceries)
# 查看前6项交易记录
inspect(Groceries[1:6])
# 也可以利用as函数将数据转换成data.frame格式
head(as(Groceries,"data.frame"))
# itemFrequency( )函数可以看到包含该商品的交易比例。
# 例如Groceries数据中前3件商品的支持度:
itemFrequency(Groceries[,1:3])
# 例如我们查看Groceries数据中商品whole milk、other vegetables的销售占比:
itemFrequency(Groceries[,c("whole milk","other vegetables")])
# 可视化商品的支持度—商品的频率图
# 使用itemFrequencyPlot( )函数
# 如果希望获得那些出现在最小交易比例中的商品,可以在itemFrequencyPlot( )函数中运用support参数:
itemFrequencyPlot(Groceries,support=0.1)
# 在itemFrequencyPlot( )函数中使用topN参数:
itemFrequencyPlot(Groceries,topN=20)
# 基于数据训练模型
# 采用默认设置:support=0.1和confidence=0.8
apriori(Groceries)
# 设置support=0.006,confidence=0.25,minlen=2
groceryrules <- apriori(Groceries,parameter =
list(support=0.006,confidence=0.25,minlen=2))
groceryrules
# 评估模型性能
# 使用summary( )查看更多信息
summary(groceryrules)
# 查看具体规则
inspect(groceryrules[1:3])
# 对关联规则集合排序
inspect(sort(groceryrules,by="lift")[1:5])
# 提取关联规则的子集
berryrules <- subset(groceryrules,items %in% "berries")
inspect(berryrules)
# 关联规则可视化
library(arulesViz)
plot(subset(groceryrules,lift > 3),method="graph")
课件: