最近看了一下Apache Drill方面的内容,近期会做一下这方面的介绍。
总体介绍:
Apache Drill我的理解就是一个data federation的工具,可以用于数据探索方面、快速开发方面的工作,优点是和大数据平台紧密集合,并且在odbc/jdbc上支持标准的SQL语句,这一点还是很有用的。
以下是官网(http://drill.apache.org/docs/drill-introduction/)的总体介绍:
Drill is an Apache open-source SQL query engine for Big Data exploration. Drill is designed from the ground up to support high-performance analysis on the semi-structured and rapidly evolving data coming from modern Big Data applications, while still providing the familiarity and ecosystem of ANSI SQL, the industry-standard query language. Drill provides plug-and-play integration with existing Apache Hive and Apache HBase deployments.
Drill 1.8支持的数据源:
cp: JAR包中的文件,示例数据就是一个jar包中的json文件
dfs:直接访问文件,可以是本地也可以是分布式系统里
RDBMS:Postgres, MySQL, Oracle, MSSQL and Apache Derby
hbase、hive、mongo
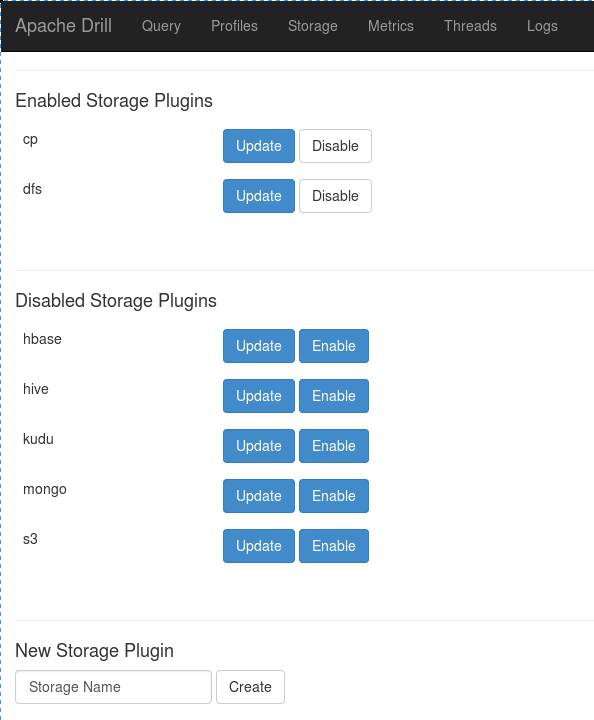
可以在http://ip:8047/storage维护,维护界面如下:
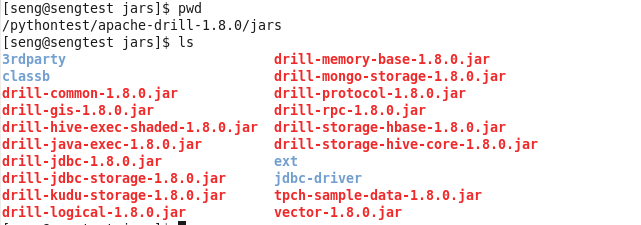
接口的jar包:
embedded mode安装
今天介绍一下embedded mode下的应用,这种模式主要用于各类验证工作。
内容主要参照 Drill in 10 Minutes(http://drill.apache.org/docs/drill-in-10-minutes/)
我使用的操作系统是Centos 6.5, 使用Apache Drill 1.8版本
1.准备工作
(1)java 1.7及以上
(2)下载并解压
官网下载 http://drill.apache.org,我用了是.8版本,解压
tar -xvf apache-drill-1.8.0.tar.gz
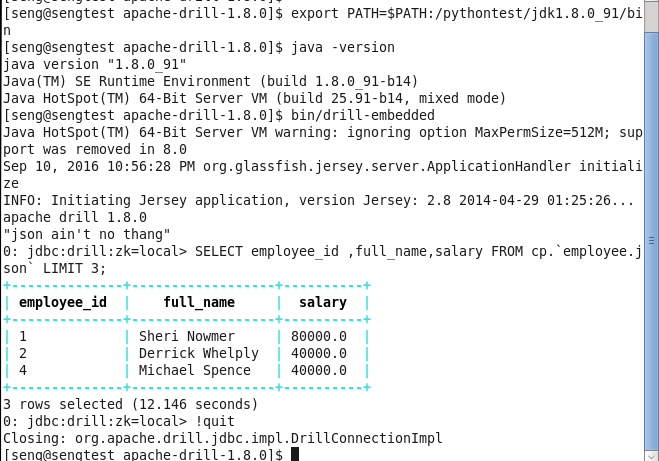
2.启动服务:
cd /pythontest/
cd apache-drill-1.8.0
export PATH=$PATH:/pythontest/jdk1.8.0_91/bin
bin/drill-embedded
3.简单查询:
系统自带了一个示例JSON文件:employee.json,存储在$installfiles/jars/3rdparty/foodmart-data-json.0.4.jar
SELECT employee_id ,full_name,salary FROM cp.`employee.json` LIMIT 3;
4.关闭服务:
!quit
完整过程示例: