作者:废才大叔
个人公众号: 废才数据挖掘
为了让更多小伙伴了解申请评分卡建模过程,小编利用某工业数据,做了一个简略版基于Python数据分析。该评分卡制作比较粗略,有部分步骤并不是严格按照工业级别评分卡流程来制作,本文仅仅为大家做一个评分卡流程梳理。
定义Y是需要根据业务要求,查看账龄表与滚动率定义,这里仅仅是作为一个分享,小编把逾期天数大于等于30天设定为1 ,为避免模型干扰以及更准确预测去除0-30客户,0天定义为0
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib
from sklearn.model_selection import GridSearchCV
import lightgbm as lgb
from sklearn.cross_validation import train_test_split,cross_val_score
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score,accuracy_score
from sklearn.model_selection import StratifiedKFold,KFold,StratifiedShuffleSplit
from sklearn.tree import _tree
from sklearn import tree
import warningsmatplotlib.use('qt4agg')#指定默认字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'#解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
pd.set_option('display.max_rows', 100)
pd.set_option('display.max_columns', 10000)
%matplotlib inline
warnings.filterwarnings("ignore")
def readfile(is_df): if is_df: df=pd.read_csv("D:/mydata/md5data.csv") return df
df=readfile(is_df=True)# 读取数据集

df.info()


可以看见df文件有20万+数据,42个变量,其中6个变量为float,7个为int,29个为object。
def value_count(df): name=df.columns lenth=[] names=[] for i in name: lenth.append(len(df[i].value_counts())) names.append(i) lenth=pd.DataFrame(lenth) names=pd.DataFrame(names) valuecounts=pd.concat([names,lenth],axis=1) valuecounts.columns=["name","vary_num"] return valuecounts
value_count(df)##查看每一种变量分类
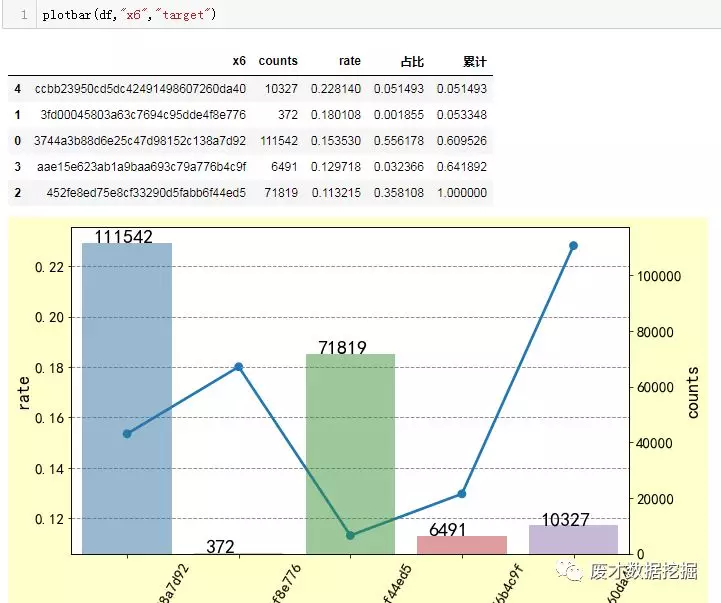
def plotbar(df,var,target): a=df.groupby([var])[target].mean().reset_index() b=df.groupby([var])[target].count().reset_index() b=b.merge(a,on=var,how="left").rename(columns={target+"_x":"counts",target+"_y":"rate"}) summary=b summary=summary.sort_index(by="rate",ascending=False) summary["占比"]=summary["counts"]/summary["counts"].sum() summary["累计"]=summary["占比"].cumsum()# summary=summary.sort_values(by="rate") name=str(b[var].tolist()) ticks=range(len(b)) y=b["counts"] #y1=aa["target"] fig = plt.figure(figsize=(10,6) ,facecolor='#ffffcc',edgecolor='#ffffcc')#图片大小 plt.grid(axis='y',color='#8f8f8f',linestyle='--', linewidth=1 ) plt.xticks(rotation=60,fontsize=15) plt.xlabel('xlabel', fontsize=30) plt.yticks(fontsize=15) ax1 = fig.add_subplot(111)#添加第一副图 ax2 = ax1.twinx()#共享x轴,这句很关键! plt.yticks(fontsize=15) plt.ylabel('ylabel', fontsize=30) sns.pointplot(b[var],b["rate"],marker="o",ax=ax1) sns.barplot(b[var],b["counts"],ax=ax2,alpha=0.5) for a,b in zip(ticks,y): plt.text(a-0.3,b ,str(b),fontsize=20) ax1.set_ylabel('rate', size=18) ax2.set_ylabel('counts', size=18) return summary
plotbar 函数是我自己定义的,可以对分组比较少的特征变量做一个简单的数据分析统计。以“x6”变量为例,简单看下“marriage”数据分布情况,其他变量分布我就不在这里演示了:
对时间做变量衍生:风险其实跟时间有一定周期性关系,所以可以根据时间维度,对切分出年月日季度等等维度,小编在这里只做了年月日小时的切分

检查缺失值
def cheackNA(df): na=df.isnull().sum()/df.shape[0]*100 na=pd.DataFrame(na).reset_index() na.columns=["name","missing_rate"] NA_Name=na[na["missing_rate"]>0]["name"].tolist() return NA_Name

缺失值填充方式有很多,比较常规的就是均值,众数,中位数,特定值填充,具体填充方式需要根据不同数据,不同业务场景进行分析,小编在这里为了演示方便,直接把缺失值按照—1填充
df=df.fillna(-1)
树模型算法,是不需要做数据分箱处理,但是,小编在这里是用的logit算法,对异常值比较敏感,而且传统评分卡需要把数据做WOE编码。
针对数据分箱的方式有很多,如无监督的等频分箱,等宽分箱,有监督的卡方分箱,决策树分箱等方式,一般来说,有监督分箱效果优于无监督分箱,小编在这里采用的是决策树分箱,分箱代码比较多,小编就不在这里演示了
对连续变量分箱:


这样就对连续变量分箱完成,分箱要求一般是需要呈单调性,且最小分箱数目占比要达到5%,小编在这里没有做单调性处理,遇见不单调的分箱,需要按照上下合并,直到单调为止,可能有人会问,为什么评分卡会强调单调性,最主要的原因是可解释性,如风险随着贷款金额增加而增大,
针对字符型变量或者说是类别型变量,分组特别多的,可以做删除处理,但是小编不建议这么做,一般的方法可对占比极小的分组单独合并为一组。
连续型变量分组后即可对 数据做WOE编码转换


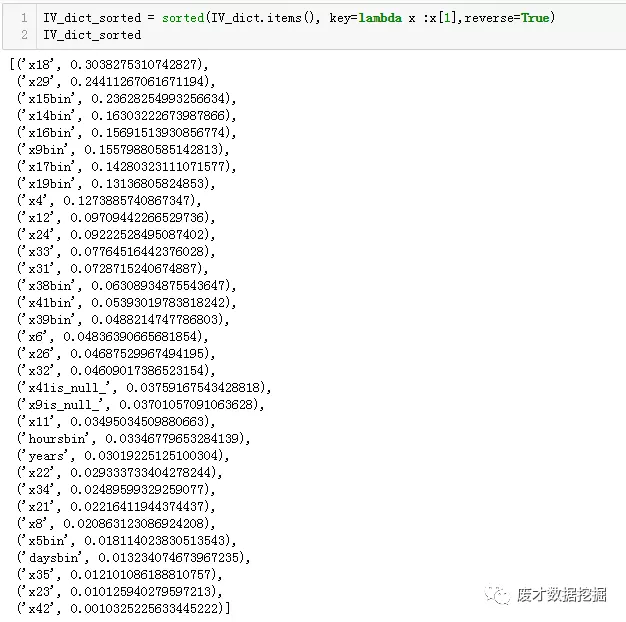
利用IV做特征选择,选择IV>0.02

对特征变量做相关性检测
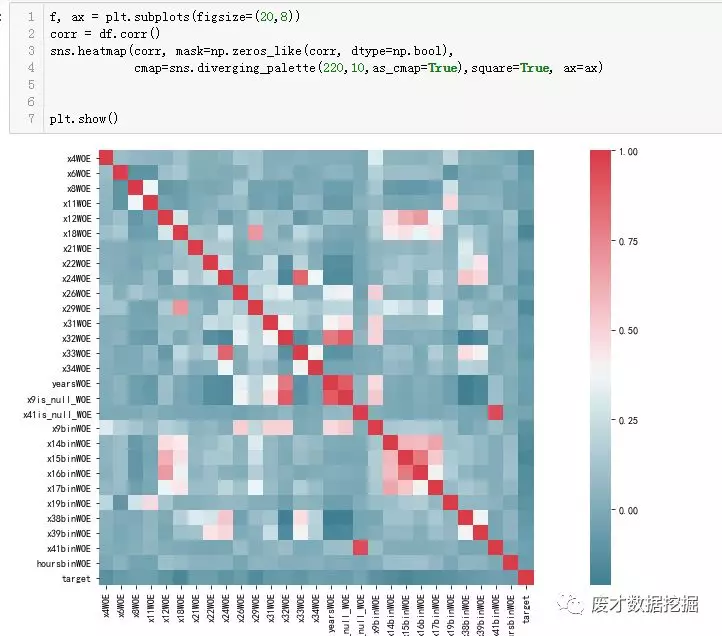
在变量比较多的情况下,可以对相关性要求苛刻一些,比如删除性关系绝对值大于0.7以上的变量,宽松一点可以到0.75
VIF方差膨胀因子检测


变量最大VIF值为2.6,不存在严重共线性
数据切分

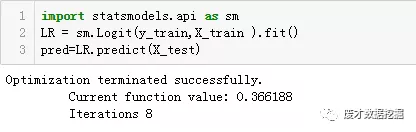
logit 迭代8次即完成数据预测

train与test ks依次为0.346,0.340,auc为0.734,0.732整个模型效果良好
ROC曲线:
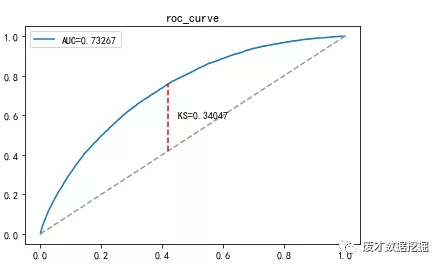
KS曲线:
拼接pred与test数据集
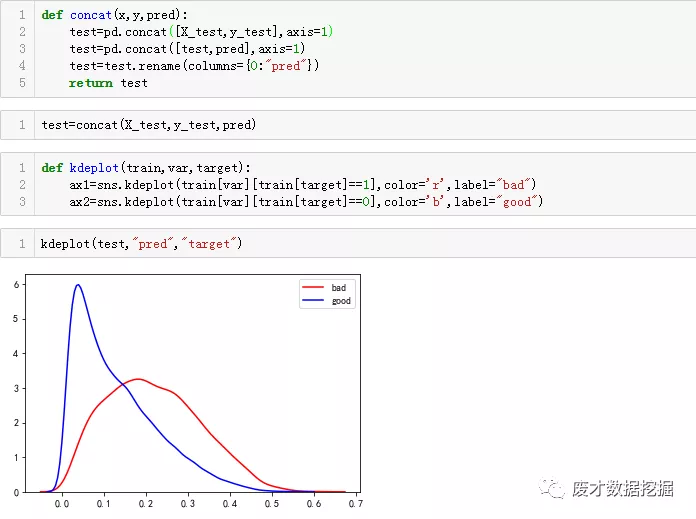
传统机器学习,到这里已经结束了,因为本文是做评分卡,所以需要把概率转换为分数
分数转换
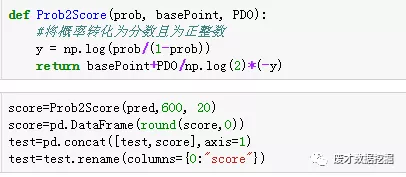
小编把基础分设置为600,pdo设置为20,表示的是每20分,风险增加1倍
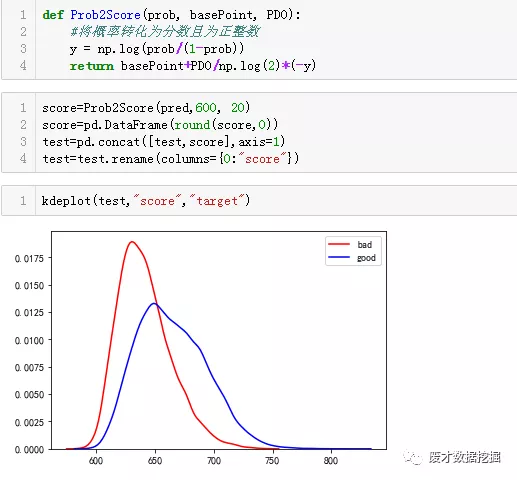
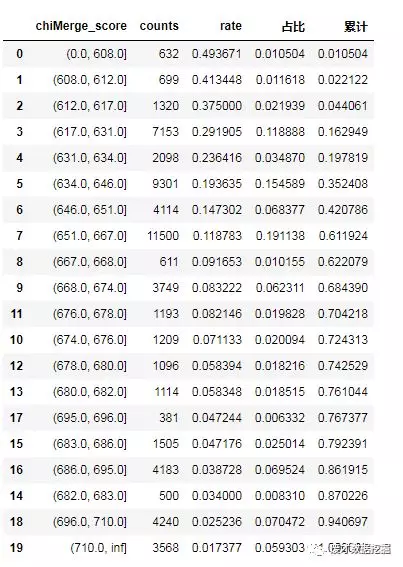
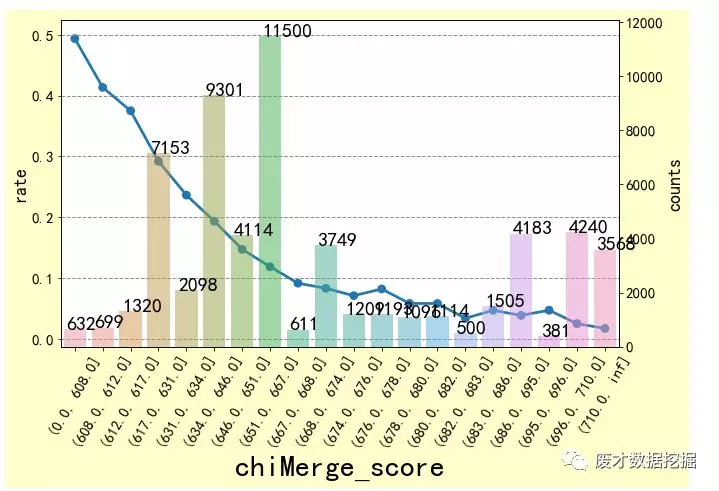
最后是对分数分组,分别计算每一个区间的badrate,小编是把分数划分为20份
好了,一个评分卡制作流程,就给大家分享到这里,如果各位对小编今天的文章比较满意,请手动关注。

Python的爱好者社区历史文章大合集:
2018年Python爱好者社区历史文章合集(作者篇)
2018年Python爱好者社区历史文章合集(类型篇)
福利:文末扫码关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“ 课程 ”即可获取:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python的入门免费视频课程!
小编的Python的快速上手matplotlib可视化库!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告扩展制作免费学习视频。
玩转大数据分析!Spark2.X + Python精华实战课程免费学习视频。

