第1、2章主要讲似然函数怎么编写,先验概率使用均匀分布,但实际问题往往更复杂,先验概率可能也很复杂, 这章主要用火车头的示例说了先验概率怎么使用幂律分布预估,并且讲到点估计和区间估计。
具体还是看示例:
示例1:骰子问题,
骰子问题主要用来总结了第1、2章说的通用方法论:
示例的具体表述:有多个面的骰子,随机拿了一个,扔了多次,最可能的骰子是哪一个。
这个示例和先前的几个示例解题方法基本一样,先验概率使用均匀分布,主要讨论似然度怎么计算,也就是似然函数怎么编写。
通用的一般的方法是:
1.选择假设的表示方法
2.选择数据的表示方法
3.编写似然函数
class Dice(Suite):
def Likelihood(self, data, hypo):
if hypo < data:
return 0
else:
return 1.0/hypo
使用即可
for roll in [6, 8, 7, 7, 5, 4]:
suite.Update(roll)
示例2:火车头问题
这个示例的不同点是似然度和示例1一样,但是先验概率就不能使用均匀分布了,
按以往情况可以使用幂律(Posterior distribution based on a power law prior, compared to a uniform prior)
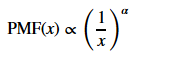
class Train(Dice):
def __init__(self, hypos, alpha=1.0):
Pmf.__init__(self)
for hypo in hypos:
self.Set(hypo, hypo**(-alpha))
self.Normalize()
2种分布的结果
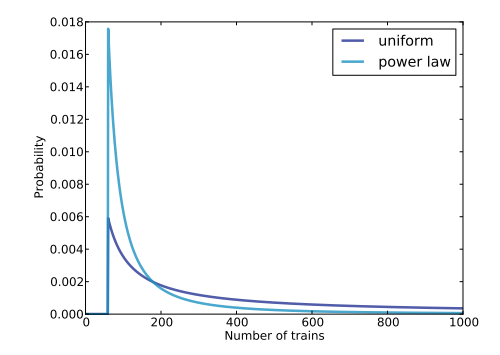
最后的结果也比较收敛:
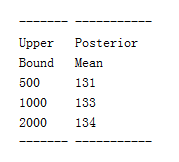
置信区间:
由于火车头的上限是不固定的,示例2开始的时候使用了1000的上限假设,实际上需要提供置信区间才能更好的描述问题:
提供了一个新的功能 Cumulative distribution functions(累计分布函数)来解决这个问题:
cdf = suite.MakeCdf()
interval = cdf.Percentile(5), cdf.Percentile(95)
print(interval)
