最近一直在了解Python方面内容,看到数据小雄博客里说到:利用八爪鱼采集器对京东商城上商品评论采集
我就想怎么实现,就尝试了一下Scrapy这个工具
Scrapy目前正式发布的版本是1.0.5,不支持Python 3,但1.1版本就可以支持了,这个需要注意下。
我使用的环境是1.0.5版,系统运行在是在Ubuntu Desktop 14.04,使用pyenv 2.7.11
--首先看文档
http://doc.scrapy.org/en/1.0/intro/tutorial.html
1.安装过程
--安装依赖包
sudo apt-get install libssl-dev libffi-dev
--进入2.7.11环境
pyenv activate env32711
--安装
pip install Scrapy
---错误说明:
a. error
fatal error: ffi.h: No such file or directory
b.error
src/lxml/includes/etree_defs.h:14:31: fatal error: libxml/xmlversion.h: No such file or directory
--错误的解决参考
http://stackoverflow.com/questions/15759150/src-lxml-etree-defs-h931-fatal-error-libxml-xmlversion-h-no-such-file-or-di
2.探索如何爬取数据
Scrap把过程都简化了,只要定义具体的标记就可以了,
--激活环境
pyenv activate env2711
--打开scrap shell
scrapy shell http://club.jd.com/review/1601991-1-1-0.html
--寻找对应的标记就可以了 ,这是 http://club.jd.com/review/1601991-1-1-0.html这个页面中评论对应的html代码

--使用这段代码就可以读取信息了
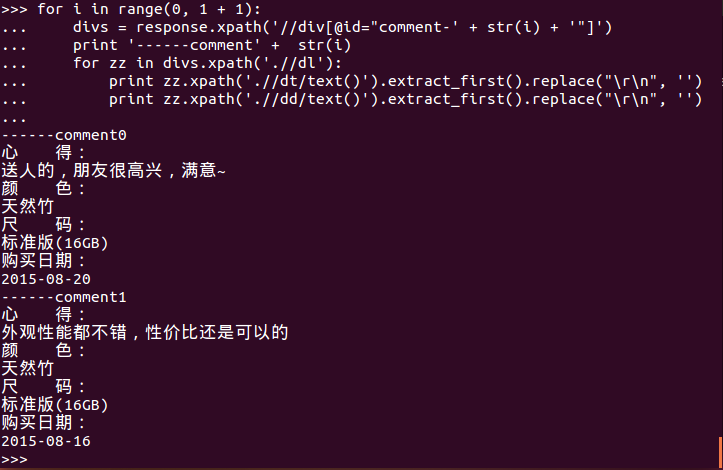
for i in range(0, 1 + 1):
divs = response.xpath('//div[@id="' + str(i) + '"]')
print '------comment' + str(i)
for zz in divs.xpath('.//dl'):
print zz.xpath('.//dt/text()').extract_first().replace("\r\n", '')
print zz.xpath('.//dd/text()').extract_first().replace("\r\n", '')
--结果就是这个
3.定义具体运行的爬虫过程
a.创建一个Scrap project
scrapy startproject tutorial
b. 定义一个项目列表
修改 ./tutorial/items.py
import scrapy
class DmozItem(scrapy.Item):
prodid = scrapy.Field()
userid = scrapy.Field()
type = scrapy.Field()
desc = scrapy.Field()
c.写一个spider
创建 ./tutorial/spiders/dmoz_spider.py
import scrapy
from scrapy.spiders import Spider
from scrapy.selector import Selector
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://club.jd.com/review/1601991-1-1-0.html/",
"http://club.jd.com/review/1601991-1-2-0.html"
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//ul/li')
items = []
for i in range(0, 1 + 1):
divs = response.xpath('//div[@id="' + str(i) + '"]')
for zz in divs.xpath('.//dl'):
item = DmozItem()
item['prodid'] = '1601991'
item['userid'] = 'userid'
item['type'] = zz.xpath('.//dt/text()').extract_first().replace("\r\n", '')
item['desc'] = zz.xpath('.//dd/text()').extract_first().replace("\r\n", '')
items.append(item)
return items
d.运行导出
scrapy crawl dmoz -o items.json -t jsonlines
或csv格式
scrapy crawl dmoz -o items.json -t csv
4.总结及下一步的内容
上面只是一个商品一页评论的读取,还需要做这些事情,这个下一次和大家分享
1.多页评论的读取
2多商品的读取


