公告
周五BI飞起来,天善商业智能BI社区每周五下午举办问答社区在线答疑活动,每周五晚上举办行业、厂商工具、技术相关的微信在线直播活动。
2016年05月06日 Friday BI Fly 微信直播主题–python零基础入门实战
【活动预告】详情请关注天善问答社区活动页面http://www.flybi.net/project/

主持人:加入本群的同学们,感谢大家参加由天善智能举办的 Friday BI Fly 活动,每周五微信直播,每周一个话题敬请关注。
【群规】本群为商业智能和大数据行业、技术、工具的交流学习群。不准发广告,只能发红包,发广告者一律移除微信群。
本次微信直播讨论内容
1、违约欺诈类数据挖掘应用场景特点分析;
2、违约欺诈分析方法综述;
3、违约欺诈分析模型评估与应对。
本期嘉宾介绍
天善特邀社区专家 数据挖掘产品经理 汪尚
大数据挖掘与欺诈分析准备 http://ask.hellobi.com/blog/SmartMining/3863
个人博客专栏 数据挖掘、商业智能、大数据从业者 http://ask.hellobi.com/blog/SmartMining
主持人:
大家好,我是微信直播活动的主持人咖啡,每周一个主题,一场跟数据有关的行业、工具、技术的交流盛宴。我们的口号是“Friday BI Fly 周五BI飞起来”。关于每周五微信直播的话题,梁总已经给大家排好了未来几个月的分享主题,敬请关注!
往期的微信直播活动跟金融行业相关的分享我们也做过多次了,有讲金融行业大数据技术架构的,有讲风控管理的,有讲银行报表那些事儿的,也有讲金融行业精准营销的,今天我们数据挖掘专家 汪尚给我们带来金融行业欺诈相关的数据挖掘应用,下面我们就有请汪总来给大家带来下面的分享,看看有哪些精彩的案例分享给大家。
大数据挖掘与违约欺诈分析、违约欺诈分析模型评估与应对
数据挖掘专家 汪尚:
大家好,非常高兴和大家一起学习,尤其是同时和几千人一起学习,我分享期间,会不断给大家提问的时间,让大家一起交流,现在开始今天的分享。
经过这么多年的实战,从业务应用的角度,我大致把数据挖掘的应用场景分为三大类:
第一,个性化推荐与精准营销;
第二,监督管理;
第三,经营预测。
不同行业侧重不同。个性化推荐与精准营销:这类主要指精准推荐类场景。主要用于个性化推荐服务、广告推荐和精准营销等。所涉及的算法有聚类分析、分类预测、关联分析、社会网络分析等。监督管理:这一类的应用场景比较特殊,多模型并行和混合应用。主要包括异常分析、违约分析和欺诈分析等。比如在检查一个设备是否有异常时,我们可以使用几百个模型来判断该设备是否有异常,只要有一个模型判断出来有异常,我们就可以判定为异常,越多的模型判断出异常则越异常,这些模型之间即独立又关联,而且后期可以不断加入新的模型。这次要分享的就属于这一类。所涉及的算法有聚类算法、偏差法、分类预测等。
经营预测:这类应用的特点是和日期相关,预测某个特征在未来各个时间上的表现情况。主要用于企业规划、预算体系和库存优化等。如预测某个产品未来每个月的销量、某些材料未来的需求量等。
下面重点聊一下第二类应用场景。咱们以三个小故事分别解释一下异常分析、违约分析和欺诈分析三种常见的监督管理应用。
第一个故事:农业补贴领用欺诈分析
这个案例之前已经在天善论坛写博客分享,大家可以好好看一看,这是一个经典的案例:http://ask.hellobi.com/blog/SmartMining/2378,附件中有详细的实现过程。
天善论坛有很多高手写的好文章,大家有什么问题都可以到天善论坛提问或者查资料。
这个案例描述的是这样一个场景,政府对于农业有补贴,积累了农业补贴的领用数据,政府不知道这些领用是否合理或者存在欺诈,因此想通过数据挖掘的手段评估一下农户的领用金额是否存在异常。数据中记录了农户的姓名、所在区域、拥有田地的大小、降雨量、田地质量水平、田地收入、主要农作物、申请补贴的类型和申请补贴的金额。
业务目标:分析哪些农户领用补贴存在异常,并输出可疑的名单。
数据挖掘目标:建立异常检测模型,输出可疑名单。
通过这个案例我们探讨一下多模型异常诊断的问题。也重点掌握以下几点:
第一,如何结合业务理解,通过业务规则来进行异常分析。当然这是一个典型的以业务为驱动的数据挖掘项目。
这一点也是大数据挖掘和传统数据挖掘相比要更加侧重的一点。
因为大数据分析更要讲究生产力,所以数据价值的挖掘效率非常关键,否则我们的数据挖掘能力很难给企业带来实际的价值。
要做到这一点,分析目标就要非常明确,就要以业务为驱动,面向某个业务问题聚焦一点进行挖掘,避免没有目标的乱挖。
在这个案例中,通过统计农户的领用次数发现,除了两个农户之外,剩下的农户领用次数都只有一次,而这两个农户领用次数分别为2次和4次。
我们可以从这一信息中学习到正常只领用一次,超过一次就异常(向数据学习经验)。
此处可以交流,大家有问题可以提问。我也向大家提问一个问题,从对每个农户的领用次数进行统计,大部分领用次数都是一次,只有两个人不是1 次,而是2次或4次,为什么就可以判定为异常?
周文锋:普遍化和差异化?
鹏:法律法规
凯歌:离群值
美子:分析目标
IT咨询顾问_kevin.wang:小概率事件
汪尚:嗯,其实做数据挖掘,很多时候要学会向数据学习,这样也是避免分析人员对业务不够了解的核心解决方案,大家都知道,理解业务对做数据挖掘很关键很重要,但是实际上分析人员大部分场合下不怎么懂业务,或者懂的不够,所以如何来弥补对业务的空白?核心秘诀是通过数据探索向数据学习,其实重点是向数据本身学习,因为就算业务人员也几乎不可能什么业务都懂,或者说不会懂那么深,因为数据挖掘就是解决业务问题的,就是解决原来难以解决的业务问题,比如说刚才的问题,如果从领用次数的分布上学习什么是正常什么是异常。有的朋友说这是业务或者法律决定的,实际上,这一点并不确定,而数据挖掘本身就是推断,而从领用次数的分布上看出来的,因为只有两个人不是领用一次,其他人都是一次,那么也就是说大部分的选择就是正常的,即正常范围,反之就是异常范围,即异常值,当然正常不等于正确,如果大家都是骗子,只有你不是,那异常就是你。所以数据挖掘的异常诊断而言,强调两点:第一点,异常的不代表是坏的;第二点,可疑分子不等于犯罪分子。所以通过分析获取的可疑名单不能轻易给人看,这对人影响很大,得出可疑名单后,只有取证完成后,有了实际的证据才能判断为违法犯罪,这是做这类分析要注意的一点。
第二,围绕如何通过数据挖掘的手段派生一个参考变量指标,来评估与实际值的偏差是否有异常,来进行异常分析,这对于异常分析是一种即简单又有效的方法。
在这个案例里面,主要讲解两种派生参考变量的方法,一个是通过变量的相关性进行参考变量的派生,另一个是通过分类预测,尤其是分类目标变量为数值型的分类预测来派生参考变量。
在这个案例中派生的第一个参考变量是预计田地收入,也就是从实际田地收入与预计田地收入的偏差入手,偏差大的为异常。
预计田地收入的派生很巧妙,采用的是相关性的思想,比如工时和收入的问题,如果一个人的收入=工时*时薪,那么对于这个人来说,知道了工时就等于知道了收入。
从整个公司来看,员工的工时和收入是强正相关的。
因此,派生预计工时和预计收入是一样的,所以本案例是通过三个与田地收入较相关的字段田地的大小、降雨量、田地质量水平相乘派生了一个与田地收入强相关的字段作为预计田地收入。
派生后如何判断派生的这个字段是否合理呢
看一张图就可以了
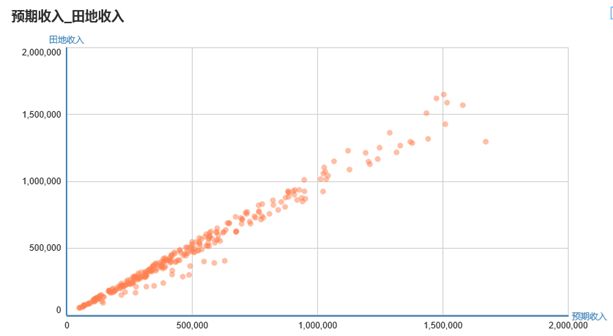
用散点图描述派生的这个参考字段与田地收入的相关性,相关性越强越合理。只要理解了前面以相关性派生参考字段的思想就可以理解这一点。第二个参考字段预计申请金额的派生也很巧妙,采用的是分类预测算法,使用其预测值作为参考值。看看这个能否想明白其中的道理?刚才讲的派生参考字段的思想有些难度,大家可以提问探讨。
周文锋:这些特征值如何提炼?
春天在心里:派生字段 可以这样理解吧 就是目前有几个现成的字段,但是因为单位不同,无法具体比较,可以通过这几个字段的再计算换成 标准单位,这个就是派生字段吧?
张贺:派生字段是不是预测?这个是不是通过拟合曲线进行预期收入预测?
一点点:刚刚那个散点图,是实际收入和预计收入的,其中预计收入是通过另外3个现有变量求出来的?理解的对么
IT咨询顾问_kevin.wang:我觉得难点在派生变量上,今天讲的两种方法,一个是相关性,一个是分类,我们这些没有做过挖掘的,希望给一些基本的原理或方法,或者要补充什么基础课?
张剑@数据分析师:这个案例一定要派生变量吗,既然认为田地收入和降雨量,田地大小和质量有关,直接做回归模型,用点偏离回归线的程度判定离群可否?
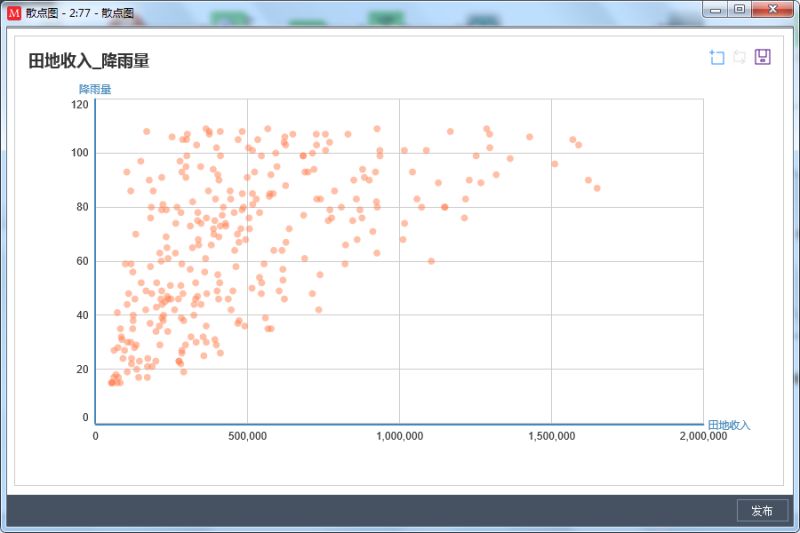
汪尚:看一下这个图,就是降雨量和田地收入的关系,可以看出有相关性但是不是很强。是的,确实要想尽办法根据目标派生字段。刚才朋友说的对,数据挖掘中最难的不是大家常听的那些高级算法,而是字段的派生。
IT咨询顾问_kevin.wang:汪总讲出來了,我们觉得确实是这样,但是如果拿到一个新的项目,如何派生变量,按照找出异常的目标来派生变量,这个有什么好对外方法思路,对于初次做挖掘的人。
春天在心里:这个应该靠 对业务的理解吧,才能知道需要派送什么字段。如何确定参考字段?
梧桐:做了几年业务和数据,有个感觉很深,各个业务线参杂着,也能算出是相关的,影响如何看出来?很多都不是简单的线性相关能得出结论的。如何找出最大的几个影响因子,一直很困扰。
汪尚:这个就是第二种派生字段的方法,通过分类预测算法派生字段。比如我们可以使用线性回归或者神经网络算法以申请金额字段为目标,其他为输入(影响因素)建立分类预测模型,那模型的预测值作为申请金额的参考值,直接与申请金额对比,偏差大的判为异常,那大家理解为什么可以把申请金额的预测值作为参考字段吗,即作为预计申请金额。这里有一个假设,就是模型在预测准确的情况下,模型是通过总结潜在规率建立预测模型,那么好的模型就可以代表正常的结果,所以模型预测的较准确的代表的就是正常的,预测不准确的就是偏离一般规律的,也就为异常的,这一点大家要好好理解,这是对算法的活学活用。在实际的数据挖掘项目,大部分项目的成败都不取决于某个算法,这个可以根据R方判断。
第三,如何通过可视化的方式,来探索一个数值型字段和一个字符型字段的相关性。
我要强调的一点,可视化探索是数据挖掘的灵魂,只要掌握了看图能力,就一定可以做好数据挖掘,但是实际上,很多做BI的人虽然天天和图表打交道,但是大部分人都看不懂图,在数据挖掘中也讲可视化,但是更偏向可视化探索分析,图形有两个作用,第一是数据特征呈现,第二是做变量间的相关性探索。
我喜欢可视化,数据的真实目的就是呈现,而且以可视化探索的方式分析变量间的相关性比统计相关性检验好用的多。
数据的真实目的不是呈现,而是分析,很多人把图形做的特别漂亮,但是很难看出信息,很不直观,我觉得这样做就违反了可视化的意义,最好只用二维的,不要用三维立体图形,不直观,平面的图形也可以做多维度的分析。
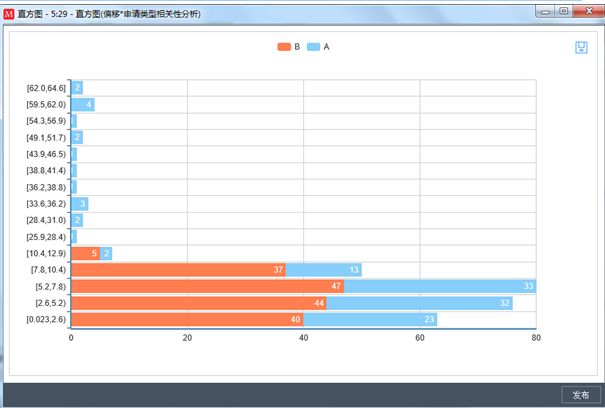
大家看看这张图,是不是很直观的判断申请类型和偏差之间的相关性,申请类型有两种,即两个值。
这个图做的是申请类型与偏差的相关性,其中可以看出,B类型的都在下方,即B申请类型的农户的收入偏差都比较小,所以,就可以通过这个图判断B申请类型的人不容易欺诈。
第四,通过聚类分析算法来进行异常诊断的方法。该案例介绍的是聚类算法的另外一种灵活运用。采用的是聚类的思想对异常对象进行判断,主要思想是这样的:首先,我们使用聚类算法将对象(每条记录为一个对象)分成两类,其次,计算每一个对象到类中心的距离,距离类中心较远的点即为异常点。
聚类分析也是判断异常的重要方法,是从聚类的思想如手,从多维度将相似的人归为一类,不相似的人分开,那么同一类中与类中心较远的点就是异常的,因为不合群嘛。
这就是通过聚类算法判断异常的思想。
第五个,通过以上四种方法建立了四个模型,四个模型分别从不同的角度对异常进行判断,这就是之前说的异常分析的多模型并行问题。每个模型都会输出名单,最终的可疑名单是四个的总和。
第二个故事:信用卡风险评估
信用风险也可以称为违约风险,是指借款人、证券发行人或交易对方因种种原因,不愿或无力履行合同条件而构成违约,致使银行、投资者或交易对方遭受损失的可能性。
客户是财富来源同时也是风险来源,客户信用风险,如拖欠、赖账、欺诈、破产,都可能会给银行和企业带来巨大的损失。
该数据包括用户的年龄、教育、工龄、本地居住时长、收入、负债率、信用卡负债、其他负债以及用户是否发生过违约等信息。
业务目标:建立信用评估系统,当把信用卡用户的信息导入到该系统时,系统会自动输出这批用户的违约风险及信用得分,为信用卡用户的管理提供决策支持。
数据挖掘目标:建立信用卡用户的信用评估模型,该模型以用户的信息指标为输入,以违约为目标,建立预测模型,该模型可以根据输入指标的值,计算预测值(违约)。
这类场景通常采用分类预测类算法。根据历史的是否违约的特征,模型去总结违约用户的特征并建立违约预测模型。
进而可以根据对于每个用户的违约概率的预测,建立信用得分。
这个案例之前也在天善论坛的博客中分享过,大家可以参考:http://ask.hellobi.com/blog/SmartMining/2379。
所有的分类预测问题都可以参考这个案例的分析过程,包括欠费分析、客户流失分析、二次购买预测等。
第三个故事:订单违约分析
这一类分析在代理业务应用居多,如医药代理、电子产品代理等。应用于总代对二级代理或者药厂对经销商的风险管控。
这一类问题要强调一点,就是精细化的问题。在过去,做代理商的违约分析,可能只需要评估代理商或者经销商的整体信用,给个固定的授信额度就行了。
但是目前的商业越来越复杂,单靠这样难以达到风控的目标。比如,一个代理商或者经销商并不是每个订单都会违约,也不是各种类型的订单都会违约。
因此,违约的预测,可以精细到对一个订单的预测,在与代理商或经销商整体授信结合,就可以达到更好的效果。
业务目标 :通过经销商的历史表现、企业概况及其他信息,建立经销商的综合评估模型,评估经销商总体信誉及订单的违约风险。完善企业在经销商分析方面的指标体系,优化数据采集和管理方法。
分析成果:
建立了代理商信用的评估模型,及评估得分
建立了订单超期概率的评估模型,并开发了应用系统
找到了一批诚信较好,合作潜质较大的客户
找到了一批诚信较差,应该改变原有合作方式甚至放弃合作的客户
评估了销售员与订单超期的关系,找到了一批订单风险较大的销售员和订单风险很小的销售
研究发现,代理商的担保类型对订单是否超期影响不大
所有存在授信的场景都会存在违约的风险,而这些场景都可以采用此方法。希望这次分享对大家有所帮助,请多多指教。
主持人:今天的分享很给力,感谢汪总给我们带来的精彩分享,案例讲解的很细致,通过抛出问题,让大家都参与到讨论当中,这样大家理解的会非常透彻,这样学习到的内容也要比单纯听收获更多。
IT咨询顾问_kevin.wang 非常受用,谢谢,另外,我理解是不是,一是对业务的理解,那是坑定要加强的,另外,通过探索来找到强相关性的变量,
周文锋:大数据分析很多时候一般都有预处理过程或步骤,请问有什么方法论或者思路吗?
春天在心里:刚才讲的过程中,提到正确的记录,这里的记录量级在多少以上才算靠谱?量少偶然性大。
汪尚:挖掘的流程可以参考这个http://wiki.smartbi.com.cn/pages/viewpage.action?pageId=17958367,记录多少还真没有一个固定的数字,不过核心是评估模型的稳定性,记录不怕少,稳定就行,模型不稳定就要更多的记录,不过模型也可以根据新的记录不断优化。
自由讨论
问题1、大家都知道,理解业务对做数据挖掘很关键很重要,但是实际上分析人员大部分场合下不怎么懂业务,或者懂的不够,所以如何来弥补对业务的空白?
汪尚:核心秘诀是通过数据探索向数据学习,重点是向数据本身学习。因为就算业务人员也几乎不可能什么业务都懂,或者说不会懂那么深,数据挖掘就是解决业务问题的,就是解决原来难以解决的业务问题。
问题2、春天在心里:如何保证这个 比如2个人不是领用一次而是多次 是数据源产生错误了呢?
汪尚:这个问题问的好,对于数据的异常第一步是判断是否错误,对数据挖掘而言,错误也可以视为异常,也是要之后统一求证判断
问题3、周文锋:就是目前有几个现成的字段,但是因为单位不同,无法具体比较,可以通过这几个字段的再计算换成标准单位,这个就是派生字段吧?
汪尚:这是派生字段的一种,刚才那样派生是因为现有变量没有一个相关性很强的字段,所以就需要基于现有的变量生成一个更有代表性的字段,这是数据挖掘的基本任务之一。数据挖掘中最难的不是大家常听的那些高级算法,而是字段的派生。
静静明月:根据原始数据为了达到目标产生的其他字段。
问题4、IT咨询顾问_kevin.wang:但是如果拿到一个新的项目,如何派生变量,按照找出异常的目标来派生变量,这个有什么好的方法思路,对于初次做挖掘的人?
汪尚:比如我们可以使用线性回归或者神经网络算法以申请金额字段为目标,其他为输入(影响因素)建立分类预测模型,那模型的预测值作为申请金额的参考值,直接与申请金额对比,偏差大的判为异常。
问题5、静静明月:多少异常才说明不够好?怎么判断预测不准确?分类型的呢?
汪尚:这个可以根据R方判断,即按照正常分类预测算法的评估,如果目标变量为数值型,则看R2,这是对这类算法评估的基本方法。分类型的看预测准确率,拿预测正确的记录除以总的记录数就是预测准确率,或者混淆矩阵、ROC、增益图、提升图等。
一般要求大于90%,现实中能达到80%就不错了。
问题6、周文锋:大数据分析很多时候一般都有预处理过程或步骤,请问有什么方法论或者思路吗?
汪尚:挖掘的流程可以参考这个http://wiki.smartbi.com.cn/pages/viewpage.action?pageId=17958367
问题7、 刚才讲的过程中提到正确的记录,这里的记录量级在多少以上才算靠谱?
汪尚:记录多少还真没有一个固定的数字,不过核心是评估模型的稳定性,记录不怕少,稳定就行,模型不稳定就要更多的记录,不过模型也可以根据新的记录不断优化。
主持人:再次感谢汪总的精彩分享以及耐心细致的回答。
预告下下期的微信直播主题
2016年05月20日晚8点半微信直播交流传统行业如何玩大数据、企业的数据分析能力金字塔等交流会第17场
http://ask.hellobi.com/blog/tianshansoft/3868
还有大家别忘了这个月28号在广州,29号在深圳,我们将举办线下沙龙活动,分享的主题有
1、大数据时代零售数据运营之道
2、大数据分析思维与敏捷BI探索之路
3、如何用数据驱动产品和运营
4、数据分析之企业用户价值模型
这两天会把活动具体情况发出来,感兴趣的朋友敬请关注!
下周五我们的微信直播活动不见不散哦!
参与方式
每周 Friday BI Fly 微信直播参加方式,加个人微信:liangyonghellobi ,并发送微信:姓名+公司+行业,即可参加天善智能微信直播活动。
天善智能介绍
天善智能是一个专注于商业智能BI、数据分析、数据挖掘和大数据技术的垂直社区平台,旗下包括问答社区、在线学院和招聘平台三个网站。
问答社区和在线学院是国内最大的商业智能BI 和大数据领域的技术社区和在线学习平台,技术版块与在线课程已经覆盖 商业智能、数据分析、数据挖掘、大数据、数据仓库、Microsoft BI、Oracle BIEE、IBM Cognos、SAP BO、Kettle、Informatica、DataStage、Halo BI、QlikView、Tableau、Hadoop 等国外主流产品和技术。
天善智能积极地推动国产商业智能 BI 和大数据产品与技术在国内的普及与发展,合作成员包括:帆软软件、Smartbi、永洪科技、ETHINKBI、TASKCTL、奥威Power-BI、上海启路科技、上海亦策等。


