文章发布于公号【数智物语】 (ID:decision_engine),关注公号不错过每一篇干货。
作者 | 中国科学院、北京航空航天大学、百度研究院团队
译者 | 凯隐
编辑 | 夕颜
出品 | AI科技大本营(ID: rgznai100)
导读:生成对抗网络(GAN)是近年大热的深度学习模型,中国科学院相关团队注意到,在多领域图片转换任务中,生成图片中会残留一些源类别特征,通俗来讲就是和输入源图片或多或少都有相似之处。针对这个问题,中国科学院、北京航空航天大学、百度研究院团队联合提出了一个神奇的 UGAN 模型,它可以去除生成图片中保留的源类别信息,使得生成图片的源类别变得更加难以追踪,即让生成图片的伪装性更强,掩盖原图片的“遗传”信息,使其看起来与源图相似性变弱,甚至完全不相同。
01什么是多领域图像转换?
图像转换代表一类视觉和图像问题,主要目的是学习输入图像从一个类别域到另一个类别域的转换,例如表情转换,输入人脸面无表情的图像,输出该人脸在生气、开心、难过、害怕等一系列表情下对应的图像。风格转换,输出原始图片在不同亮度、光照等风格下的转换图片。通常每一中类型的转换都需要一个专门的模型去处理(例如 CycleGAN[1]),这样做非常低效,StarGAN[2] 进一步实现了用统一的框架来完成多个不同领域之间的转换,即多领域图像转换。
02生成图片的源特征残留问题
类似 StarGAN 的多领域图像转换模型,得到的生成图片(translated images)往往会保留原始类别的特征,因此,本文提出了 Untraceble GAN(UGAN),即无法溯源的GAN模型,能解决源特征残留问题,如下图所示:

图1 UGAN和StarGAN的对比效果图
在年龄转换(Aging),化妆风格转换(makeup),表情转换(Expression)三个不同的任务中,UGAN 的转换程度都要比StartGAN更彻底,例如在年龄转换中,StarGAN 的结果看起来仍然像成年人而 UGAN 的结果更像小孩。这表明 UGAN 在生成目标类别特征的同时,还能去除原始特征,这使得生成图片的源类别变得更加难以追踪。在结构上,UGAN 额外包含了一个源类别分类器,用来判别生成图片从哪个源类别转换而来,这有助于了解生成图片是否保留了源类别的特征。
03UGAN 网络结构
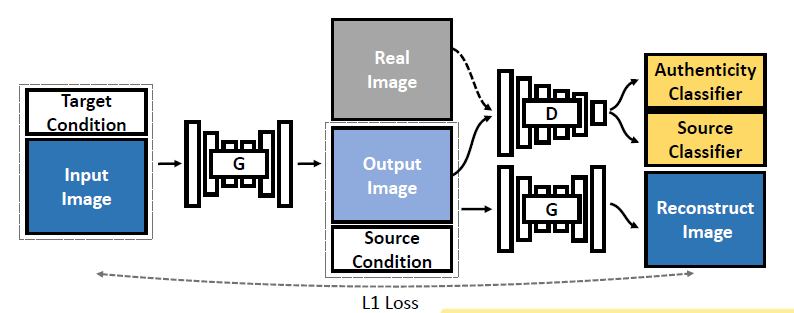
图2 UGAN 网络结构
网络结构如图 2,输入数据的是源图像和目标类别(Target Condition),首先经过转换器 G 得到生成图片(Output Image),之后再和源类别信息(Source Condition)以及真实图片(Real Image)一起输入到判别网络 D 中。不同于传统 GNN,判别网络 D 需要连接两个分类器(黄色模块),不仅需要真实性判别器(Authenticity Classifier)来判断图片是真实图片还是生成图片,还需要通过源类别分类器(Source Cclassifier)来确定生成图片对应的输入图片的类别(源类别)。
此外,生成图片和源类别还作为转换器 G 的输入,用于重构源输入图片。因此,转换器 G 由三部分监督:首先通过训练 G 来迷惑判别模型 D 的真实性判别器,这是生成对抗网络的基本功能;接着根据生成图片和源类别,来训练 G 重构输入图片,这是为了保证网络的循环稳定性[1];最后训练 G 来迷惑源类别分类器,让其相信生成图片的是从目标类别转换而来的,这是为了进一步去除生成图片中的源类别信息,使其更贴近目标类别。 由于添加了源类别作为监督信息,因此随着对抗训练的进行,生成图片能够逐渐摆脱源类别所具有的特征,而更贴近目标类别。
04UGAN的三个目标函数
要通过真实性分类器,源类别分类器,图片重构器对转换器G进行监督学习,就需要设计相应的目标函数(损失函数)。
01真实性分类器
对于真实性分类器 Da ,作者参考了WGAN-gp[3]中提出的对抗损失函数来限制生成图片和目标类别的联合分布:
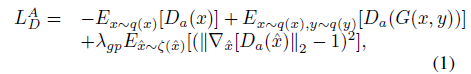
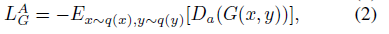
公式 1 是判别模型 D 的目标函数,公式 2 是生成器 G 的目标函数。x 和 y 代表图片和相应类别, x 和 y 都分别服从分布 q(x) 和 q(y),公式1类似交叉熵损失函数, -Ex~q(x)[Da(x)] 表示输入图片 x 被分类正确时的奖励,相应的的第二部分表示分类成生成器输出类别时的惩罚,第三部分则是一个梯度惩罚项,通过一阶莱布尼茨函数来强化判别能力。公式2则正好是公式1取反,也就是说判别模型表现越好,生成模型表现越差。
02图片重构器
训练图片重构器是为了提高网络的循环稳定性(Cycle Consistence),这一部分主要参考了工作[1],目标函数为:
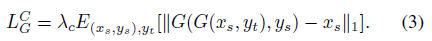
即尽量保证重构图片与原始输入图片相同,这里带下标 s 的变量表示源图片或源类型,带下标 t的表示生成图片或目标类型。
03源类别分类器
训练源类别分类器 Ds 是为了解决源特征遗留的问题,对于真实的图片而言,源类别和目标类别相同,而对于生成图片,分类器应该准确识别其源类别。相反,转换器 G 就是要让分类器无法找到生成图片的真实源类别,而是将错误的类别作为其源类别。因此二者的目标函数也存在负相关的关系:
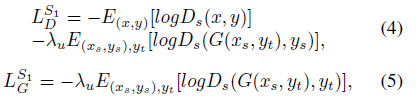
其中公式(4)是源类别分类器的损失函数,(5)是生成器 G 的损失函数。形式上和真实性分类器相同。然而目标类型yt的特征混合了从yt采样得到的真实图片xt以及生成图片的特征,因此生成的图片特征并不纯净,为了完全从目标类型yt来合成图片,用额外的参数C来区别真实图片和生成图片:

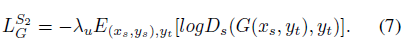
这使得 Ds 不仅能确定图片的源类别,还能判断目标图片是真实图片还是生成的假图片,相反,也使得生成器 G 生成的图片变得更加难以追踪。
04最终目标函数
将各个分类器的损失函数叠加,以及对应的生成器损失函叠加,就能得到最终的目标函数:

05实验步骤及结果
该团队主要在年龄转换、化妆风格转换、表情转换三个任务上开展对比实验,相应数据集是 Face aging、MAKEUP-A5 和 CFEE。由于本文主要是解决 StarGAN[2] 中存在的源特征存留问题,因此所有实验的基线对比工作都是 StarGAN。实验的评价指标有 Intra FIDs、AMT、余弦相似度。年龄转换相关实验额外添加 CAAE 和 C-GAN 作为基线对比。实验结果如下:

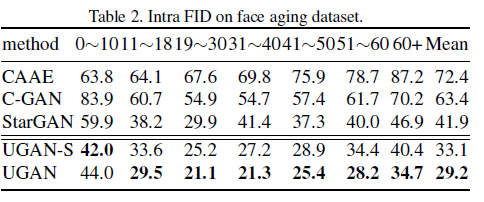
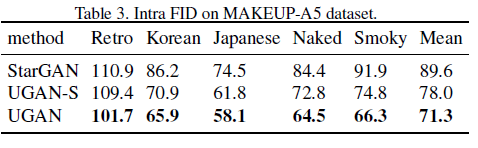

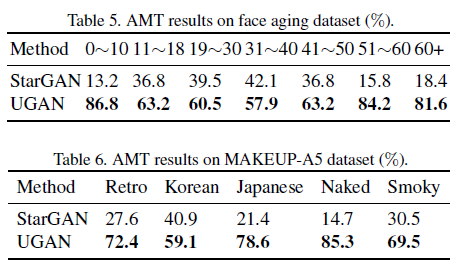
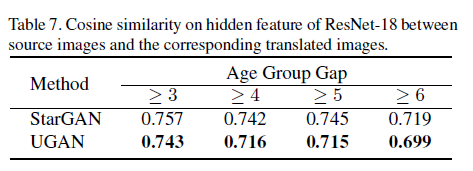
可以看到,在各项任务和指标下,UGAN 都优于 StarGAN。此外,直观地观察生成图片,可以发现 UGAN 生成的图片更好的去除了原始输入图片的特征,具有更强的源类别特征去除能力:
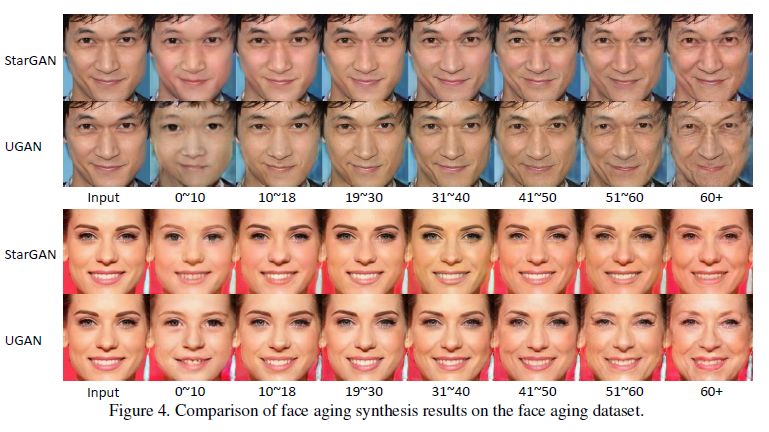

UGAN 在去除源类别信息上效果显著,使得生成图片技术更加成熟,生成图像伪装性更强,为 GAN 的研究打开了新的思路。
参考论文:
[1] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image to image translation using cycle-consistent adversarial networks.arXiv:1703.10593, 2017.
[2] Y. Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo. Stargan: Unified generative adversarial networks for multidomain image-to-image translation. In CVPR, 2018.
[3] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. C. Courville. Improved training of wasserstein gans. In NIPS, 2017.
原文链接:https://arxiv.org/pdf/1907.11418.pdf


星标我,每天多一点智慧