公告
【公告】周五BI飞起来,天善商业智能BI社区每周五下午举办问答社区在线答疑活动,每周五晚上举办行业、厂商工具、技术相关的微信在线直播活动。
【预告】下周微信直播的话题有:
1、大数据如何在旅游行业中创新?
2、互联网+对传统旅游业带来的变化主要有哪些?
2015年12月11日 Friday BI Fly 微信直播主题 – 旅游行业如何做精准推荐?大数据技术在旅游行业如何应用?
主持人:加入本群的同学们,感谢大家参加由天善智能举办的 Friday BI Fly 活动,每周五微信直播,每周一个话题敬请关注。
【群规】本群为BI 行业、技术、工具交流和学习群。不准发广告,只能发红包,发广告者一律移除微信群。
本次微信直播讨论内容:
1、旅游行业如何做精准推荐?比如:旅游行业如何根据不同的人群做精准的酒店推荐匹配。
2、大数据技术在智慧旅游行业中如何应用?
嘉宾介绍
Bob
同程旅游大数据BI架构师。 从C#到java, 从sql到BI,从cube到Hadoop,从Hadoop到nosql+mpp+storm。一路走来,只为心中的执着。
个人专栏:http://www.flybi.net/people/Bob
博客专栏:http://www.flybi.net/blog/Bobwu
卢育峰
5年工作经验,1年管理经验,就职于途牛旅游网。负责数据平台搭建与开发,擅长于数据挖掘、分析,对数据库建模及ETL方面也有一定的研究,技术方向从spssmodeler转向python,ms转向hadoop平台,近期在深层次研究各种算法的优劣。
个人专栏:http://www.flybi.net/people/卢育峰
博客专栏:http://www.flybi.net/blog/卢育峰
主持人:很高兴又到了我们微信直播的时间了,今天由我们来自旅游行业的两位嘉宾给大家介绍推荐系统怎么做?从流程到算法,再到平台搭建、技术攻破,让大家全方位的了解推荐系统的应用实施。好了,我们开始第一个话题的讨论1、旅游行业如何做精准推荐。比如:旅游行业如何根据不同的人群做精准的酒店推荐匹配。 有请我们的嘉宾!
话题一:旅游行业如何做精准推荐?
卢育峰
大家好,我是卢育峰,途牛任职。说到推荐系统,我就流程方面来大致讲一下推荐的过程。
先说个题外话,大家平常都听音乐,不知道大家用QQ音乐多不多?之前用的酷狗还有咪咕神马的。现在我经常用QQ音乐,为什么呢?因为它有个功能非常的吸引我,没错就是它的猜你喜欢,它经常会推荐一些很好的音乐,有时候会推荐一些很让人惊喜的音乐,让人喜欢使用它的功能,这是从自身感觉到的推荐的魅力。
现在大家每天都可以收到各种推荐,新闻啊,游戏啊等等。例如:亚马逊、eBay、京东的商品推荐,Facebook的好友推荐,腾讯QQ朋友圈推荐,豆瓣猜你喜欢,网易云音乐等。
撇开行业来说,推荐已经被应用的很成熟了,已经有一些开源的推荐系统Mahout、EasyRecd、RapidMiner等 大家有兴趣可以去网上查查看。
当然使用这些开源的平台也需要一定的开发工作量,目前有很多企业已经将推荐做出了很棒的效果。相信大家都用过京东购物啊,我现在已经是黄金会员了。以京东的推荐系统来说,为京东整体带来近10%的订单量,表现非常的出色。
这就是好的推荐带来的商业价值。如何基于大数据的环境下实现个性化推荐,实现千人千面,吸引用户转化订单,是推荐需要达到的目的。
推荐可以做的产品有很多:猜你喜欢、个性化push、买了还买,看了还看,热门推荐等等,不同的推荐产品基于的场景也不相同,纵观各大主流的旅游网站如:途牛、携程、去哪儿、同程、驴妈妈等,除了热销的产品推荐之外,均有猜你喜欢这样的个性化推荐产品。
下面简单说一下我们做推荐系统的过程:
熟悉业务场景、整合服务资源
首先,我们要对我们做推荐的目的非常明确,没错就是提高转化率,提高商业价值,这是我们要做推荐的目的。其次,就是要清楚自身的资源情况,有多少服务器,有多少人力去投入。再次,需要了解业务场景,清楚什么可以做推荐什么不需要做推荐,推荐需要做到什么程度。最后,预先对数据的复杂程度及数据量级别有个估计。从数据计算层面来说:每天只有1GB的数据,几台机器就可以搞定了。如果每天有几百TB的数据,那么几台服务器就基本很难处理下来。基于这些基本状况的了解,对推荐系统也可以有一个大致的简单流程,如图所示:
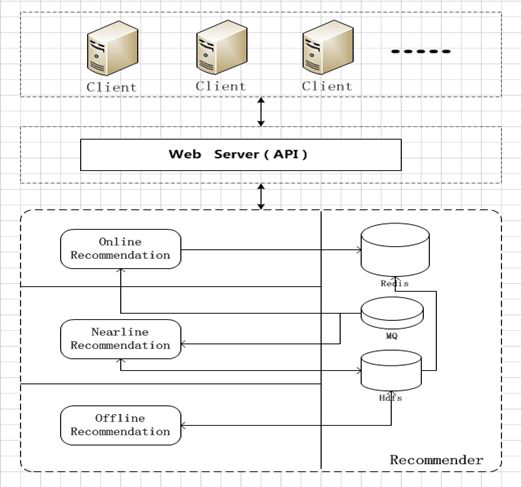
主要分为三个流:
1、实时推荐,能在用户访问的时候,迅速调整规则集合,尽快响应用户的访问行为提升推荐产品的更新效率和合理性。
2、近实时推荐,矫正实时推荐的产品的错误率,能更好的推荐相应产品。
3、离线推荐,提供丰富的离线推荐产品,有利于规则模型的训练。
结合三种推荐方式能很好的提升推荐的实时性、准确性及多样性,同时在考虑服务资源的时候需要周全。
先定义个大概的流式框架,下一步是技术选型。
推荐框架设计
结合我们现有的业务环境,网站访问量大,产品品类繁多,糅合团期概念的产品更加复杂,这些情况导致总体数据量非常庞大,从技术上来说,一般的传统数据也很难满足高效的数据处理。
我们用的sqlserver 第一版也是基于它推荐效果延时太长。
基于现有的大数据平台以及多角度的考虑各种大数据处理技术的优劣情况,我们选择Flume+Kafka+Storm+Spark+Hbase来实现实时推荐。
说下为什么选择这么选型,先说说各个工具的优势:
Flume从OG到NG之后,从分布式日志收集系统转型到数据传输工具,不仅支持Memory还支持File的数据传输,数据传输的稳定性更好,Flume变得更加灵活轻便、扩展性更好,而且在功能上更加强大,更容易集成Jdbc、Hbase,数据可以直接写入到Hdfs。
Kafka作为高吞吐高性能的分布式系统,支持大量数据的快速传输,能长期保持稳定,并且支持KafkaServer间的消息分区。
Storm主要是处理实时流式数据,它的特点是可靠性好,容错较强,每个组件负责一项特定的处理任务结构比较清洗,处理效率非常快,重点是编写容易,支持几种语言。
这几种工具组合是推荐比较成熟的选型,Flume与Hadoop可以很好的整合,Storm可以直接调用Kafka的接口,那么自然就是Flume+Kafka+Storm+Hbase的组合,除此之外,近实时的数据处理,无疑Spark是个很好的选择,虽然Storm处理一个事件可以达到秒内的延迟,但是Storm无法做数据批处理,仅仅是接收数据,简单的实时处理就分发出去。Spark能基于内存运算做某个时间段内的小量批处理,达到近实时效果。
再上个图,大家先view一下,可以指正啊。
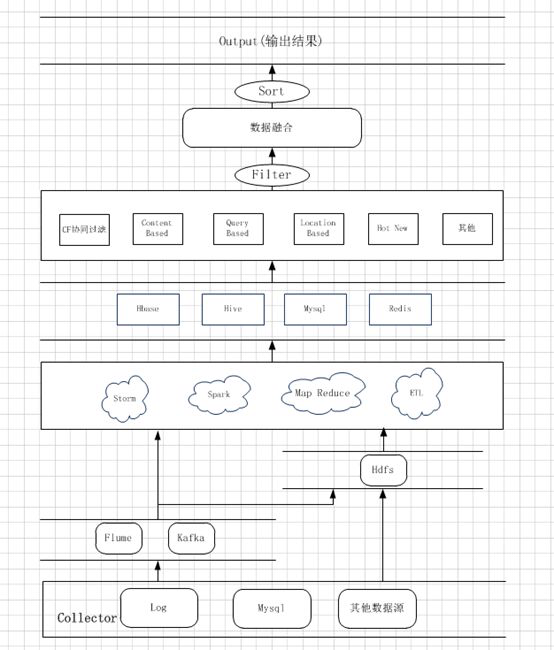
这个框架主要包括这几个流程:数据收集、数据清洗、数据存储、训练模型、筛选排序、输出结果(其中包含参数调优,落地实现等)。
通过网络日志收集、生产库以及其他方式得到数据,数据经过加工处理存储到HDFS文件系统,再经过算法训练模型,通过模型规则产生相应的候选数据集合,最终推送到缓存中,通过push通道或者接口推荐给用户。
流程和模型设计好了,下面是数据准备了。当然算法也是我们后续要考虑到的。
数据准备
首要考虑的是业务场景,其次是数据,其实两者都是一样重要的。
推荐的核心是数据,第一步我们要了解数据,我们有什么的数据,我们还能获取什么数据,根据相应的数据才好了解合适的推荐算法。
先说一下我这边推荐有准备的数据,主要有6个来源。
1、网站行为:搜索、浏览、下单、支付、收藏等
用户访问网站或者APP各种操作行为,这些操作行为可以为离线和事实提供很好的支持,不同的操作行为也具有不同的用户意图,用户的行为倾向也是可以从中识别的,尤其是在线行为能快速更新较为落后的规则,加强推荐的及时性。
2 用户画像:注册填写,出游相关补充信息
用户画像是通过用户的基础属性、社会属性等经过挖掘提炼所获取到的,用户画像带有行业特征,不同行业的用户画像的倾向点不同,旅游行业自然是会带有旅游相关的标签了,比如:出游行程长短、目的地类型偏好等,这些属性对某些推荐可以进行权重配比,对重排序也可以作为feature来用。
3、 产品标签:目的地方向提炼,产品主题抽象等
产品标签是推荐的非常核心的属性,旅游行业主要几种在行程的主题概念的提炼、目的地的划分、日程、价格等。主题主要凸显在旅游的特色,类似蜜月、亲子、毕业以及留学等等,这些主题的划分能很好的从时段归纳产品的类别,给各个时段的用户推荐;目的地划分可以划分出境、国内、当地等,对有出境意愿的用户,我们可以仅仅只推荐出境相关的产品;产品的其他几个属性也是比较影响模型训练的,如:价格、团期、行程安排。
4、负反馈:取消收藏、负点评、取消订单、投诉等
用户的负面反馈反映了某些方面给用户带来不好的体验,可能是产品的质量或者产品的服务,有可能是某些旅游产品看了一段时间出游的团期没有合适的,然后取消关注。这些负反馈可以用于对某些feature降权,或者可以作为feature用于模型的训练,以减少推荐不合适的产品,提高用户的体验。
5、UGC(UserGenerated Content):点评、攻略、游记、BBS等
通过用户对产品的点评、游记体验以及产品攻略的分析,用文本挖掘或者分词技术可以提取非常多的关键词和用户特征,可以用于用户的情感分析和个性化标签。
6、其他数据,有一些数据是比较难以获取的,比如社交信息等。若想获取社交信息,可以基于一些营销手段来刺激用户相互推送消息来获取社交关系,或者从第三方获取到相关信息。
以上是一些数据来源准备。遇到的两个难点就是, 一个是用户画像,如何打上合适的标签,另外一个是旅游行业有团期的概念(出游日期),对产品的团期和价格的前期处理也尤为重要。
数据预处理
光有数据也不行,还需要高质量的数据,高质量的数据可以提高推荐的效果,数据预处理也算是一个大工程,有效的预处理能使得数据挖掘事半功倍,一般底层数据存在空缺、不一致、重复、含噪声、维度高等问题,如果不把这些问题处理掉,会对整个挖掘的效果产生一定影响。数据预处理包含数据清洗、数据集成、数据变换和数据归约几种(其中部分是在做数据收集的时候就可以操作的)。
数据预处理的人工干预是非常多的,少数部分还是需要特殊办法去处理,其中数据集成、空值填补、归一化等用的比较多。数据预处理不多说,想了解的可以私下交流。
算法
下面简要的说一下算法哈,万法归宗,算法主流:分类、聚类、关联。
目前的推荐算法比较多,一般来说有这样几种:协同过滤推荐、基于内容推荐、LBS、基于分类推荐、关联规则推荐、基于聚类推荐、SVD 、基于社交推荐、基于知识推荐等。
当然其中有部分是基于KDD或者规则的。
在繁杂的算法中,如何选型是一个比较头疼的事情,实际上可以基于两个方面去考虑,一个是性能,一个是业务场景。如果服务器足够多,人力足够可以把每种算法和业务场景都作为候选集拿来验证结果,但是现实是你的资源非常少,所以呢,必须要先了解各种算法的特点和作用。
先就其中几个简单介绍一下:(其实网上有蛮多教程哦,可以看看天善的课程)[坏笑]
1、 基于内容推荐(Content-basedRecommendations) 根据用户以前买过的商品来推荐相关的商品,假若A用户对他去过的旅游地点有过喜好的判断,比如A喜欢旅游产品有购物项目,特别喜欢出境游不喜欢短途,基于用户喜欢来训练相应的模型,可以推荐一些相关的产品,比如:毛里求斯迪拜10日游+免税购物。
优点:用户之间是独立的,个性化强,能很快识别用户的新倾向。
缺点:冷启动问题,没有历史数据无法对新用户做相应推荐,无法挖掘用户潜在倾向。
2、 协同过滤(CollaborativeFiltering Recommendations):基于用户或者产品的推荐,基于用户:根据用户历史行为打分,来找出相似用户群体,若A与B是一个群体,A去过马尔代夫,还去过欧洲,B去过马尔代夫,会推荐B去欧洲。
优点:可以挖掘用户潜在倾向,推荐个性化,随着时间推移性能提高,自动化程度高。
缺点:扩展性差,依赖历史数据较强,初期效果较差;
3、 基于分类推荐(Naive Bayes): 基于用户的某些feature进行分类,按照类别进行产品推荐,比如A,B用户,A是iPhone,B是android,给A推荐高质量高价格产品,给B推荐性价比合适的产品。
优点:无需行业知识,可以发现新的item,解决冷启动问题。
缺点:个性化程度低 。
4、 基于地理位置(Location BasedService),基于LBS信息推送相关服务信息,比如周边的旅游景点、美食、购物、娱乐服务设施等。
LBS主要是做场景应用,提炼其中的feature 不是一个单独的算法。
5、 基于搜索内容推荐,可以根据用户的搜索关键词,来匹配相似结果,比如搜索了这个词的人也搜索那个词并且找到他想要的结果,那么可以反馈相应的产品提示给该用户。主要计算相似度。
6、 基于社交推荐,这是一种基于用户社交网络上的好友的推荐,如果用户的好友给他推荐相应的产品,那么用户更加偏好好友的推荐。
以上的推荐方法我们也做过一些尝试,单一算法的效果并不是很理想,需要组合考虑各种算法,通过加权、变换把多种推荐算法的结果集进行结合,通过组合避免和降低各个算法的弱势,突出算法的优势。
经过多次尝试到现在的组合算法,也是一步一步走过来的,根据具体的业务场景选择对应的算法,并进行迭代,选择计算性能满足要求、计算结果精度较好的几种算法进行组合,来实现自动化推荐系统。
产品相关算法:LR(Logistic Regression)、K-means、Item Based
用户行为算法:GBDT、User Based、ContentBased
冷启动算法:基于注册信息的NB(Naive Bayes),访问属性的NB
重排序算法: FTRL(Follow-The-Regularized-Leader)
这个是现有的推荐框架使用到的一些算法。
除了上述的算法之外,还需要一些统计的热门产品、新产品等作为候选集补充,并加入时间衰减因子,减少整个模型的历史推荐权重过大,让用户的新行为优先于历史行为。
最后一步就是部署上线,算法要可配置化,图像界面化,这样才是一个完整的产品,最终产出也要做一定的衡量,可以加入一些反馈统计指标:点击量、转化率、Recall、Precision、调度时长等来判断模型的好坏。
主持人:感谢育峰的分享,很给力,从熟悉业务场景、整合服务资源->推荐框架设计->数据准备->数据预处理->算法设计->模型上线,以及后续要通过反馈统计指标来判断模型的好坏及模型优化,完整的给大家说明了实现一个推荐系统的流程。我们清楚了这个流程,下一步我们就要具体实现了,下面我们有请同程吴文波给大家分享如何搭建一个集群的hadoop环境来高效的实现我们的精准推荐。
话题二:大数据技术在智慧旅游行业的应用。
同程吴文波
大家好,我是Bob wu,在天善的论坛里面是叫Bob,目前是在同程旅游工作,非常感谢梁总和吕总给了我这次与大家交流学习的机会。
请大家多多关注并支持我们:
商业智能问答社区 : http://www.flybi.net
商业智能学院 : http://www.hellobi.com
商业智能招聘平台 : http://www.bijob.cn
天善官网 : http://www.tianshansoft.com
天善智能大数据交流群 :225978231 加群请注明: 天善智能
我和天善智能的老梁是认识很久的网友,大家都是做BI方面的,在数据方面有共同的兴趣。刚刚推荐应用方面我们途牛的育峰已经给大家讲的很详细了,我只搞技术的,今天给大家分享在项目开发过程中的一些问题。
预计能收获的点:
1 Hadoop&hbase集群的一些坑可以知晓下
2 集群程序的简单构建
本次的目的是一起交流学习,在这个方面,我只是一个新人。如有错误,请大家多多关照,多多包涵。
在大数据方面我们只是刚刚起步,一直是在参考外界的做法,内部摸索着前行。每家的情况都不相同。我们当初只是想解决一个痛点,从而构建了Hadoop集群。
同程在12和13年一直是专注于PC方面,在SEM、竞价等方面做的比较好,网站的流量很可观。一方面,公司也期望这些流量能有很好的发挥;另外一方面,网站也想提升下用户体验。但是当时还有很多的搜索无结果页等空白页面,这在宝贵的网站页面上是一种浪费。在这种背景下,很多的产品人员都找到数据部门,期望能从数据的角度为访问者提供更好的资源。我们当时在承接这种推荐系统时,手头只有sqlserver机器,普通的服务器资源等,面对几百G的用户行为数据,使用关联规则,基于人的协同过滤等算法,真心没法计算。
虽然很困难,但是只能上。我们在多方学习摸索以后,初步设计了一些简单的架构:
算法层:
1. 使用R语言来完成算法模型的建立
2. 使用Mahout、MapReduce来完成简单算法的变现。
3. 尝试使用过RHadoop的结合。
存储层:
1. 离线计算方面则使用Hadoop做为分布式存储的主集群。这样的目的是能存储更多的用户消费数据,并提供足够的硬件资源,为每天离线算法的完成做好准备。
2. 实时查询层的存储则使用HBase作为主集群。因为推荐系统的接口都是固定场景的查询。这样非常适合HBase的表设计。
接口程序层:
3. 对外接口程序主要的作用是承担网站的推荐模块调用。这个接口使用java编程,访问HBase并输出json格式的数据。
4. 接口查询日志记录程序。对外接口每次收到查询请求时,会记录下请求参数和响应输出参数。这些log是不能影响到对外接口的性能。所以我们采用异步的方式提交到消息队列中。日志的记录数是请求并发量的几十倍,所以我们需要比较好的消息队列来支撑,所以选择使用kafka。
5. 日志入库程序。接口产生的日志在进入消息队列以后,会有独立的后台程序定时从队列中消费数据,并插入到HBase中。这些日志插入到hbase的目的是为了分析算法的好坏。
6. 离线数据更新程序。承担离线计算的Hadoop集群数据需要更新,所以我们使用java调用Sqoop的API 来完成数据的同步工作。这个程序中会涉及到依赖的问题。
7. 实时查询层的数据更新程序。旅游行业中一些资源是具有时效性的,例如酒店。如果某个酒店在当天有热门事件导致满房,我们是需要下线这个推荐资源的。但是这些资源有很多独特的情况,例如酒店受实时政策的影响非常大,而国际机票则没有现成的资源库。我们在这种情况下分了几个步骤来解决。如果有资源库且是sqlserver的,则使用CDC技术进行分钟级别的更新;如果是mysql的,则使用flume来收集日志实时更新;如存在mongodb上,则需要开发程序来实现同步;如果没有资源库的,则接入项目的查询接口。通过用户的查询,异步提交数据到消息队列,进而入HBase中。
8. 推荐日志分析程序。日志如果需要实时分析和统计,则可通过HBase的Api来做到。我们只需要编写java代码访问即可。如果是每天离线统计效果,则此时需要启用HBase的协处理器功能。
通过以上的程序分解,简单版本的推荐系统如期上线。在这个过程中,我们解决了很多问题,在Hadoop、HBase、kafka等大数据生态组件的使用上更加熟练了。
这一阶段会让一个人受益良多。首先,这是一个真实的项目上线。在实战中收获的技能远比看书的效果好。在此稍微总结下一些问题:
Hadoop集群
Hadoop确实非常优秀,容错性很好。有机器宕机了都没问题。但是在使用Hadoop时,经常遇到的问题是内存错误。Hadoop0.23以前的版本中主要是tasktracker 、jobtracker等进程遇到内存错误;hadoop2.0以后则是resourcemanager、ApplicationMaster、container、nodemanager、虚拟内存之间的内存配置问题。其实这些需要深入了解架构图,并且不断地跑不同任务,不断地总结才能有收获。其次的一个问题是版本升级问题。我们使用CDH版本,从CDH3、CDH4到CDH5,这其中升级了好几次,各种各样的方式都尝试过。例如按hadoop自带的升级命令进行等,失败过多次。
在遇到此类问题时,大家记得多去看每个进程的日志文件。在充分理解架构流程图以后,你在分析日志时将会很快速地定位问题。
另外熟悉源代码也是非常关键的。因为hadoop可以支持debug模式日志输出,日志将会变得更加详细。如果详细阅读了源代码,能帮你加深对架构图的理解,也能加深方法之间的调用关系。
在升级版本时切记一定要保留数据到磁盘中。防止出现灾难。
HBase集群是我们的一个非常重要的集群,很多对外提供实时查询的接口都是依赖HBase。在使用过程中也是有很多的问题。
hbase表设计问题。这个是很常见的。在实际场景中,我们不仅仅是按照rowkey来查询,还需要按照列名过滤。例如为100个会员查询前10个最优的资源。在这个情况下,memberid是rowkey,算法为每个会员自动生成1000个最优资源和产品,列名称可使用产品+0001开始。我们在查询的时候就可以同时使用rowkey和列名称过滤。因为列名称是字符串,所以产品0001、产品0002。。。。。。这些列是默认排序好的。不同的产品则包含不同的列。
HBase 数据存储问题。如果某个表数据存储过大,则会一边写入,一边进行split,一边进行GC。这就可能导致region出现超时等错误。所以为了保险起见,每个表在创建之前就要进行预分割操作,rowkey也要进行散列。这样做的目的是让多个region上尽可能分布均匀的数据,共同承担来自前端的并发查询。散列推荐使用MD5,预分割则遵循16,32这样的规则。
HBase GC的配置。HBase中不可避免的一个事情就是gc。在gc内存占比,时间等方面要详细考虑。GCT/FGC/YGC 是有一定的关联关系,在不同的集群硬件环境中,要多加测试,从实验中选择一个合理的参数。这些实验都需要依赖hbase-env.sh中的jvm参数配置。
HBase中内存配置。这些参数来自hbase-site.xml文件中。分别涉及到缓存大小、读写内存占比等。在实际的生产环境中也是需要进行多次测试,选择合适的配置值。
HBase表优化工作。这些涉及到写入优化、查询优化等。查询优化方面则要考虑regionserver的cache、Max Version、TTL配置、StoreFile配置大小;写的方面要考虑AutoFlush、WriteBuffer、WAL Flag。如果是海量数据写入,建议使用MapReduce生成HFiles,并通过LoadIncrementalHFiles 方式来载入到HBase表中。
以上内容是我在推进项目中的一些总结。但是程序总是需要迭代的,例如推荐算法需要更高的时效性:用户购买完成后就实时计算并输出结果等;算法要讲究复用性;要满足移动互联网的LBS特性。
实时计算方面:我们在离线算法集群和实时查询层之间构建了一个实时计算集群。这主要是使用Spark来搭建的。
1 使用Spark改造原有的离线算法,并全部移植到spark中。
2 使用spark-stream来读取实时消息队列数据,并实时计算部分算法。
3 Spark计算结果完成后直接写入HBase集群
这样做的效果是可以将原来非常耗时的算法变为几个小时执行的单元;可以接收用户的实时数据,并实时计算部分小算法来完成实时推荐的效果。
同程有7亿以上的下载量。在移动互联网时代,基于LBS的一些应用是必不可少的。
我们在LBS上也有些尝试。就拿客户端上距离您最近的**资源来讲。用户在打开的时候会传入经纬度数据,但是用户也可能是在运动的状态中。如何快速检索距离用户最近的资源数据是一个问题。但是我们的查询层是HBase,没法根据经纬度的范围进行Rowkey扫描。当时为了解决这个问题,我们想了一个方案:
1. 使用0.5*0.5的小方格(单位:千米),将全国分解为n多个区域块。每个区域块定时更新最佳资源、最近资源、个性化资源等。
2. 使用Apache的GEOHASH算法,将这个范围内的经纬度都hash为一个字符串。并使用这个字符串作为rowkey进行存储。
3. 前端传入的经纬度也使用GEOHASH算法转换为字符串。
这样做,能让HBase集群承担高并发的LBS查询任务,但是总归是有些误差。唯一不足的地方在于:查询HBASE是使用rowkey的前缀进行查询。这多少会牺牲些性能。在个性化推荐的前提下,这个方案勉强适用。如果公司资源比较少,也不需要包含一些个性化算法结果的话,那直接使用数据库的经纬度字段索引、使用redis缓存也都是比较好的方式。
我的分享就到此为止,欢迎大家批评指正。
主持人:波哥实实在在的从算法层、存储层、接口程序层等方面给我们详细分享了如何搭建一个推荐系统的集群环境,还把他过程中遇到的坑以及如何解决或避免这样的坑毫无保留的分享给了我们,好让我们在做的过程中少走弯路,为波哥这样的无私行为点赞,非常感谢波哥给我们带来的精彩分享。
自由讨论环节
下面我们进入自由讨论环节了,看大家在做的过程中有没有遇到什么问题,专家在此,什么妖魔鬼怪都不怕!
问题一:在生产系统中,你们会用到R吗?是怎么用的?有什么经验?主要用在什么场景?
同程吴文波:会的。@铮 如果是单产品的销量预测,则在线上直接部署R脚本。如果是大型数据模型计算,则需要将r的算法转为spark或Java脚本。
铮:可是R的性能一直是问题。
强强:R的性能不好是吗
卢育峰:我们用 Mahout 分析会用R做训练。
同程吴文波:@强强 在集群计算方面性能不够,可以使用RHADOOP 试试。大量数据面前还是要用spark或mapreduce
铮:你们有用过sparkR吗?可以将R里好的算法包用sparkR变成并行化的吗?
同程吴文波:@铮 可以使用sparkmlib来做。
铮:可是它里面的一些算法不是很全,比如说对时间序列的处理。
问题二:怎么实时对未登录用户浏览的信息和登陆后浏览信息进行绑定,pc端达到用户唯一性,并对其进行分类、打标签、用户画像?
卢育峰:可以通过浏览器识别、visit trace 以及网站互通别的网站登陆的uid(前提其他网站要开启过去同一个标示)来打通用户问题。另外匿名的新用户暂时只做客户端的硬属性区分。
李爱华:1、通过浏览器ID或者能标识uv的方法标记出该用户,根据该用户的上网行为挖掘出该用户在各个用户标签(由于数据量少,标签计算很有可能不够准确)
2、用户可能会清缓存、重装APP、换手机等操作,造成流量统计上将本属于同一用户识别成两个用户,这需要用户统一化算法将用户行为进行合并,丰富最新uv数据,同时避免之前数据僵尸化,只占空间不再更新。
同程吴文波:这个问题确实是个老大难。建议:根据浏览器的cookie 唯一ID 来处理。每次用户登录后就保留用户cookieid +userid.根据历史数据来反推当前用户是否是为以前登录的用户。但是pc端很难做,建议和app浏览结合起来。
问题三:请问下你们算法层牵涉到R代码定期调度的,有什么一套很好的模式吗?
同程吴文波:@霹雳小胖 调度你可以使用Linuxshell,可以自己去写,但是一般情况调度都是打包为工作流程序。
问题四:关联推荐哪家强?
Neal_泥偶:关联推荐的话很难说谁做的好谁做的差,理论上说LinkedIn做的应该是最好的,Netflix是最能吹的,Amazon只是做的最早的,但是真的不咋地。
吴君-51随意行-客流专家 :旅游方面,关联推荐多少会有些效果,不过老客户营销,效果没有零售那么明显。其实,我个人看法,旅游产品的推荐,对real time要求不高,对算法要求比较高,个人看法。
小馒头:腾讯的关联推荐功能也很厉害啊
卡罗~ [表情]:腾讯产品用的多,推荐起来很方便的。
问题五:有什么好的系统推荐的课程,讲算法和演示的,或者应该怎么来学习这一方面?
吴君-51随意行-客流专家:@轩子 搜索引擎是大数据非常有挑战的路,集成多个算法为一体,实时与离线结合的工程。而且他本身是业务系统,所以还可以深入到业务。
吴君-51随意行-客流专家:@轩子 做大数据要做综合,建议进入互联网搜索引擎团队学习,将全面得不能再全面了。
轩子:@吴君-51随意行-客流专家 嗯,我就是想学数据分析偏向业务,产品策划方面
轩子:@吴君-51随意行-客流专家 关键没基础也没团队要啊……
吴君-51随意行-客流专家:@轩子 是的要基础,搜索引擎场景的学习基础包括:非结构化数据处理,语义识别,关联算法,预测,机器学习等。
问题六:旅游推荐也应该是基于用户关联、商品关联做基于用户、商品的协调过滤,在旅游业务上有哪些特征会影响算法效果?
卢育峰:影响算法的的特征主要还在产品标签和用户行为上,属性前面大致说啦。
问题七:关于通过微信公众号里面获取信息推荐,有什么建议吗?
同程吴文波:公共号里面想办法去实现微信的一些接口程序,里面会返回城市等一些地理等数据
同程吴文波:好好看下微信的api。
问题八:请问下旅游产品或者酒店存在线路过期或者酒店套餐下线,怎么处理这部分数据?
同程吴文波:@陈宏 在后台监控发现资源下线了,那推荐系统中进行人工干预。
陈宏:协同过滤训练的结果集和最新在线的产品不一样
陈宏:我想请教下同程实际怎么做产品推荐。用了什么算法。比如用户买的门票,是给他推荐酒店还是其他
同程吴文波:@陈宏 我们这块的处理比较复杂,不是一两个算法来解决的。是根据用户场景来选择算法进行推荐
陈宏:能够举例吗,比如用户在一个产品详情页推荐另外的产品,怎么处理推荐
Jeff.Huang:新品的权重值不一样,另外与用户的场景不同权重也不一样的。
问题九:为什么需要用两种日志收集工具: flume 和kafka
同程吴文波:flume只是承担了从负载集群收集日志,没有直接到达hdfs。在flume到达hdfs之间架设kafka消息队列的原因是,日志数据可以由多个使用方同时读取,每个使用方都是实时计算。
Roger:那他们两个其实还是串行使用的吧,这样会不会加长数据流向,导致维护成本更高呢。
同程吴文波:维护成本相对来说还是可以接受的。我们的这套方案就没啥太大问题
Roger:业务日志数据其实可以直接写到kafka队列上
同程吴文波 :恩
Roger :如果只用flume很难做到提供给多方向使用,sink读完完以后就没了。
【小编后记】
本周微信直播时,微信服务器出了问题,消息延迟很严重,微信服务器这么不靠谱,可是小编是很靠谱的啊,每周按时给大家送上微信直播文字版记录,没有看全的朋友们来看文字版记录吧,小编可是很用心整理的哟!
再次预告下我们下周微信直播的话题:
1、大数据如何在旅游行业中创新?
2、互联网+对传统旅游业带来的变化主要有哪些?
感兴趣的朋友不要错过咯。
参与方式
每周 Friday BI Fly 微信直播参加方式,加个人微信:liangyong1107 并发送微信:行业+姓名,参加天善智能微信直播。