



文章发布于公号【数智物语】 (ID:decision_engine),关注公号不错过每一篇干货。
作者:Dipanjan (DJ) Sarkar
编译:ronghuaiyang

01介绍
处理非结构化文本数据非常困难,尤其是试图构建一个可以像人类一样解释和理解自由流动的自然语言的智能系统时。你需要能够处理和转换嘈杂的、非结构化的文本数据,并将其转换为可由任何机器学习算法理解的结构化、向量化格式。自然语言处理、机器学习或深度学习都属于人工智能的范畴,它们都是该行业的有效工具。任何机器学习算法都是基于统计、数学和优化原理的。因此,他们没有足够的智能来开始处理原始的、原生的文本。上一篇文章中,我们介绍了一些从文本数据中提取有意义的特征的传统的策略。在本文中,我们将研究更高级的特征工程策略,这些策略通常利用深度学习模型。更具体地说,我们将介绍Word2Vec、GloVe和FastText模型。
02动机
特征工程是创建性能更好的机器学习模型的秘诀。请始终记住,即使出现了自动化特征工程,你仍然需要理解应用这些技术背后的核心概念。否则它们就只是黑盒子,你就不知道如何对你试图解决的问题进行调整。
03传统模型的缺点
传统的(基于计数的)文本数据特征工程策略包括了一大类的模型,这些模型通常称为词袋模型。包括词频、TF-IDF(词频逆文档频率)、N-grams等等。虽然它们是从文本中提取特征的有效方法,但是由于模型本身就是一袋非结构化的单词,我们丢失了额外的信息,比如每个文本文档中围绕邻近单词的语义、结构、序列和上下文。这为我们探索更复杂的模型提供了足够的动力,这些模型可以捕捉这些信息,并为我们提供单词的向量特征表示,即通常所说的嵌入。
04词嵌入的需求
虽然这有一定的道理,但是我们到底是哪来的动力去学习和构建这些词嵌呢?在语音或图像识别系统中,所有的信息都已经以丰富密集的特征向量的形式存在于高维数据集中,如声谱和图像像素强度。然而,当涉及到原始文本数据时,尤其是基于计数的模型(如词袋),我们处理的是单独的单词,这些单词可能有自己的标识符,但是不能捕获单词之间的语义关系。这就导致了文本数据中的巨大稀疏的词向量,因此,如果我们没有足够的数据,我们可能会得到糟糕的模型,甚至由于维数诅咒而过度拟合。
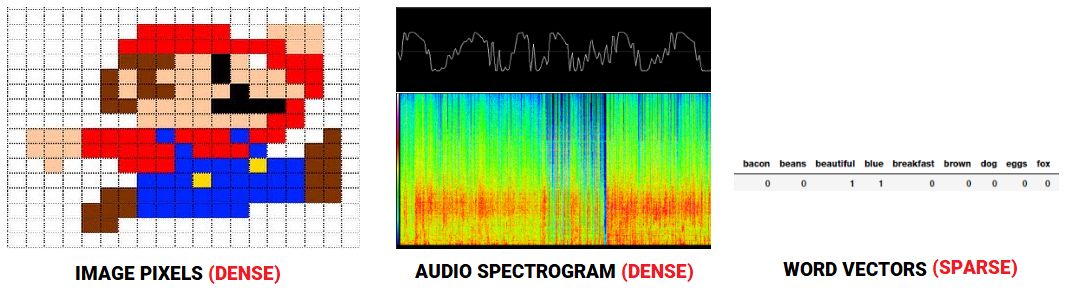
音频,图像和文本的特征表示的对比
为了克服词袋模型没有语义以及特征稀疏的缺点,我们需要利用向量空间模型(VMS),这样,我们就可以把单词嵌入到基于语义和上下文的连续向量空间中。事实上,语义分布领域的分布假设告诉我们,在相同上下文中出现的单词语义上是相似的,具有相似的意义。简单地说,“一个词的特征取决于和它一起出现的词”。有一篇著名的论文详细讨论了这些各种类型的语义词向量,这个文章是‘Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors’。这篇文章我们不会深入讨论,但简而言之,上下文词向量有两种主要的方法。基于计数的方法,比如Latent Semantic Analysis (LSA)可以用于计算某些词和它的相邻的词一起出现频率的统计度量,然后基于这些度量构建dense的向量。基于神经网络的语言模型的预测方法试着从相邻的单词中预测单词,观察语料库中的单词序列,在这个过程中,它学习分布表示,给我们dense的词嵌入。我们将在本文中重点介绍这些预测方法。
05特征工程策略
让我们来看看处理文本数据并从中提取有意义的特征的一些高级策略,这些策略可用于下游的机器学习系统。我们将从加载一些基本的依赖项和设置开始。
import pandas as pd
import numpy as np
import re
import nltk
import matplotlib.pyplot as plt
pd.options.display.max_colwidth = 200
%matplotlib inline
现在,我们将获取一些文档语料库,在这些文档语料库上执行所有的分析。对于其中一个语料库,我们将重用上一篇文章中的语料库。为了便于理解,我们将代码重新写一下。
corpus = ['The sky is blue and beautiful.',
'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
"A king's breakfast has sausages, ham, bacon, eggs, toast and beans",
'I love green eggs, ham, sausages and bacon!',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
]
labels = ['weather', 'weather', 'animals', 'food', 'food', 'animals', 'weather', 'animals']
corpus = np.array(corpus)
corpus_df = pd.DataFrame({'Document': corpus,
'Category': labels})
corpus_df = corpus_df[['Document', 'Category']]

我们的玩具语料库由几个类别的文档组成。我们将在本文中使用的另一个语料库是The King James Version of the Bible,可以从Project Gutenberg通过nltk中的corpus模块免费获得。我们将在下一节中加载它。在讨论特征工程之前,我们需要对本文进行预处理和规范化。
06文本预处理
可以有多种方法来清理和预处理文本数据。在上一篇文章中已经讲过了。由于本文的重点是特征工程,就像前面的文章一样,我们将重用简单的文本预处理程序,它的重点是删除特殊字符、额外的空格、数字、停止词和把语料库的大写转换为小写。
wpt = nltk.WordPunctTokenizer()
stop_words = nltk.corpus.stopwords.words('english')
def normalize_document(doc):
# lower case and remove special characters\whitespaces
doc = re.sub(r'[^a-zA-Z\s]', '', doc, re.I|re.A)
doc = doc.lower()
doc = doc.strip()
# tokenize document
tokens = wpt.tokenize(doc)
# filter stopwords out of document
filtered_tokens = [token for token in tokens if token not in stop_words]
# re-create document from filtered tokens
doc = ' '.join(filtered_tokens)
return doc
normalize_corpus = np.vectorize(normalize_document)
我们准备好了基本的预处理pipeline,让我们首先将其应用于我们的玩具语料库。
norm_corpus = normalize_corpus(corpus)
norm_corpus
Output
------
array(['sky blue beautiful', 'love blue beautiful sky',
'quick brown fox jumps lazy dog',
'kings breakfast sausages ham bacon eggs toast beans',
'love green eggs ham sausages bacon',
'brown fox quick blue dog lazy',
'sky blue sky beautiful today',
'dog lazy brown fox quick'],
dtype='<U51')
现在让我们使用nltk加载基于The King James Version of the Bible的其他语料库,并对文本进行预处理。
from nltk.corpus import gutenberg
from string import punctuation
bible = gutenberg.sents('bible-kjv.txt')
remove_terms = punctuation + '0123456789'
norm_bible = [[word.lower() for word in sent if word not in remove_terms] for sent in bible]
norm_bible = [' '.join(tok_sent) for tok_sent in norm_bible]
norm_bible = filter(None, normalize_corpus(norm_bible))
norm_bible = [tok_sent for tok_sent in norm_bible if len(tok_sent.split()) > 2]
print('Total lines:', len(bible))
print('\nSample line:', bible[10])
print('\nProcessed line:', norm_bible[10])
下面的输出显示了语料库中的总行数以及预处理如何处理文本内容。
Output
------
Total lines: 30103
Sample line: ['1', ':', '6', 'And', 'God', 'said', ',', 'Let', 'there', 'be', 'a', 'firmament', 'in', 'the', 'midst', 'of', 'the', 'waters', ',', 'and', 'let', 'it', 'divide', 'the', 'waters', 'from', 'the', 'waters', '.']
Processed line: god said let firmament midst waters let divide waters waters
现在让我们来看看一些流行的词嵌入模型和对我们的语料库做的特征工程!
07Word2Vec模型
该模型由谷歌于2013年创建,是一种基于预测的深度学习模型,用于计算和生成高质量的、连续的dense的单词向量表示,并捕捉上下文和语义相似性。本质上,这些是无监督的模型,可以接收大量的文本语料库,创建可能的单词的词汇表,并为表示该词汇表的向量空间中的每个单词生成dense的单词嵌入。通常可以指定单词的嵌入向量的大小,向量的总数本质上就是词汇表的大小。这使得该向量空间的维度大大低于传统的词袋模型构建出的高维稀疏的向量空间。
Word2Vec可以利用两种不同的模型结构来创建这些单词嵌入表示。
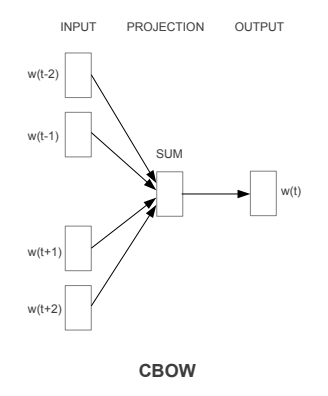
1. Continuous Bag of Words(CBOW)模型
2. Skip-gram模型
Continuous Bag of Words (CBOW) 模型
CBOW模型体系结构试图基于上下文单词(周围单词)预测当前目标单词(中心单词)。考虑一个简单的句子,“the quick brown fox jumps over the lazy dog”,这可以是(context_window, target_word)对,如果我们考虑一个大小为2的上下文窗口,我们有([quick, fox], brown)、([the, brown], quick)、(([the, dog], lazy))等例子。因此,该模型试图基于context_window单词预测target_word。
虽然Word2Vec系列模型是无监督的,这意味着可以给它一个没有附加标签或信息的语料库,它可以从语料库构建密集的单词嵌入。但是,一旦你拥有了这个语料库,你仍然需要利用一个监督的分类方法来实现这些嵌入。但是我们将在没有任何辅助信息的情况下,从语料库本身来做。我们现在可以将CBOW结构建模为一个深度学习分类模型,这样我们就可以将上下文单词作为输入X,并尝试预测目标单词Y。实际上,构建这个结构比skip-gram模型更简单,在skip-gram模型中,我们试图从源目标单词预测一大堆上下文单词。
实现Continuous Bag of Words (CBOW)模型
虽然使用像gensim这样具有Word2Vec模型的框架非常好用,但是现在让我们从头开始实现它,以了解幕后的工作原理。我们将利用norm_bible变量中包含的Bible语料库来训练模型。实现将集中于四个部分:
1. 构建语料库词汇表
2. 建立一个CBOW(上下文,目标)生成器
3. 构建CBOW模型架构
4. 训练模型
5. 获取Word Embeddings
构建语料库词汇表
首先,我们将构建语料库词汇表,从词汇表中提取每个惟一的单词,并将一个惟一的数字标识符映射到它。
from keras.preprocessing import text
from keras.utils import np_utils
from keras.preprocessing import sequence
tokenizer = text.Tokenizer()
tokenizer.fit_on_texts(norm_bible)
word2id = tokenizer.word_index
# build vocabulary of unique words
word2id['PAD'] = 0
id2word = {v:k for k, v in word2id.items()}
wids = [[word2id[w] for w in text.text_to_word_sequence(doc)] for doc in norm_bible]
vocab_size = len(word2id)
embed_size = 100
window_size = 2 # context window size
print('Vocabulary Size:', vocab_size)
print('Vocabulary Sample:', list(word2id.items())[:10])
Output
------
Vocabulary Size: 12425
Vocabulary Sample: [('perceived', 1460), ('flagon', 7287), ('gardener',11641), ('named', 973), ('remain', 732), ('sticketh', 10622), ('abstinence', 11848), ('rufus', 8190), ('adversary', 2018), ('jehoiachin', 3189)]
可以看到,我们已经在语料库中创建了一个包含惟一单词的词汇表,以及将单词映射到其惟一标识符的方法,反之亦然。“PAD”通常用于在需要时将上下文单词填充为固定长度。
建立一个CBOW(上下文,目标)生成器。
我们需要由目标中心词和及其上下文词组成的对。在我们的实现中,目标单词的长度为' 1 ',周围的上下文的长度为' 2 x window_size ',其中我们在语料库中的目标单词前后分别取' window_size '个单词。
def generate_context_word_pairs(corpus, window_size, vocab_size):
context_length = window_size*2
for words in corpus:
sentence_length = len(words)
for index, word in enumerate(words):
context_words = []
label_word = []
start = index - window_size
end = index + window_size + 1
context_words.append([words[i]
for i in range(start, end)
if 0 <= i < sentence_length
and i != index])
label_word.append(word)
x =
sequence.pad_sequences(context_words, maxlen=context_length)
y = np_utils.to_categorical(label_word, vocab_size)
yield (x, y)
# Test this out for some samples
i = 0
for x, y in generate_context_word_pairs(corpus=wids, window_size=window_size, vocab_size=vocab_size):
if 0 not in x[0]:
print('Context (X):', [id2word[w] for w in x[0]], '-> Target (Y):', id2word[np.argwhere(y[0])[0][0]])
if i == 10:
break
i += 1
Context (X): ['old','testament','james','bible'] -> Target (Y): king
Context (X): ['first','book','called','genesis'] -> Target(Y): moses
Context (X):['beginning','god','heaven','earth'] -> Target(Y):created
Context (X):['earth','without','void','darkness'] -> Target(Y): form
Context (X): ['without','form','darkness','upon'] -> Target(Y): void
Context (X): ['form', 'void', 'upon', 'face'] -> Target(Y): darkness
Context (X): ['void', 'darkness', 'face', 'deep'] -> Target(Y): upon
Context (X): ['spirit', 'god', 'upon', 'face'] -> Target (Y): moved
Context (X): ['god', 'moved', 'face', 'waters'] -> Target (Y): upon
Context (X): ['god', 'said', 'light', 'light'] -> Target (Y): let
Context (X): ['god', 'saw', 'good', 'god'] -> Target (Y): light
前面的输出应该让你对X如何形成我们的上下文单词有更多的了解,我们正试图根据这个上下文预测目标中心单词Y。例如,如果原始文本是“in the beginning god created heaven and earth”,经过预处理和删除停止词后,就变成了‘beginning god created heaven earth’ ,而对于我们来说,我们正在努力实现的就是这个目标。给定[beginning, god, heaven, earth] 作为上下文,预测目标中心词是什么,在本例中是' created ' 。
构建CBOW模型架构
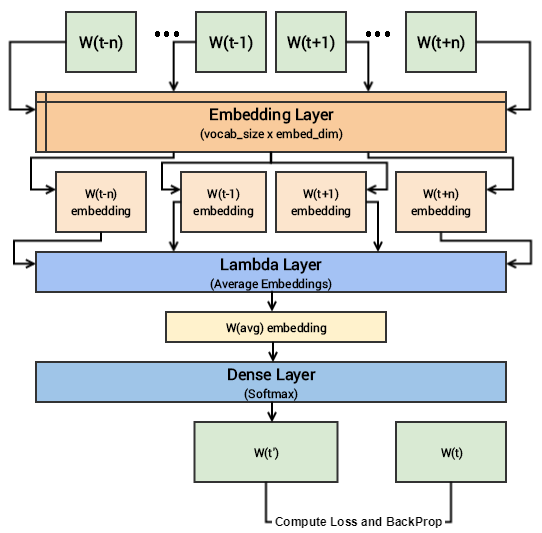
我们现在利用keras构建CBOW模型的深度学习架构。为此,我们的输入是传递给嵌入层(用随机权重初始化)的上下文单词。词嵌入被传播到λ层,做词嵌入的平均 (叫CBOW是因为在做平均的时候我们真的不考虑上下文词的顺序),我们把平均后的向量送到一个dense的softmax层去预测我们的目标词。我们将其与实际的目标字匹配,通过利用categorical_crossentropy损失计算损失,并对每个epoch执行反向传播来更新嵌入层。下面的代码向我们展示了我们的模型架构。
import keras.backend as K
from keras.models import Sequential
from keras.layers import Dense, Embedding, Lambda
# build CBOW architecture
cbow = Sequential()
cbow.add(Embedding(input_dim=vocab_size, output_dim=embed_size, input_length=window_size*2))
cbow.add(Lambda(lambda x: K.mean(x, axis=1), output_shape=(embed_size,)))
cbow.add(Dense(vocab_size, activation='softmax'))
cbow.compile(loss='categorical_crossentropy', optimizer='rmsprop')
# view model summary
print(cbow.summary())
# visualize model structure
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(cbow, show_shapes=True, show_layer_names=False,
rankdir='TB').create(prog='dot', format='svg'))
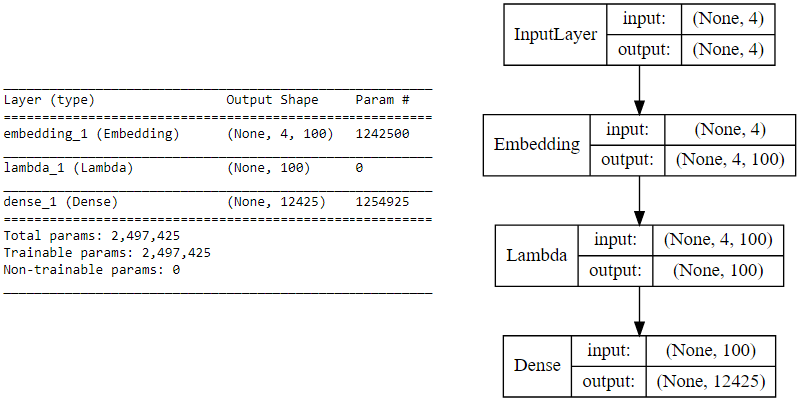
如果你对上述深度学习模型的形象化仍有困难。可以看看下图:
训练模型
在完整的语料库上运行这个模型需要相当多的时间,所以我只运行了5个epochs。你可以利用以下代码,并在必要时训练更多的时间。
for epoch in range(1, 6):
loss = 0.
i = 0
for x, y in generate_context_word_pairs(corpus=wids, window_size=window_size, vocab_size=vocab_size):
i += 1
loss += cbow.train_on_batch(x, y)
if i % 100000 == 0:
print('Processed {} (context, word) pairs'.format(i))
print('Epoch:', epoch, '\tLoss:', loss)
print()
Epoch: 1 Loss: 4257900.60084
Epoch: 2 Loss: 4256209.59646
Epoch: 3 Loss: 4247990.90456
Epoch: 4 Loss: 4225663.18927
Epoch: 5 Loss: 4104501.48929
注意:运行这个模型是计算量很大的,如果使用GPU训练,会好一点。我在AWS的**p2上训练过这个。用的是Tesla K80 GPU,它花了我近1.5小时,只有5个epochs!
一旦这个模型被训练好,相似的单词应该就有相似的基于嵌入的权值,我们可以测试一下相似性。
获取词嵌入
要为整个词汇表获取词嵌入,可以利用下面的代码从嵌入层提取。我们不接受位置为0的嵌入,因为它属于 (PAD) ,这并不是一个真正的单词。
weights = cbow.get_weights()[0]
weights = weights[1:]
print(weights.shape)
pd.DataFrame(weights, index=list(id2word.values())[1:]).head()

可以清楚地看到,正如前面的输出所描述的,每个单词都有一个dense的大小为“(1x100)”的嵌入。让我们尝试根据这些嵌入为感兴趣的特定单词找到一些上下文相似的单词。为此,我们基于dense的嵌入向量,在我们的词汇表中建立一个成对的距离矩阵,然后根据最短的欧氏距离找出感兴趣的每个单词的n个最近邻。
from sklearn.metrics.pairwise import euclidean_distances
# compute pairwise distance matrix
distance_matrix = euclidean_distances(weights)
print(distance_matrix.shape)
# view contextually similar words
similar_words = {search_term: [id2word[idx] for idx in distance_matrix[word2id[search_term]-1].argsort()[1:6]+1]
for search_term in ['god', 'jesus', 'noah', 'egypt', 'john', 'gospel', 'moses','famine']}
similar_words
(12424, 12424)
{'egypt': ['destroy', 'none', 'whole', 'jacob', 'sea'],
'famine': ['wickedness', 'sore', 'countries', 'cease', 'portion'],
'god': ['therefore', 'heard', 'may', 'behold', 'heaven'],
'gospel': ['church', 'fowls', 'churches', 'preached', 'doctrine'],
'jesus': ['law', 'heard', 'world', 'many', 'dead'],
'john': ['dream', 'bones', 'held', 'present', 'alive'],
'moses': ['pharaoh', 'gate', 'jews', 'departed', 'lifted'],
'noah': ['abram', 'plagues', 'hananiah', 'korah', 'sarah']}
您可以清楚地看到,其中一些在上下文上是有意义的 (god, heaven), (gospel, church) 等等,而有些可能没有意义。训练时间越长,效果往往越好。现在,我们将探讨与CBOW相比通常给出更好结果的skip-gram架构。
Skip-gram模型
Skip-gram模型体系结构实现与CBOW模型相反的功能。它预测给定目标单词(中心单词)的源上下文单词(周围单词)。考虑到我们前面简单的句子,“the quick brown fox jumps over the lazy dog”。如果我们使用CBOW模型,就会得到一对(context_window, target_word),其中如果我们考虑一个大小为2的上下文窗口,就会得到([quick, fox], brown), ([the, brown], quick), ([the, dog], lazy),等等。现在考虑到Skip-gram模型的目标是根据目标单词预测上下文,该模型通常将上下文和目标颠倒过来,并尝试根据目标单词预测每个上下文单词。因此,任务变成了预测给定目标单词[quick, fox]的上下文'brown' 或[the, brown]给定目标单词'quick',以此类推。因此,该模型是基于target_word预测context_window单词。
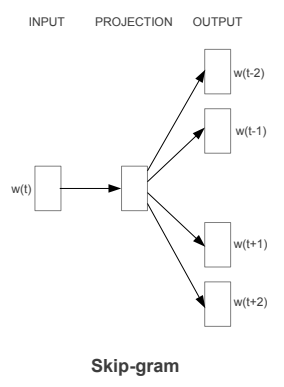
正如我们在CBOW模型中所讨论的,我们现在需要将这个Skip-gram架构建模为一个深度学习分类模型,这样我们就可以将目标单词作为输入并预测上下文单词。这变得有点复杂,因为我们在上下文中有多个单词。我们将每个(target, context_words)对分解为多个(target, context)对,这样每个上下文只包含一个单词,从而进一步简化了这个过程。因此,我们前面的数据集被转换成成对的,比如(brown,quick),(brown,fox), (quick, the), (quick, brown)等等。但是,如何监督或训练模型,使其知道什么是上下文相关的,什么不是?
为此,我们对Skip-gram模型输入(X, Y),其中X是我们的输入,Y是我们的标签。我们使用[(target, context), 1]对作为输入正样本,其中target是我们感兴趣的单词,context是发生在目标单词附近的上下文单词,正样本标签1 表示这是上下文相关的一对。我们还输入[(target, random), 0]对作为输入负样本,其中target仍然是我们感兴趣的单词,但是random只是从我们的词汇表中随机选择的一个单词,它与我们的目标单词没有上下文关系。因此,负样本标签0表示这是上下文无关的一对。我们这样做是为了让模型能够了解哪些词对与上下文相关,哪些不相关,并为语义相似的词生成类似的嵌入。
实现Skip-gram模型
现在让我们从头开始实现这个模型,以了解幕后的工作原理,并将其与CBOW模型的实现进行比较。我们将像往常一样利用包含在 norm_bible 变量中的圣经语料库来训练我们的模型。工作将集中于五个部分:
1. 构建语料库词汇表
2. 构建skip-gram[(target, context), relevancy]生成器
3. 构建skip-gram模型结构
4. 训练模型
5. 得到词嵌入
构建语料库词汇表
这个和CBOW是一样的。
构建skip-gram[(target, context), relevancy]生成器
现在开始构建我们的skip-gram生成器了,它将像我们前面讨论的那样给我们一对单词和它们的相关性。幸运的是,keras有一个漂亮的skipgrams函数,我们不需要像在CBOW中那样手动实现这个生成器。
注意:函数skipgrams(…)出现在keras.preprocessing.sequence中。
该函数将一个单词索引序列(整数列表)转换为以下形式的单词元组:
- (word, 在同一个窗口中的word),标签1(正样本)。
- (word,词汇表中的random word),标签0(负样本)。
from keras.preprocessing.sequence import skipgrams
# generate skip-grams
skip_grams = [skipgrams(wid, vocabulary_size=vocab_size, window_size=10) for wid in wids]
# view sample skip-grams
pairs, labels = skip_grams[0][0], skip_grams[0][1]
for i in range(10):
print("({:s} ({:d}), {:s} ({:d})) -> {:d}".format(
id2word[pairs[i][0]], pairs[i][0],
id2word[pairs[i][1]], pairs[i][1],
labels[i]))
(james (1154), king (13)) -> 1
(king (13), james (1154)) -> 1
(james (1154), perform (1249)) -> 0
(bible (5766), dismissed (6274)) -> 0
(king (13), alter (5275)) -> 0
(james (1154), bible (5766)) -> 1
(king (13), bible (5766)) -> 1
(bible (5766), king (13)) -> 1
(king (13), compassion (1279)) -> 0
(james (1154), foreskins (4844)) -> 0
可以看到我们已经成功地生成了所需的skip-grams,还可以根据标签(0或1)清楚地看到哪些是相关的,哪些是不相关的。
构建skip-gram模型结构
现在,我们在利用keras来为skip-gram模型构建我们的深度学习架构。为此,我们的输入将是我们的目标单词和上下文或随机单词对。然后传递到一个嵌入层(用随机权重初始化)。一旦我们获得了目标词和上下文词的词嵌入,我们将它传递到一个合并层,在那里我们计算这两个向量的点积。然后我们将这个点积值传递给一个dense的sigmoid层,该层根据这对单词是上下文相关的还是随机的单词(Y)来预测是1还是0。我们将其与实际的关联标签(Y)匹配,通过mean_squared_error计算损失,并对每个epoch反向传播来更新嵌入层。下面的代码向我们展示了我们的模型架构。
from keras.layers import Merge
from keras.layers.core import Dense, Reshape
from keras.layers.embeddings import Embedding
from keras.models import Sequential
# build skip-gram architecture
word_model = Sequential()
word_model.add(Embedding(vocab_size, embed_size,
embeddings_initializer="glorot_uniform",
input_length=1))
word_model.add(Reshape((embed_size, )))
context_model = Sequential()
context_model.add(Embedding(vocab_size, embed_size,
embeddings_initializer="glorot_uniform",
input_length=1))
context_model.add(Reshape((embed_size,)))
model = Sequential()
model.add(Merge([word_model, context_model], mode="dot"))
model.add(Dense(1, kernel_initializer="glorot_uniform", activation="sigmoid"))
model.compile(loss="mean_squared_error", optimizer="rmsprop")
# view model summary
print(model.summary())
# visualize model structure
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(model, show_shapes=True, show_layer_names=False,
rankdir='TB').create(prog='dot', format='svg'))
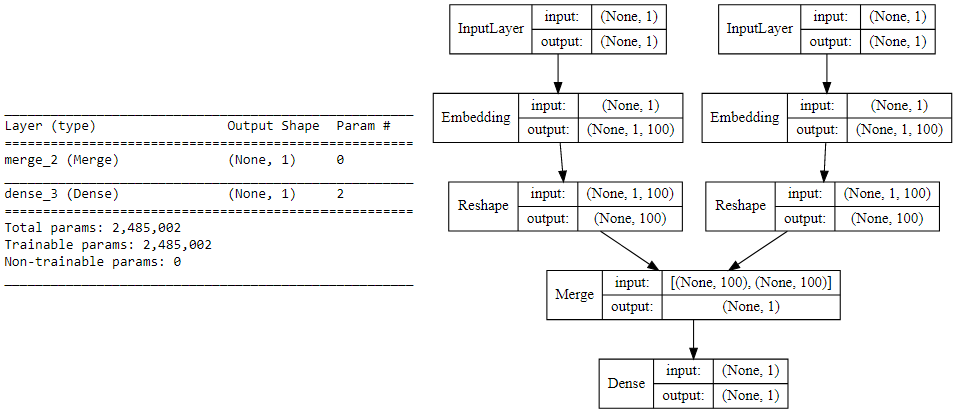
skip-gram模型的可视化:
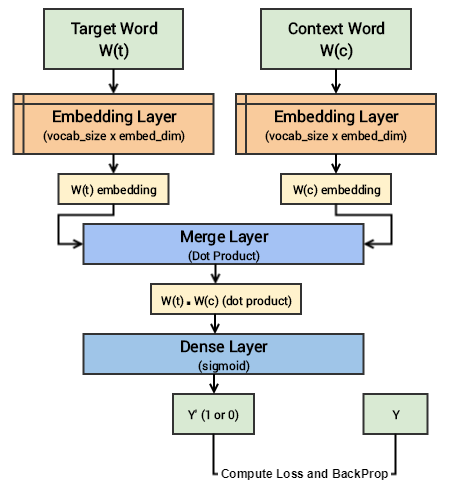
训练模型
在我们的完整语料库上运行模型需要相当多的时间,但比CBOW模型要少。所以我只运行了5个epochs。你可以利用以下代码,并在必要时训练更长的时间。
for epoch in range(1, 6):
loss = 0
for i, elem in enumerate(skip_grams):
pair_first_elem = np.array(list(zip(*elem[0]))[0], dtype='int32')
pair_second_elem = np.array(list(zip(*elem[0]))[1], dtype='int32')
labels = np.array(elem[1], dtype='int32')
X = [pair_first_elem, pair_second_elem]
Y = labels
if i % 10000 == 0:
print('Processed {} (skip_first, skip_second, relevance) pairs'.format(i))
loss += model.train_on_batch(X,Y)
print('Epoch:', epoch, 'Loss:', loss)
Epoch: 1 Loss: 4529.63803683
Epoch: 2 Loss: 3750.71884749
Epoch: 3 Loss: 3752.47489296
Epoch: 4 Loss: 3793.9177565
Epoch: 5 Loss: 3716.07605051
模型训练好之后,相似的单词应该有相似的基于嵌入的权重。
得到词嵌入
要为整个词汇表获取单词嵌入,可以利用下面的代码从嵌入层提取相同的单词。请注意,我们只对目标单词嵌入感兴趣,因此我们将从 word_model嵌入层提取嵌入。我们没有在位置0处进行嵌入,因为词汇表中没有一个单词的数字标识符为0,我们忽略了它。
merge_layer = model.layers[0]
word_model = merge_layer.layers[0]
word_embed_layer = word_model.layers[0]
weights = word_embed_layer.get_weights()[0][1:]
print(weights.shape)
pd.DataFrame(weights, index=id2word.values()).head()
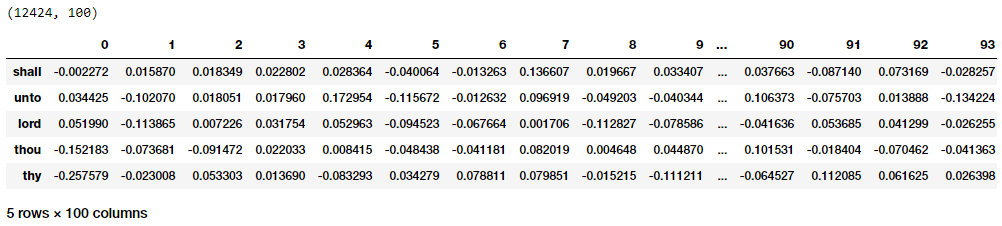
可以清楚地看到,正如前面的输出所描述的,每个单词都有一个dense的大小为(1x100)的嵌入,类似于我们从CBOW模型中得到的结果。现在让我们对这些dense的嵌入向量使用欧氏距离度量来为词汇表中的每个单词生成成对的距离度量。然后,我们可以根据最短的欧氏距离找到感兴趣的每个单词的n个最近邻,这与我们在CBOW模型的嵌入中所做的类似。
from sklearn.metrics.pairwise import euclidean_distances
distance_matrix = euclidean_distances(weights)
print(distance_matrix.shape)
similar_words = {search_term: [id2word[idx] for idx in distance_matrix[word2id[search_term]-1].argsort()[1:6]+1]
for search_term in ['god', 'jesus', 'noah', 'egypt', 'john', 'gospel', 'moses','famine']}
similar_words
(12424, 12424)
{'egypt': ['pharaoh', 'mighty', 'houses', 'kept', 'possess'],
'famine': ['rivers', 'foot', 'pestilence', 'wash', 'sabbaths'],
'god': ['evil', 'iniquity', 'none', 'mighty', 'mercy'],
'gospel': ['grace', 'shame', 'believed', 'verily', 'everlasting'],
'jesus': ['christ', 'faith', 'disciples', 'dead', 'say'],
'john': ['ghost', 'knew', 'peter', 'alone', 'master'],
'moses': ['commanded', 'offerings', 'kept', 'presence', 'lamb'],
'noah': ['flood', 'shem', 'peleg', 'abram', 'chose']}
从结果中可以清楚地看到,对于感兴趣的每个单词,许多相似的单词都是有意义的,并且与我们的CBOW模型相比,我们获得了更好的结果。现在我们用t-SNE来可视化一下。
from sklearn.manifold import TSNE
words = sum([[k] + v for k, v in similar_words.items()], [])
words_ids = [word2id[w] for w in words]
word_vectors = np.array([weights[idx] for idx in words_ids])
print('Total words:', len(words), '\tWord Embedding shapes:', word_vectors.shape)
tsne = TSNE(n_components=2, random_state=0, n_iter=10000, perplexity=3)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(word_vectors)
labels = words
plt.figure(figsize=(14, 8))
plt.scatter(T[:, 0], T[:, 1], c='steelblue', edgecolors='k')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')
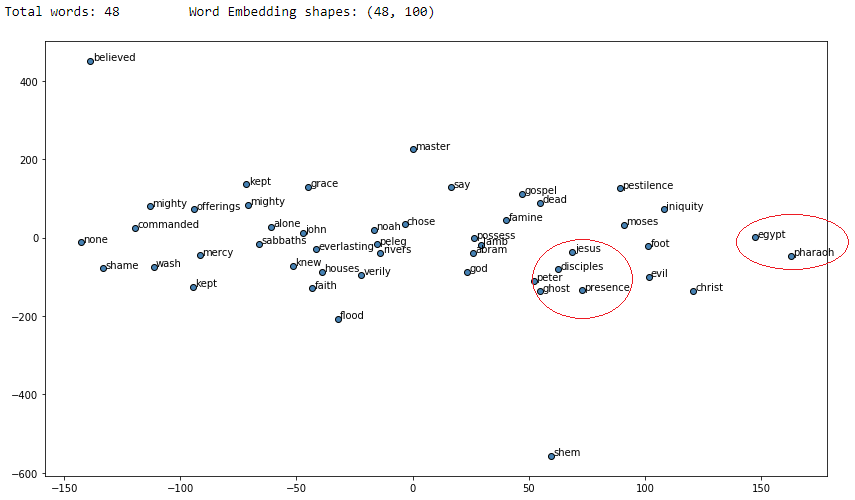
我用红色标记了一些圆圈,它们似乎显示了在向量空间中位置相近的上下文相似的不同单词。
(未完待续)

星标我,每天多一点智慧
