广告:
欢迎参加我的课程:高质量数据库建模

上一节课,我们介绍了高质量数据建模的重大意义,本节课让我们一起学习高质量数据建模的流程。本节课分为两个部分,首先我会讲解数据建模的基本流程,然后再概要的介绍如何进行高质量数据建模,主要目的是让同学们对数据建模的基本流程有一个整体的认识,未来的课程里面我会对建模的每个阶段都做更为详细的讲解。

在建模的不同阶段,将数据模型分为三个层次,而每个层次的作用各有不同。首先是概念模型阶段,在这一层最主要的目的是确定系统的核心需求以及圈定范围边界。接着需要对概念模型求精,也就是创建逻辑模型,这一层是数据建模过程中最重要的工作,需要梳理业务规则并且了解底层的数据细节。接下来是物理建模,这一层需要从性能、存储、访问以及开发等多方面考虑,尤其对于高并发或高容量等复杂系统需要做大量的优化工作。
我们会发现,数据建模和盖房子有很多相似之处,为了方便对建模的各个阶段的理解,这里我用盖房子为例对每个阶段进行阐释。
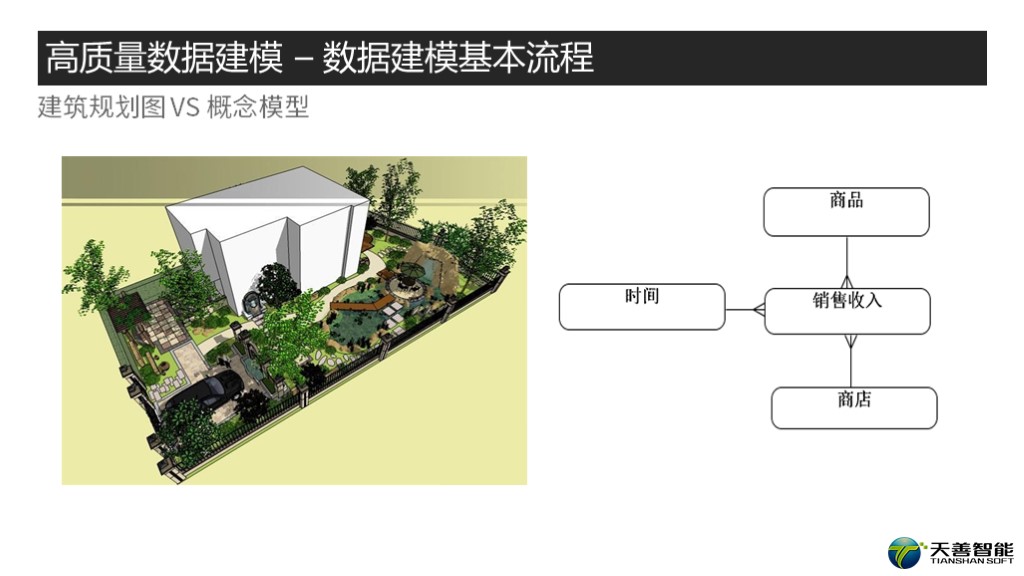
首先看概念模型,在概念模型阶段,非常类似于盖房子的建筑规划图阶段。很多建筑师或手绘或用个什么3dmax, ps之类的软件给你画一效果图,很多时候我们叫它愿景图。数据模型一般就是最核心的实体关系图,会把项目范围内的最核心的实体用关联关系标注出来。在这个阶段都需要了解哪些需求呢?
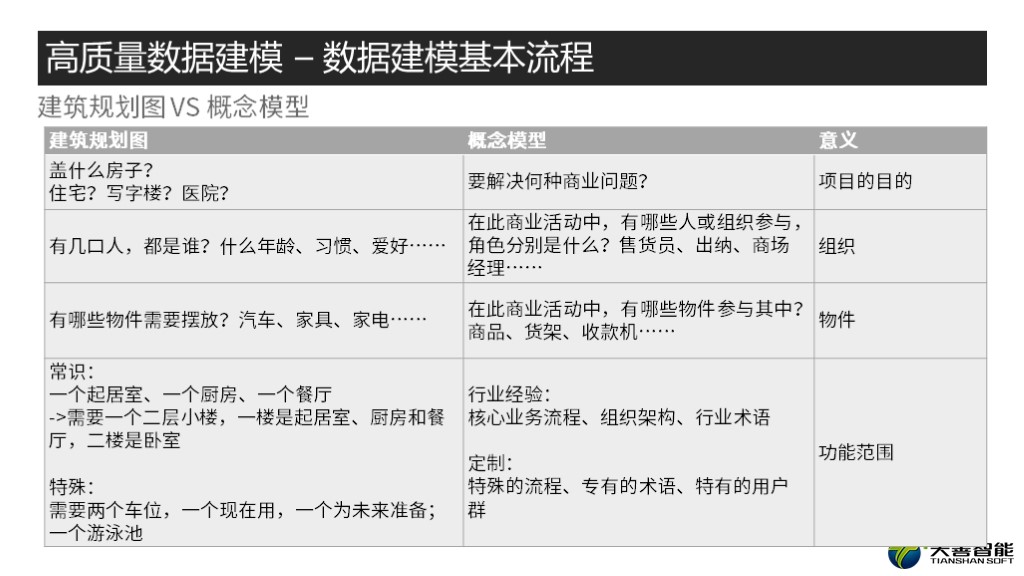
首先,要盖房子,我们得知道这房子要干什么用?是做住宅?还是写字楼,还是医院幼儿园。而从数据模型的角度理解就是,在建系统的商业目的是什么,要解决何种商业问题?
然后,确定了目的以后,假设是做住宅,那么建筑师需要了解,有哪些家庭成员是需要住在这栋未来的房子里的,包括他们的年龄,习惯,爱好等等。同时也需要考虑是不是未来会有新成员的加入,比如对于年长的客户儿子要娶媳妇是不是要同住,对于年轻的客户家里是不是要填新宝宝,是不是有的时候父母要过来同住?等等。而数据库的概念模型呢,需要了解未来这个系统里,会有哪些人哪些组织使用,各个流程又有哪些人员哪些组织会被涉及到,同时也需要兼顾未来的需求。
接下来,已经了解人员构成情况了,建筑设计师需要了解家里需要摆放哪些东西?比如家里有几部车?未来是不是需要添置?最基本的还需要添加各种家用电器,而这些和下面的介绍的内容又息息相关。在概念模型设计中也是一样的,有哪些物件需要参与进来,比如商品,货架,收款机等等。
记住,以上我说过的所有部分是有机的整体,也就是why/who/what/when/by which way,这些需要通盘结合起来考虑。这就需要结合一些我们的一些常识,建筑设计师就需要一些生活的常识,比如我们都知道,一个房子需要一个起居室,一个餐厅,还有厨房,以及根据家庭成员的结构需要几个卫生间。可能还有一些特殊的需求,比如两个车位,一个游泳池之类。数据建模工程师也同样,他需要具有一定的行业经验,需要了解核心的业务流程,组织架构的特点,行业的术语,并且根据企业的独特需求做定制化的考虑。这个也就是我们所说的功能范围。

在概念模型建设过程中,有一些总结下来的经验小贴士,有的不算是金科玉律,但也值得大家参考。
首先,我们要关注的是全局,而非细节。在需求调研之初,我们不要一下子就钻到细节里面去,一是会使项目的进度变慢,二是过于关注细节会不自觉的忽略一些整体方面的问题。你需要了解整个全貌,再去考虑细节。细节问题需要在逻辑模型和物理模型阶段考虑。
第二点,就是我们在概念模型阶段,其实就需要对整体架构进行思考。这里我的意思是物理架构方面的思考,比如选择什么样的架构?是不是要用云计算,用分布式还是集中式的系统?未来容量并发情况是否能够支撑?选什么样的产品,开源的数据库,还是商用数据库啊?是不是有特殊的需求需要NOSQL类的数据库解决?以什么样的方式建模,传统的3NF,又或者维度建模,又或者Data Vault?之类
三. 概念模型阶段通常是自上而下的模式,这里需要读大量的文档做课前工作,并且通过大量的会议进行反复沟通、澄清需求确认需求。
四. 在这个阶段,一般来说总是需要给出项目需要的基本时间以及项目计划草案,主要依据就是根据经验、以及对当前企业现有需求的认知。
五. 如果时间、系统选型的核心内容已经确定,如果项目是以数据为核心应用的话,那么需要粗略的估算出项目的费用,一般包括硬件、软件、人员等。
六. 尽管和项目最终的交付距离还很远, 但对于Data Modeler而言,这个阶段我认为是非常非常重要的。为什么啊?因为这个阶段通常是数据建模工程师和客户沟通的破冰阶段,在这个阶段双方达成共识是未来良好沟通的基础,并且很多做的好的项目,建模工程师(有很多时候建模工程师通常就是系统整体的架构师)会和核心业务人员建立好很好的私人关系,后面双方能够相互理解,并朝着同一个目标前进,可以说这是项目正常运转的非常重要的事情。可以脑补一下如果技术和业务相互扯皮相互推诿甚至相互拆台,这对项目的伤害有多大。

七, 出品的概念模型可以帮助划定系统边界,也就是说什么地方做什么地方不做,另外也能够帮助避免一些方向性的错误。
八, 当然业务和数据都精通的专家更好了,但对比数据专家,这个阶段更需要业务专家来配合。
九, 可以说概念模型是一个沟通的基础,假设你和客户讨论,讨论的内容是什么?依据什么来讨论?这个就是概念模型存在的意义,同时它也是逻辑模型非常重要的输入,逻辑模型其实就是概念模型逐步求精的结果。

那么,概念模型一般以什么样的交付品存在?通常需要注意什么?
首先,一定要用与客户一致的商业语言。这个目的主要是避免双方沟通产生歧义,另外对Data Modeler来说,也需要通过和客户取得一致,去融入角色。
另外,交付的东西尽可能用一页纸就可以描述的清楚,比如画实体关系图的时候不需要添加属性等信息,也不需要添加次要的实体(比如一些不重要子类实体以及引用类实体)。
在这个阶段,ER图里面是容许 多对多 关系存在的。
概念模型可以说是整个建模过程的第一个阶段,而这个阶段占据整个建模的工作量或许不到10%。本课程的重点都在当下我们描述的这个阶段上,也就是逻辑建模阶段。在大部分系统中,逻辑建模的工作量大约占到整个建模工作的60%-70%。
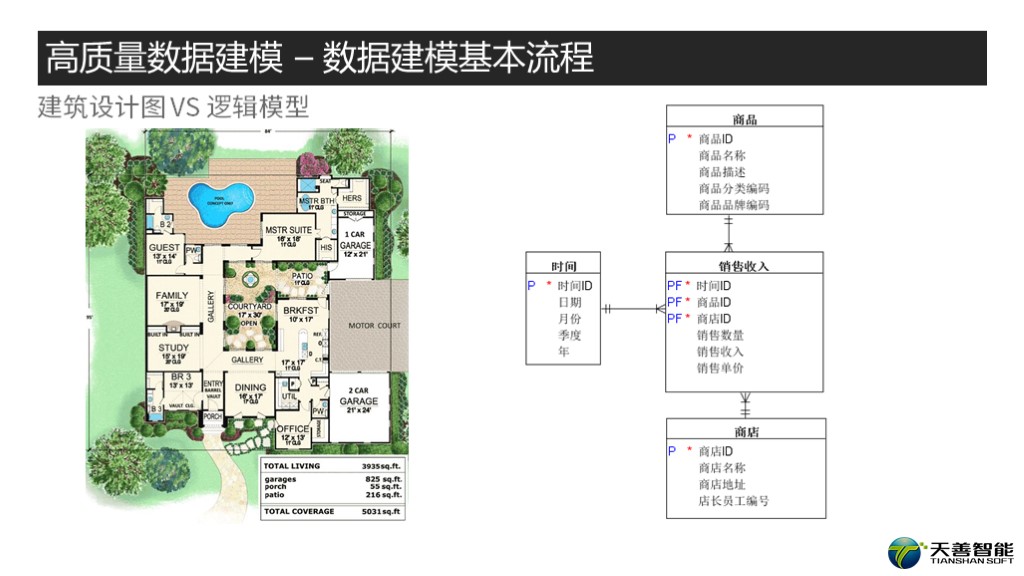
这里,我给出两张图,左边一张是建筑设计图,右边一张是数据逻辑模型图。
我们看到,在左图中,各个房间的尺寸(包括长,宽,面积),功能,也包括窗子,要摆放什么家具都标注的清清楚楚。而右图,和概念模型相比逻辑模型会细致到每个实体里的主键外键是什么,每个实体的属性会被一一列出。
(至于主键外键等概念,什么是请听下文分解)
那么对比建筑设计图和逻辑模型,我们可以发现很多相似之处。
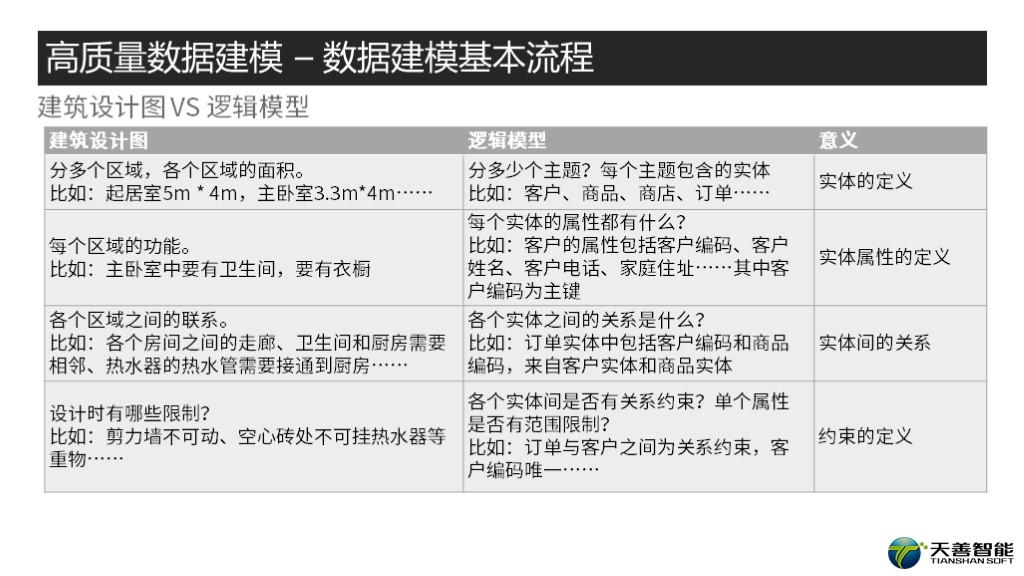
首先是实体的定义,就相当于在房子里面分多个区域,比如客厅,卧室,厨房,餐厅等等。对应于逻辑模型,就是客户、商品、订单等等。
那么是实体的属性呢?就相当于每个区域都有它特定的需求,比如卧室里要有衣橱、床、电视机等;餐厅要有餐桌;卫生间要有马桶、浴缸等等。对应逻辑模型比如: 客户属性需要知道客户的地址、电话、姓名等等。
那么实体和实体之间的关系呢?就相当于各个区域之间的联系,比如各个房间之间的走廊,卫生间和厨房需要相邻、热水器的热水管的是否接到厨房等等。对应逻辑模型,比如:订单实体中包含客户编码和商品编码,而这两个编码来自于商品和客户两个实体。
那么什么又是约束呢?比如在建筑设计中:剪力墙不可拆除、空心砖处不能挂热水器等等。同样的,在逻辑建模中,还需要关心各个实体之间的关联约束、单个实体的属性约束等等。比如订单的客户信息一定存在于客户表中,比如客户的编码是唯一的,等等。

和概念模型一样,这里我也罗列了一些逻辑建模中需要注意的地方。
首先,当你结束了逻辑建模,如果项目是以数据为核心应用的话,你就能够更精确推算出整个项目需要的时间,同时你也能估算出更精确的费用。
其次,如果你的实体数量超过100个,建议你使用术语表进行统一的规划定义,如果企业有现成的术语表更好不过,至于什么叫术语表以及如何使用,我会在后面的课程里有详细的描述。
第三, 建议采用3NF进行规范化建模
第四, 一定要先规范化,再逆规范化。逆规范化有些操作实际上是在物理层做的,但由于CASE工具的广泛使用,很多时候物理层的模型都是由逻辑层直接生成的,因此大部分使用CASE工具的建模,都会在逻辑层做大量的逆规范化操作。这里有个比喻形容的规范化和逆规范化之间的关系非常贴切,传说德国汽车生产车间拧奔驰上某个螺丝的操作是先逆时针拧四圈再顺时针拧半圈,而在中国被工人们直接改成拧三圈半,造成了同样的车同样的生产线,很多国产车质量比如进口车的质量。规范化和逆规范化的道理非常相似,规范化很重要的目的之一就是让你厘清数据之间的关系,逆规范化的目的是在你厘清关系的数据模型基础上,做进一步的优化工作。这样先规范化再逆规范化,就需要建模工程师知其然并知其所以然,大大减少犯错的风险。
第五, 不可缺少约束的定义,比如主键,比如外键,比如特殊属性的范围定义等。
第六, 强烈建议使用CASE工具做逻辑建模,常见的CASE工具有CA公司的ERWIN,SAP公司的PowerDesigner,IBM的IDA,Oracle的SQL Developer Modeler,后面我会用单独的课程单独讲解如何使用Power Designer。使用CASE工具可以帮你更规范化、智能化的建模,并能很好的融入到整个系统工程中去。
第七, 多对多的关系需要在这一层解决,通常是创建Association Table的模式。

第八, 从系统工程管理的角度来讲,你需要一个和你同等级或者略高等级的同事(或小组)帮助定期评审你的模型,以确保模型的质量。
第九, 在逻辑建模阶段,如果你有外部数据或者其他系统作为数据源,你需要去验证上游数据的质量,确认可信赖数据源,同时关键属性不可想当然的假设,需要实际检验去验证。
第十, 建模时,可以参考成熟的模式,关于各类模式我后面会有单独的课程
十一, 在草创模型,将所有实体属性一一罗列之后,为了保证系统的通用性,需要做进一步的抽象化。比如,普通员工、合同工、经理、财务人员、总裁等等信息,可以统统抽象成EMPLOYEE实体。抽象化会为系统带来弹性,但过度的抽象化会为系统带来编程或者不规范等其他困难。抽象化需要视具体情况而定。
十二, 对于逻辑模型而言,需要对各个实体,重要的属性做结构化、详尽、准确的描述,这也就是说我反复强调的高质量建模。
十三, 在OLTP环境中,重要的关联关系需要建立主外键强关系,很多模型工程师为了编程的方便常常不建主外键。这会给数据质量带来很多隐患。在DW环境中,Referential Integrity的关系要求相对低一些,这个酌情而定。
十四, 需要和概念模型保持一致,如果发现有些地方不一致,需要确认是逻辑模型出问题了还是概念模型出问题了,再统一修正。

十五, 要注意模型的版本管理,和模型相关程序保持一致。开发,测试,生产分别做版本控制。
十六, 要非常非常注意细节,很多时候基础模型的一个小小的纰漏都会带来相关程序大量的修改。
十七, 在这个阶段,如果你需要从外部或者其他系统获取数据,则数据库专家需要深度介入。
十八, 由于使用CASE工具,造成很多物理模型均由逻辑模型自动生成,因此逻辑模型的工作量占整个数据建模非常大的比重。
十九, 不要忽视属性的长度和约束定义
二十, 不要忽视属性的默认值定义,这会减少很多数据隐患
廿一, 如果有必要,可以创建控制数据范围的域。

和概念模型一样,我们这里也谈一下逻辑模型交付物应该是什么样子?
1. 和概念模型简单明了的一页纸不同,逻辑模型应该是像一本书一样,它需要被用来生成未来的数据字典
2. 和概念模型只有实体无需属性不同,所有实体属性都需要添加进去,不应有遗漏
3. 实体之间的关系,是1:N, 0:N, 要清晰的描述
4. 如果实体数量足够多,需要使用术语表
5. 要严格遵循命名规则,有关命名规则我后面的课程会详细说明
6. 需要用CASE工具创建项目文件,后面的课程里我会讲如何使用CASE工具建模
7. 对各个实体均需要有清晰完整的描述
8. 对于关键属性都需要有清晰的描述,有关实体、属性的结构化描述,后面的课程会有详述

从严格的意义上讲,有了逻辑模型,我们还是不能够创建表。所以和建筑一样,建筑需要施工图,而我们需要物理模型。如左图所示,施工图需要细致到每个窗户的尺寸,距离地面的精确到毫米的距离;门的尺寸,精确到毫米的宽高,等等。物理模型也如是一样,首先需要选择数据库,需要增加数据类型等信息,以能够生成DDL为最终目标。而由于我们前面提到的,建议使用CASE工具作为建模的工具,而CASE工具具有将逻辑模型自动转化成物理模型自动转化的功能,为了减少模型维护工作,并且保持两个版本一致,我们几乎很少在物理模型上做太多处理,都是采用逻辑模型自动生成。
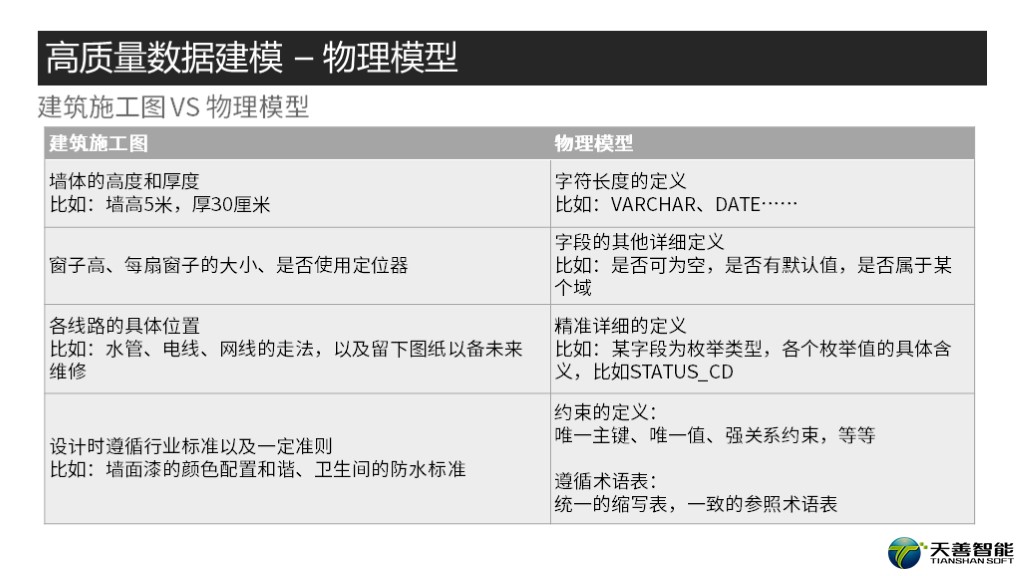
如建筑施工图需要详细到墙体的高度和厚度一样,物理模型需要精确到字段的类型和长度。此外,除数据类型之外,还有前面逻辑模型中提到过的默认值、是否为空之类的设置。同样物理模型的各个表、字段的信息描述也非常重要,不过由于我们使用CASE工具,这些信息如果在逻辑层已经定义完备,在自动生成的时候会自动添加到物理模型层。

在物理层需要注意的是,首先我们只维护逻辑层一个主版本,物理层采用自动生成并做极少量微调的模式进行管理。此外,如果表超过100个,建议使用术语表将字段名称自动转换,这样会保证整个模型的术语以及缩写保持一致。同时,物理层和逻辑层不同的是,这一层有一些特定的信息需要添加,比如表空间,索引,视图,物化视图等等,而这些都需要用做命名规则的标准化定义,尽可能由系统自动生成。
此外,由于本层即与DBA工作息息相关,因此DBA需要深度介入,很多时候物理层最终的维护者都是DBA。由于使用CASE工具的原因,所有模型相关的逆规范化工作均在逻辑层完成,强烈建议DDL由物理模型自动生成,并且严格做好版本管理控制

尤其开发/测试/生产环境的不同版本的管理。物理层需要做大量的模型优化工作,比如创建索引,分区等与性能息息相关的事情。在做物理层模型时,建议对数据规模进行估算,同时考虑数据归档问题。此外,还有非常重要的一点,未来选择的数据库产品与性能息息相关,因此要全面评估数据库产品的优点缺点以及限制,在设计时尽可能规避数据库产品的缺点。

物理模型交付品的特点包括:基础库表结构自动生成,后续手动调整。最终产出物与未来要使用的数据库类型息息相关,生成数据字典并发布,同时建议两套数据字典,物理模型和逻辑模型相对照。可以直接生成DDL。此处需要注意,模型中对表以及字段的注释,在DDL中生成出来。

以上就是概念模型到逻辑模型再到物理模型的流程。那么什么样的模型算是高质量数据模型呢?
首先,对真实世界的抽象和表达要正确并且完整;
另外,需要使用标准化的建模语言,使数据模型能够清晰的表达设计的思想,让人容易理解并不产生歧义
数据模型的框架稳定并且灵活,能够一定程度上容纳未来的变化
根据需求的实际情况,不要随意的逆规范化,要尽可能的减少数据冗余
需要充分考虑潜在的性能问题,尤其要根据数据库产品的特点,避免使用数据库产品的短处。
要不仅仅站在当前项目的视角去构筑模型,需要从企业的全局视角出发,比如方便其他系统访问,可以很方便的外部数据接口,命名规则术语定义和企业标准保持一致,等等。
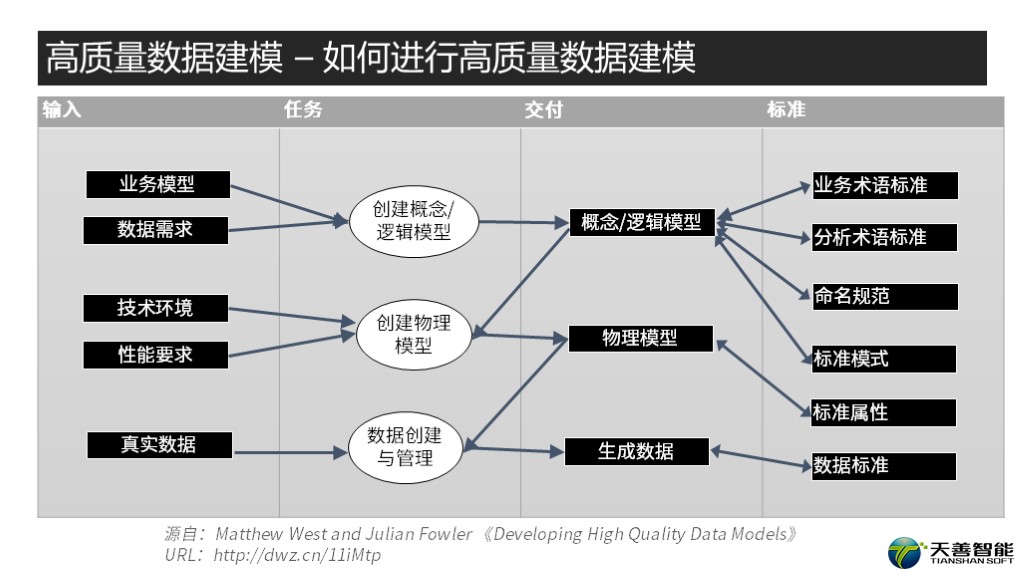
最后以这张图来清晰的描述高质量数据建模的整个过程。
从左上方的输入来看,由业务模型以及数据需求的输入,并且依照右上方的业务术语、分析术语、命名规则的规范,参照标准模式,经概念模型/逻辑模型建模操作,产生概念模型/逻辑模型;然后以概念模型/逻辑模型作为输入,同时结合技术环境和性能要求,经过物理模型的建模操作生成物理模型,然后将物理模型生成DDL并在数据库中建表,再将真实数据导入至系统中,而对于需要创建数据标准的相关信息,再做数据标准化操作。
至此,高质量建模的概述就为大家介绍到这里,经过本章的学习,你应该了解了高质量数据建模的重大意义,并且了解了数据建模在不同阶段的工作以及高质量建模的基本流程。本课是学习未来数据建模课程的基础,如果你希望进一步深入学习,请关注后面陆续推出的课程。



