贝叶斯思维这本书,还是需要一些数学思维的,我好久没碰这类内容了,看第1章理论的时候想明白用了居然2周。^-^
不过应该看明白了,后面可以看得快一点,这次先介绍一下1、2章内容。
第1章
第1章由于先看了中文版,然后看的代码和中文对不上,有些不明白,后来看了英文版才对上,建议可以对照着看(直接看英文版也可以的)。
最主要的关键词概念,我觉得看这个就可以了
Rewriting Bayes’s theorem with H and D yields:
p(H|D)=p(H)*p(D|H)/p(D)
p(H) is the probability of the hypothesis before we see the data, called the prior probability, or just prior.--先验概率
p(H|D) is what we want to compute, the probability of the hypothesis after we see the data, called the posterior.--后验概率
p(D|H) is the probability of the data under the hypothesis, called the likelihood.--似然度
p(D) is the probability of the data under any hypothesis, called the normalizing constant.--标准化常量
书中的示例喜欢用表格计算,
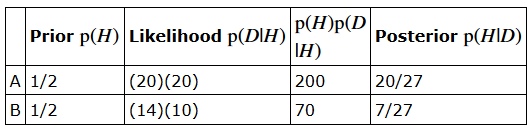
开始我一直没和p(H|D)=p(H)*p(D|H)/p(D)对上,后来想明白了,需要使用全概率公式,
公式变换成如下即可,
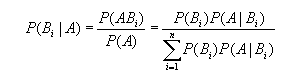
第2章
第2章介绍了一个The Bayesian framework:Suite 类
Suite 类是一个抽象类,继承的至少需要实现Likelihood即可
class Suite(Pmf):
"""Represents a suite of hypotheses and their probabilities."""
def Update(self, data):
"""Updates each hypothesis based on the data.
data: any representation of the data
returns: the normalizing constant
"""
for hypo in self.Values():
like = self.Likelihood(data, hypo)
self.Mult(hypo, like)
return self.Normalize()
以下就是应用suite类曲奇饼干的例子,
from thinkbayes import Suite
class cookie(Suite):
"""设置具体概率"""
Prop1=dict(vanilla=0.75, chocolate=0.25)
Prop2=dict(vanilla=0.1, chocolate=0.9)
"""假设"""
hypoA = dict(hypo1=Prop1, hypo2=Prop2)
hypoB = dict(hypo1=Prop2, hypo2=Prop1)
hypotheses = dict(A=hypoA, B=hypoB)
def Likelihood(self, data, hypo):
bag, color = data
mix = self.hypotheses[hypo][bag]
like = mix[color]
return like
def main():
suite = cookie('AB')
"""更新基于数据的假设"""
suite.Update(('hypo1', 'vanilla'))
suite.Update(('hypo1', 'vanilla'))
suite.Update(('hypo2', 'chocolate'))
suite.Print()
if __name__ == '__main__':
main()
Suite类使用说明
如果可以套到2个选一个的话,可以更新概率,自己计算
Prop1=dict(vanilla=0.75, chocolate=0.25)
Prop2=dict(vanilla=0.1, chocolate=0.9)
如果要重写Likelihood(似然度)函数就需要好好考虑下了。
Monty Hall就提供了单独的Likelihood函数。


