前几天都在测试PipelineDB的内容,看到可以PipelineDB把Kafka当做流的来源,就像测试一下。
发现手上的版本还是0.8.2.2,就下了一个新版本0.10.1, 同时看了一下文档,发现Kafka核心的周边多了好多东西。
最主要的就是kafka-connect和kafka-stream,把实时ETL和流计算都完成了,对我这等不会编程的人可是重大利好。
Kafka周边就都集成在Confluent Platform下了:
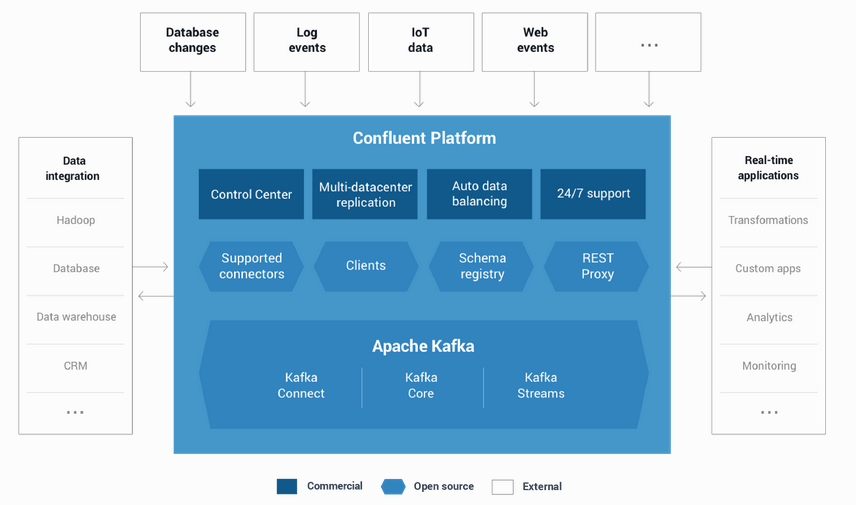
官方的文档见: http://docs.confluent.io
起步的同学可以直接拿来用的官方示例,
知乎上也有个介绍kafka-connect( https://zhuanlan.zhihu.com/p/21262642)还有视频链接额,也很好。
以下就借用官方的几张图介绍一下能做什么,
kafka-connect的功能示意图:从MySQL读取数据落到hadoop里面,原来很多功能需要flume中转,现在都不要了^-^

具体的 支持的接口列表https://www.confluent.io/product/connectors/
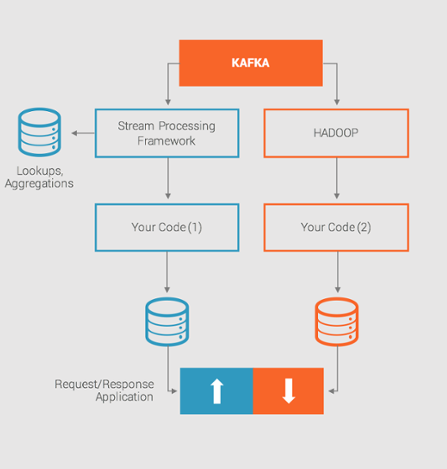
kafka-stream有2个重要特性,支持窗口功能和基于记录的流处理(不是micro-batch messages)
那一张图示意一下流程,注意可以基于行的lookup而且支持基于窗口的Aggregate:
PS:
今天把《量子物理史话——上帝掷骰子吗?》看了一大半了,前半部的故事说得不错,粒子论和波动论的螺旋式上升、迭代式发展,最后变成了波粒二象性,和谐统一了^-^。后半部看了些,已经觉得有点脑洞大开了,偏哲学了。
不过从粒子论和波动论的相互竞争我想到了BI\DI和大数据的关系,作为传统的BI人虽然也在不停学习Hadoop相关内容,但是我始终有个疑问,流的处理、或者不是很大量的数据处理,我需要这么重量级工具吗?有没有更好的免费的应用方案? 使用起来有没有更好的工具?
从Kafka和Pipelinedb我觉得差不多有了,可以构成基本的应用架构了(当然稳定性还要再看)。 最近我在这方面会多看一些。
