近年来,各行各业的大数据分析需求和案例如暴雨般砸向所有的CIO/CTO/CDO。但凡提到数据分析,BI厂商都讲“数据仓库”,大数据厂商都讲“Hadoop”,似乎你的业务数据存放在不同的地方,就是一个灾难。甚至数据不集成在一起,就没法进行数据分析。
从哲学的思想看,绝对的观点一定是有问题的,走进真实的企业运营管理,这些异构的数据,至少最后都在Excel里面完成“会师”,呈现在Word和PPT的分析报告当中。

那么从数据库工具层面,就没有能简单解决异构数据关联查询的么?回顾历史,10年前出现了“数据联邦”的概念,它将分布式异构数据集成到一个虚拟表中,用户或应用程序可以通过该虚拟表对数据进行实时操作,代表性的产品如IBM InfoSphere Federation Server。
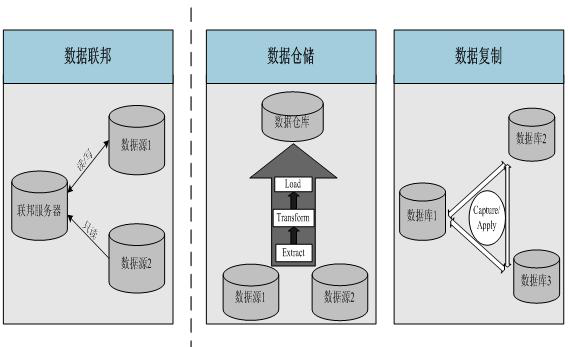
我们暂不讨论数据联邦为何没发展起来,有兴趣的可以研究其“性能问题”,至少针对异构的关联查询需求的技术方案是一直都存在的。比如Smartbi Insight V8.5就可以提供很好的跨库查询能力。从官方WIKI上看到,Smartbi支持的跨库数据源包括高速缓存库、Hadoop_Hive、星环、Vertica、CH、Greenplum、Infobright、Oracle、DB2 V9、MySQL、MS SQL Server、Spark SQL、Teradata_v12、Informix、IMPALA、PostgreSQL,而且只要用户创建了普通的关系数据源连接,这些数据源便会自动出现在“跨库联合数据源”当中。
Smartbi不是数据查询引擎,而是一个数据分析平台,从其整体架构来看,它所能提供的整合性功能很多,包括:
1、 使用“自助数据集”,拖拽不同数据源的表进行关联定义
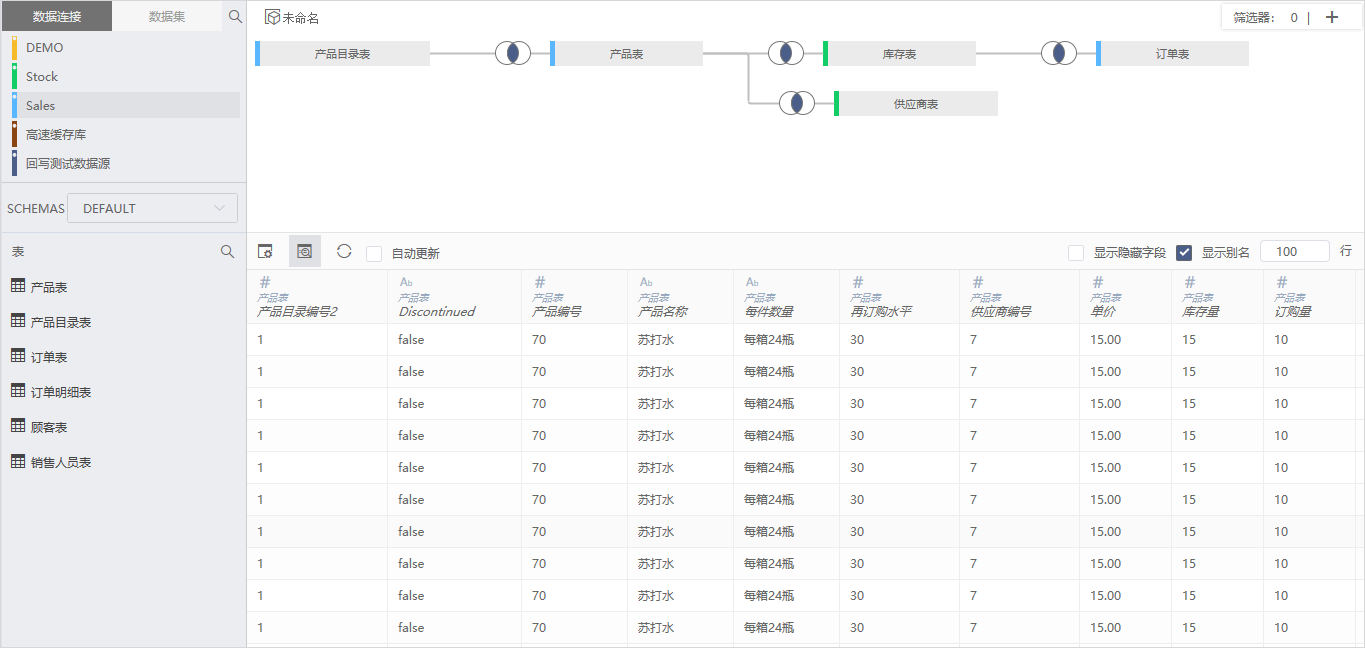
注:蓝色为Sales数据源、绿色为Stock数据源
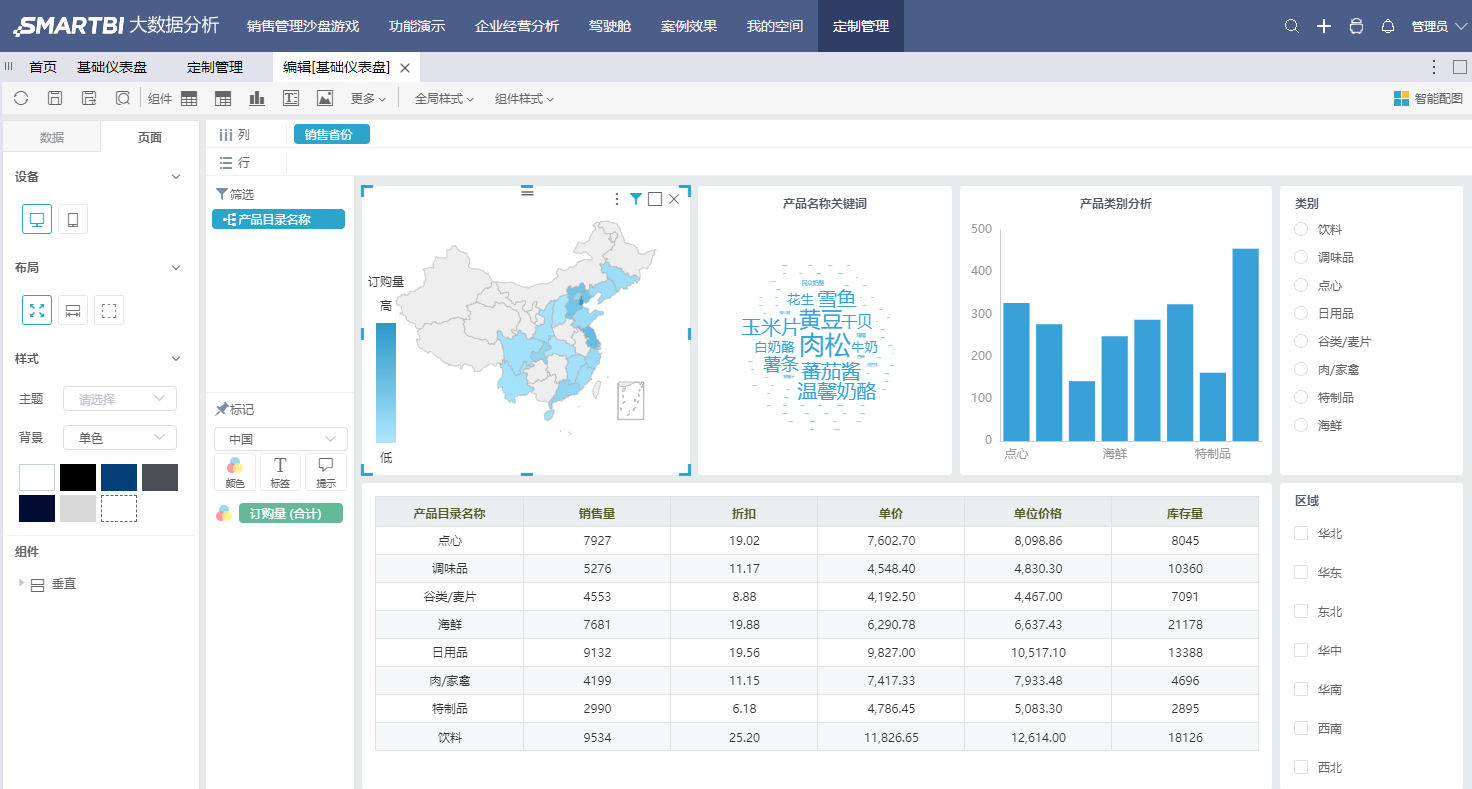
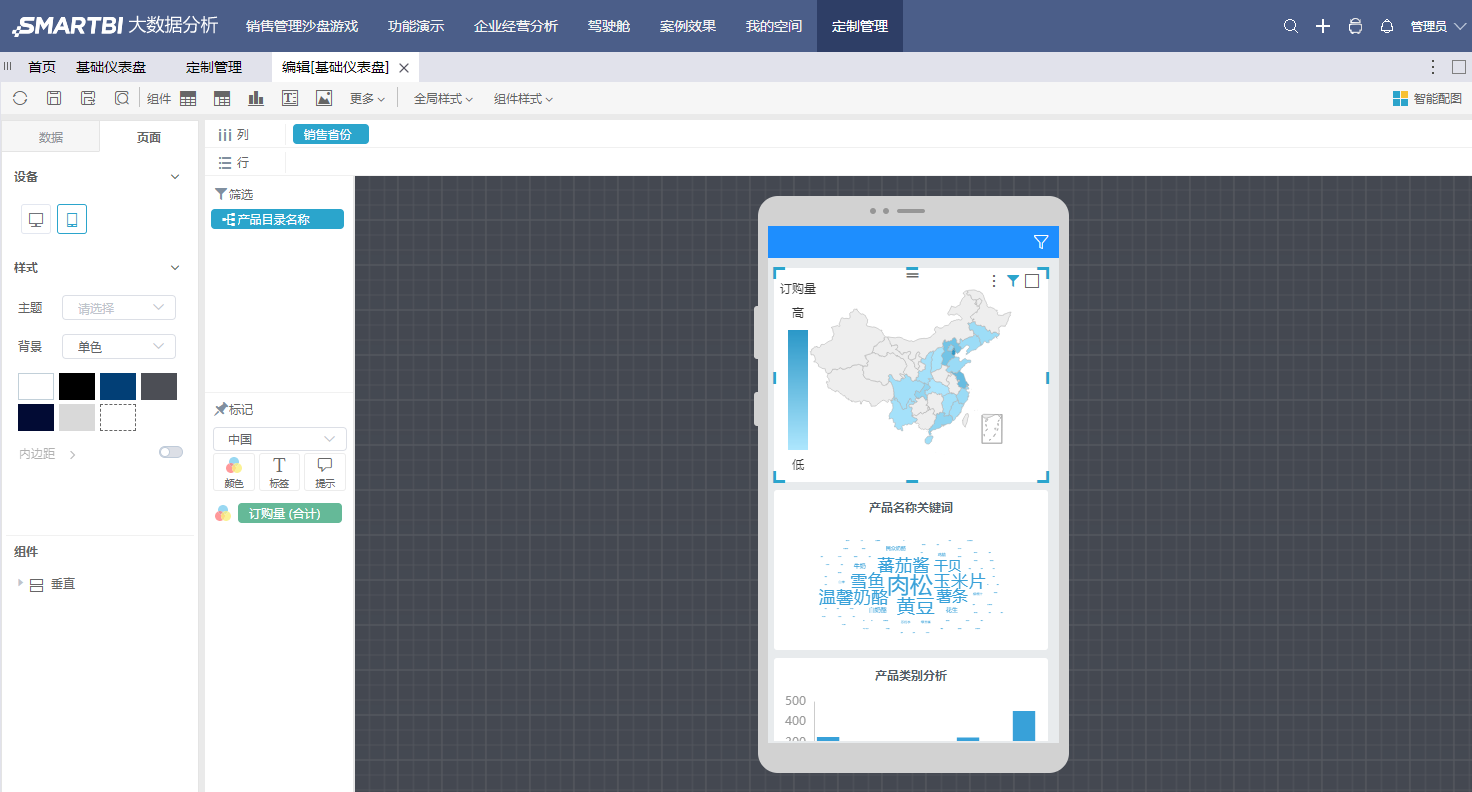
2、 基于定义跨库的自助数据集,方便的进行仪表盘制作
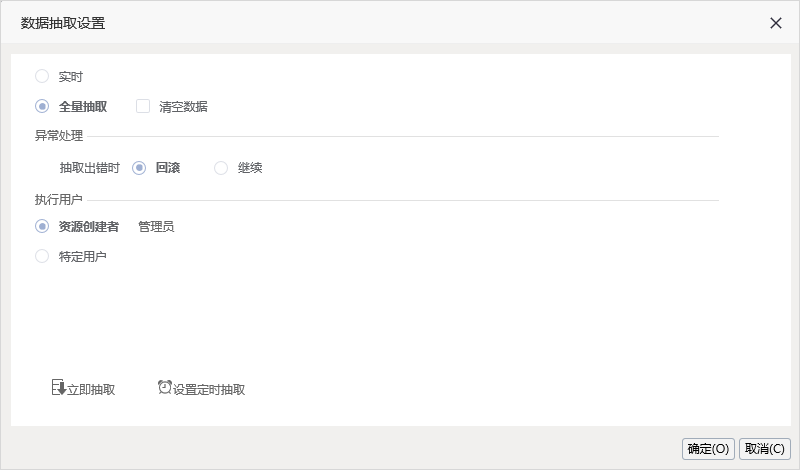
3、 结合“高速缓存库”,跨库查询的自助数据集可以“抽取数据”,完成数据准备工作
从连接数据源——拖拽关联异构数据表——(定义抽取动作)——拖拽完成可视化探索,一气呵成非常方便。这个流程非常适合数据分析的初学者,所有操作过程都通过简单的拖拽和点选,没有任何专业的代码或者编程语言。如果之前了解过自助仪表盘,你还会知道设计的仪表盘支持跨屏发布,一次制作,PC和APP同时生效,减少了重复性工作。
不同企业有不同的需求,如果你不希望开放数据模型出来(自助一定需要开放),而是在IT集中管控下提供自助仪表盘的终端服务,那你可以基于“业务主题”封装已经配置好的跨库查询模型,让最终用户通过自助仪表盘访问这些业务主题即可,而且以业务主题为桥梁,Smartbi V8.5的其它终端分析功能也都可以享受跨库查询的能力(这是Smartbi最经典的使用方式)。或者对于很多高级数据分析师,他们更喜欢在Excel里使用函数和公式。那么还有什么办法呢?还是推荐Smartbi V8.5,但功能是另外的“电子表格”,咱们改天专题推荐。
所以,遇到异构数据源,想做关联查询并快速制作仪表盘,但还没有数据仓库(或者暂时不想实现ETL),就可以使用Smartbi V8.5进行数据分析。是否选择“抽取”,那就看你对性能有什么样的要求了,数据量不大或者源系统性能足够的,不抽取可以节省一个处理环节,更加实时高效,否则定时抽取是很实用的功能,通过落地式的存储肯定可以改善性能,“空间换时间”嘛!
