引言
题目:a**2 + b**2 = c**2,a+b+c=1000,求解a,b,c
方法一
import time
start = time.time()
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a + b + c == 1000 and a**2 + b**2 == c**2:
print("a:{0},b:{1}, c:{2}".format(a, b, c))
end = time.time()
print(end - start)
import time
start = time.time()
for a in range(0, 1001):
for b in range(0, 1001):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a:{0},b:{1}, c:{2}".format(a, b, c))
end = time.time()
print(end - start)
时间复杂度O(n)
基础
通过运算的时间来进行度量,用n来进行表示。有几种情况:
常见的计算规则:
- 顺序:累加结构计算
- 循环:乘法结构计算
- 分支:取最大值
一般取的是最坏时间复杂度,考虑最坏的情况,同时忽略常数项
常见的时间复杂度
消耗的时间大小关系:%3C%20O(logn)%20%3C%20O(n)%20%3C%20O(nlogn)%20%3C%20O(n%5E2)%20%3C%20O(n%5E3)%20%3C%20O(2%5En)%3CO(n!)%3CO(n%5En))
timeit模块
主要功能是进行测试
from timeit import Timer
def t1():
li = []
for i in range(10000):
li.append(i)
def t2():
li = []
for i in range(10000):
li += [i]
def t3():
li = [i for i in range(10000)]
def t4():
li = []
for i in range(10000):
li.insert(0, i)
time1 = Timer("t1()", "from __main__ import t1")
print("append:", time1.timeit(10000))
time2 = Timer("t2()", "from __main__ import t2")
print("+:", time2.timeit(10000))
time3 = Timer("t3()", "from __main__ import t3")
print("[]:", time3.timeit(10000))
time4 = Timer("t4()", "from __main__ import t4")
print("insert:", time4.timeit(10000))
列表和字典的时间复杂度
列表
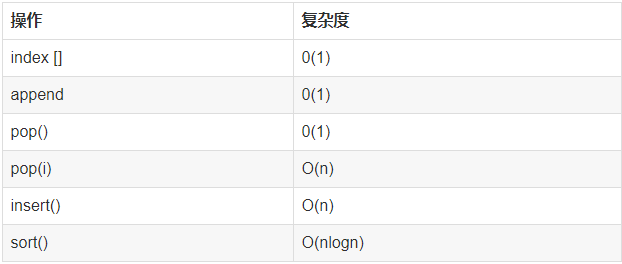
字典
操作复杂度
copy()O(n)
get,set,delete,contains,iterationO(1)
数据结构
数据结构是指数据对象中数据元素之间的关系,在Python中内置的数据结构,比如列表、字典、元组等,扩展结构:栈、队列等。
程序 = 数据结构 +算法
常见的操作:
顺序表
存储方式
数据本身是连续存储,每个元素占据固定大小的单元,元素下标是逻辑地址,包含:数据区+表头信息,两种存储方式:
- 一体式结构:表头信息和数据区连在一起,表头区包含容量和元素个数
- 分离式结构:表头信息和数据区分开存放,通过表头区的地址单元去指向数据区
扩充策略
- 每次固定的扩充数目:线性扩充,节省空间。扩充频繁,操作频繁
- 每次扩充容量加倍:减少扩充执行次数,浪费资源。以空间换取时间
链表
链表由来
顺序表的构建需要预先知道数据大小来申请连续的存储空间;再进行扩充的时候需要进行数据的迁移,很不方便。链表能够充分地利用计算机的存储空间,实现灵活的内存动态管理。
线性表包含顺序表和链表。在链表中,元素与元素之间通过链接构造起来的一系列存储结构中,每个节点(存储单元)中存放下一个节点的位置信息。。节点中包含:数据取 + 链接区(指针区)。最后一个没有指针区
单向链表
单向链表包含数据区和链接区。链接指向下一个链接表中的节点。最后一个节点指向空值(一竖一横表示)。
主要的操作是:
- is_empty()
- length()
- travel()
- add(item)
- append()
- insert()
- remove()
- search()
在Python的 中,a是个地址,保存的不是10,地址指向10。
中,a是个地址,保存的不是10,地址指向10。
顺序表和链表对比
顺序表
- 随机读取数据
- 查找很快,耗时主要是在拷贝和覆盖
- 存储空间必须是连续的
链表
- 增加了节点地指针区域,空间开销大,对存储空间的使用更加灵活
- 耗时主要是体现在:遍历查找
- 只记录头结点,如果想找到其他节点,必须通过遍历的方式去寻找
- 存储空间不是连续的:数据区+指针区,对离散空间能够充分利用
时间复杂度对比

为什么链表的时间复杂度增加,还要选择使用链表?
