公告
周五BI飞起来,每周一个主题,一场跟数据有关的行业、工具、技术的交流盛宴,锁定在每周五晚20:30,不见不散!
本期Friday BI Fly微信直播主题:大数据挖掘:系统方法与实例分析
预告一下未来几期的微信直播活动分享主题将包括谈谈BI在生产企业的应用、看大数据职位学数据场技能、数据科学家应用 、SPSS数据挖掘、腾讯大数据分析与挖掘应用、R语言实战、数据挖掘经典案例赏析等,具体日期安排请关注天善智能问答社区活动版块https://www.hellobi.com/events
主持人:加入本群的同学们,感谢大家参加由天善智能举办的 Friday BI Fly 活动,每周五微信直播,每周一个话题敬请关注。
【群规】本群为商业智能和大数据行业、技术、工具的交流学习群。不准发广告,只能发红包,发广告者一律移除微信群。
本次微信直播讨论内容
1. 数据挖掘流程
2. 数据预处理方法和技术
3. 数据挖掘应用案例
本期嘉宾介绍
卓金武
MathWorks中国科学计算业务总监 《大数据挖掘:系统方法与实例分析》 作者,主要负责数据挖掘、优化、量化投资、风险管理等科学计算业务,已为工行、交行、中投、华为、通用、一汽、上汽、格力等多家企业提供数据挖掘解决方案。
已有著作三部:《MATLAB在数学建模中的应用》(第一版和第二版),《量化投资:数据挖掘技术与实践(MATLAB版)》,《大数据挖掘:系统方法与实例分析》。
主持人:大家好,我是微信直播活动的主持人咖啡,每周一个主题,一场跟数据有关的行业、工具、技术的交流盛宴。我们的口号是“Friday BI Fly 周五BI飞起来”。
我认真的上网查了一下,The MathWorks是世界领先的技术计算和基于模型的设计的软件开发商和供应商。卓老师在里面做业务总监,又有数据挖掘建模方面的三本著作,我相信今天晚上的分享大家如果认真听,认真提问,一定会收获满满。下面我们就有请卓金武老师为我们大家带来下面的分享!
大数据挖掘:系统方法与实例分析

大家晚上好,感谢咖啡的介绍,非常荣幸能够有机会与这么多数据挖掘爱好者或从业者一起交流,希望今天的交流能让大家有所收获。抛砖引玉啊,我先分享一下工业大数据挖掘的实现过程。
现在大家都知道大数据有用,但究竟如何去应用大数据对很对人来说都很困惑。大数据的落脚点还是要在于应用,如果不能从大数据中挖掘到有利于社会发展的知识,大数据也就没有意义了。
数据挖掘技术是从数据中挖掘有用知识的一门系统性的技术,刚好解决了数据利用的问题,所以数据挖掘与大数据便很自然地结合在一起了,所谓大数据挖掘。
大数据挖掘技术在工业界已经被应用,下面这幅图给出了大数据在几个典型行业的应用领域。

大数据挖掘是业务和技术和融合,纵观各个应用实例,大数据挖掘在各个领域的应用既有相同之处,又有各自不同的独特地方。
不同的是业务层面的需求,以及具体的数据预处理方法和最终的模型形式,而相同的则是大数据挖掘实施的方法论。
所以对于有意向了解大数据挖掘的朋友来说,首先要学习的就是这个方法论,只要能够掌握方法论,再结合具体的业务需求,就可以实施数据挖掘项目。
大数据挖掘的方法论
所谓大数据挖掘的方法论,分成几个层次:
第一层次,也是主方法论,就是数据挖掘实施的流程,如下图所示。

第二个层次就是各个环节的实施方法论,比如数据的准备遵循怎样的流程等等,关于数据挖掘的主流程和次级别的流程在在很多书籍或参考资料上都有介绍,就不再详解了。
这里将通过一个工业界的大数据挖掘实例来具体说明如何按照大数据挖掘的方法论来一步步实施具体的项目。
所介绍的案例是关于工业设备故障诊断(挖掘目标的定义)的,其原理是根据设备的运行记录、监控数据,对其运行的趋势进行预测,并对其可能存在的运行状态进行分类,故障诊断的实质就是一种模式识别,对机器设备的故障进行诊断的过程也就是该模式匹配,具体体现形式就是数据的分类。
对机械故障的诊断来说,首先就应当获取一些关于机组的运行参数,既要包括机器在正常运行以及平稳工作时的信息数据,也应当包括机器在出现故障时的一些监控数据或从各种传感器收集的数据。
在现场的监控系统中往往就会存在着相应的正常工作状态以及出现故障时的不同运行参数,而数据挖掘的任务就是从这些杂乱无章的信息样本库中找出其中所隐藏着的内在规律,并且从中提取能够识别故障的特征。
在对故障模式进行识别时可以采用较为成熟的相关分析理论,找到变量之间的关联关系,并最终得到分类所需要用到的有效变量,然后训练分类模型,从而最终达到分类的目的,
依据分类模型或规则,就可以对一些新来的数据进行判断,而且可以准确地对故障进行分类,找出故障所产生的原因和解决故障的正确方法,并可以对其他的设备进行故障预警。
MATLAB实现过程
下面介绍一下用MATLAB来具体实现的过程:
第一步:数据的收集与集成
案例中的数据,是关于170个设备样本的监控数据,每个设备有5个监测位(频道),每个位置都有一段时间的某个指标的测量数据。在MATLAB中,加载数据后,可以查看这些数据的概况。
load('data.mat');
第二步:探索数据, 这步比较关键,承上启下的作用
对设备监控数据进行挖掘的意义在于提前预警可能发生的设备故障,然而一般情况下,从监控数据中很难直接发现存在的潜在风险。这时就要对数据进行探索,探索数据中潜在的信息,本例中的数据探索过程也很具有典型性。本例中,探索数据的主要目的是寻找比较好的衍生变量,以更精确刻画设备的运行状态。
探索前,我们先将原始数据划分为正常设备监控数据和有故障的设备数据,这样,便于分析比较。
最有效的探索方式就是数据可视化,对于该案例,可以直接绘制设备监控数据的时序图。
figure,
subplot(2,1,1)
plot(time, goodSet)xlabel('Time [s]'),
ylabel('Acceleration [m/s^2]'),
title('No damage')
subplot(2,1,2)
plot(time, damageSet)
xlabel('Time [s]'),
ylabel('Acceleration [m/s^2]'),
title('Damage')
这些代码运行后,得到一幅图:
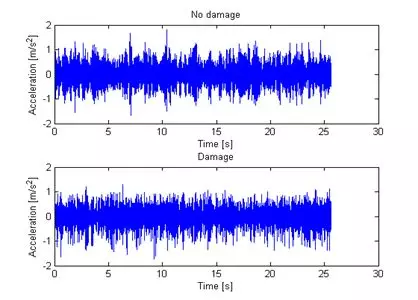
仅从这幅图很难发现它们有什么不同,这也是为什么从一般的监控数据很难发现设备潜在故障的原因。
但绘制这些时序数据的频次图(图4)就会发现,好坏设备的这个指标的频次图有差异,这样就能找到基本的衍生变量思路。
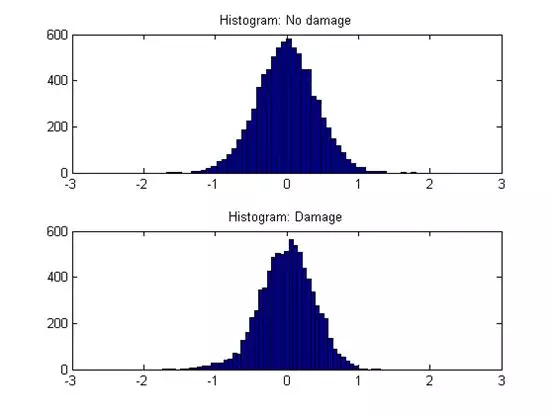
依据这样的思路,可以得到更多更有效的变量。
而计算设备的衍生变量可以利用SHMTools中已经开发好的函数,这些函数的功能就是由原始采集的数据计算衍生变量。
用这个工具箱提取了7个特征变量,但它们对好坏系统又有不同的识别能力,通过相关性分析最终选择了3个识别能力最好的三个变量,第1,3,6个变量。
选择变量的时候,可以使用MATLAB内置的变量选择函数来实现。
选择好变量后, 就可以准备训练模型了,但在训练模型前,需要设置交叉验证方式:
cv = cvpartition(length(features),'holdout',0.40);
在所有的分类方法中,对于特征变量的识别,决策树算是一种比较好的方法,所以不妨先用决策树方法来训练分类模型。
关键代码是:
t = classregtree(actFeatures(trainId,:), damageStateTrain);
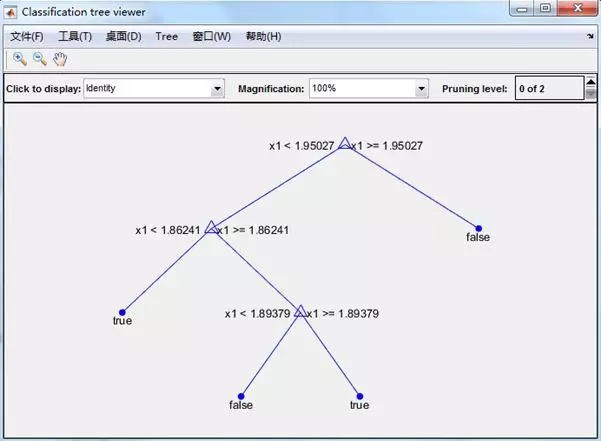
然后就得到了这个树形模型
同时,测试结果显示,该模型的误判率为: 11.7647
如果使用集成决策树方法,可以将误判率降为4.4%, 这个结果已经算比较好的了(模型的评估)
模型出来后,就可以着手模型的部署了
模型的部署是一般数据挖掘过程的最后一步,是一个集中体现数据挖掘成果的一步。
一般而言,完成模型创建并不意味着项目结束。模型建立并经验证后,有两种主要的使用方法。第一种是提供给分析人员做参考,由分析人员通过查看和分析这个模型后提出行动方案建议;另一种是把此模型开发并部署到实际的业务系统中。
如果是以MATLAB为工具开发的模型,那么可以将这些模型部署到C++、Java、net等语言开发的系统中去,也可以直接开发成MATLAB的应用程序去使用。在部署了模型后,还要不断监控它的效果,并不断改进之。
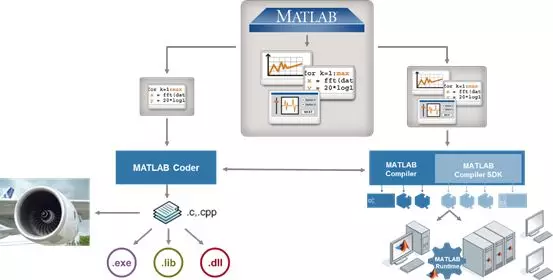
这张图就是MATLAB支持的部署方式
这个案例介绍就到此了,下面总结一下大数据挖掘的几个体会:
(1)大数据思维
大数据思维的核心是要具有利用数据的意识,无论量小还是量大。当我们处理的业务中涉及到数据,尤其是有大量数据时,我们要想到是否可以利用这些数据处理碰到的新问题,这就是大数据思维。大数据思维也同时要求思维是开放的,包容的,也就是所有。大数据思维更多的是关注数据间的相关性,能够辨识出于业务目标具有相关性的数据,或者根据一堆数据间的相关性推测出有意义的挖掘目标。
(2)大数据的收集与集成
大数据挖掘在收集数据方面的要点就是理清与挖掘目标可能又关联的数据,然后将这些关联数据收集起来。集成数据就是将收集的数据统一管理起来,将分散的数据更趋于集中管理,集成的程度越高,对后续的挖掘越有利。
(3)大数据的降维
大数据的一个特点是量可能很大,这样就可能超过计算机的处理能力,所以在对数据进行集成后,通常要考虑将数据进行降维,从而缩减数据量。大数据降维的要点是根据数据挖掘的目标、数据量、计算机的处理能力、对时间的要求等多方面的因素,对数据进行分级降维,首先是通过抽样的方式对数据进行降维;
第二层次是抽取有用的变量,第三层次根据经典的降维方法,如PCA等,进行数据的变形降维。采用哪种方式,关键是看我们的数据适合哪种方式,怎么合适,怎么高效,就怎么来。
(4)大数据的分布式与并行处理
如果数据经降维后依然很大,或者有些数据就是比较大,不适合降维,比如遥感的图像可能超过计算机的内存,再或者对响应时间要求比较高,那么此时对数据进行处理就要考虑分布式和并行计算了。
大数据挖掘学习资源
最后再介绍一下基于MATLAB进行大数据挖掘的学习资源。
上面所介绍的案例是《大数据挖掘:系统方法与实例分析》中的项目篇的一个案例,关于数据挖掘的常用方法,这本书介绍的也比较全,另外还有其他行业的应用案例,并且配有数据和MATLAB源程序。
另外在MathWorks官网(www.mathworks.cn)以及MATLAB 帮助系统中也有关于机器学习、数据挖掘的具体方法的案例介绍。
我介绍的部分就到此结束,谢谢大家!
自由讨论
1、用工具箱shmtools提出哪7个特征变量?如何利用相关性选择最终的变量?用了多少训练数据?故障数据如何得到?误判率怎么出来的?matlab coder是一个现成的产品吗?
卓金武:工具箱shmtools提出哪7个特征变量? 都是基于监控数据衍生得到的,具体衍生的方式也不同,有个Research的过程,这也是探索的价值。故障数据,是从有故障的设备的监控传感器中读取的。matlab coder是一个工具箱,可以直接使用。
2、我有些小问题,就是卓老师前面所提的绘图,就是当数据的变量特别多的时候,我们一个个看是否太花时间了,判断相关的时候是否会考虑一下有些变量存在非线性相关,是否能使用功效分析确定变量更好点?
卓金武:当变量多的时候,可以批量进行相关性分析,比如可以使用相关系数矩阵方法,或者定义一个评价函数,然后就可以直接一次性筛选了
3、请问老师在选择变量时时使用的何种方法?是根据遍历各指标的频次图,选择正常情况与异常情况频次图差别较大的变量吗?
卓金武:变量筛选我一般比较喜欢相关系数法,得到的结果直观
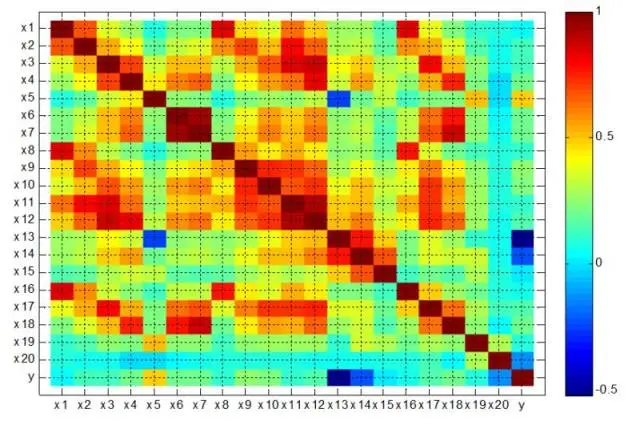
这张图就是这个方法得到的相关性强弱结果, 比较容易筛选出相关性强的变量。另外,MATLAB中有个函数sequentialfs也可以实现变量筛选。
4、您好,做传统etl怎样能找个大数据的工作呢?谢谢。
我有4年etl经验,会shell,做过csharp项目。自己搭hadoop hive的环境,看教程,尝试了些常用的命令。找工作面试了几家搞大数据的,最终也没成。现在一家说做大数据,可一过来,给安排的还是kettle报表,存储过程之类的工作。
卓金武:如果您简历上写etl这类的工作经历,业内人很可能认为您是做数据管理,数据仓库之类的。但其实两者就很大的相关性,但为了更容易找打大数据的工作,所谓BI,一定要在您的简历上突出您的数据管理以外的工作,比如如何利用这些数据,得到一些有用的结论。最直接的就是写上你所做的的数据挖掘项目
下期预告:
2016年07月01日晚8点半微信直播交流用R语言实现量化交易策略交流会第22场https://www.hellobi.com/event/67
今天的微信直播活动到这里就结束了,喜欢天善智能的朋友们请继续关注我们,每周五晚8:30,我们不见不散哦!
每周 Friday BI Fly 微信直播参加方式,加个人微信:fridaybifly,并发送微信:公司+行业+姓名,即可参加天善智能微信直播活动。


