
作者: wltongxue
博客:https://wltongxue.github.io/
本次学习我们将使用“什么是数据挖掘”中的挖掘过程:根据实际问题定义挖掘目标、取什么样的原始数据、对原始数据的探索分析、如何对数据进行处理、建立合适的模型完成目标、评估模型完成的好不好。
问题背景:实际生活中,有很多人可能会偷别人的电用,或者计量电量的设备坏了,造成无法根据实际用电情况计价,可能导致用户多交或少交了钱。我们可以使用自动化设备实现对用户用电负荷等数据进行采集,通过从这个数据中找到异常的情况。
一、挖掘目标
1、归纳出窃漏电用户的关键特征,构建窃漏电用户的识别模型
2、利用实时监测数据,调用窃漏电用户识别模型实现实时判断是否是窃漏电用户。
根据目标可以知道这类问题属于分类预测问题,根据数据预测这个用户属于哪一类用户,到底是正常用户,还是偷电用户?所以我们后面会考虑用分类和预测的算法模型进行建模。
二、数据抽取:
1、从营销系统抽取用户信息
2、从计量自动化系统采集电量、负荷等
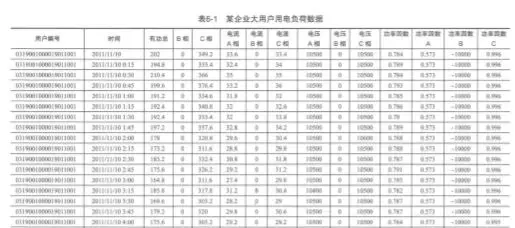
如下图,你可以看到能实际采集到的数据如下
三、数据探索:分布分析+周期性分析
探索与预测无关的数据,缩小数据集范围,达到精准预测
1、分布分析
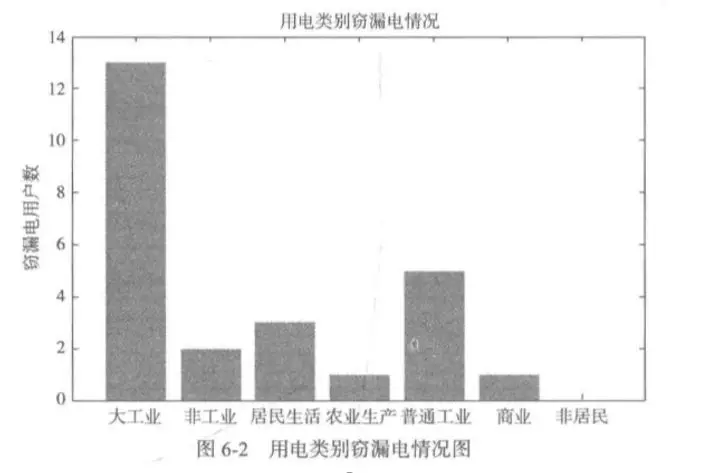
统计5年内所有窃漏用户进行分布分析,统计出各个用电类别的窃漏电用户分布情况,如下图所示,可以发现非居民类别不存在窃漏电情况,故在接下来的分析中不考虑非居民类别的用电数据
2、周期性分析
随机抽取一个正常用电用户和一个窃漏电用户,周期性对电量进行探索。
(1)正常用电,如下图所示,总体来说用电量比较平稳,没有太大的波动。
 (2)窃漏电用户用电量出现明显下降的趋势,如下图所示。
(2)窃漏电用户用电量出现明显下降的趋势,如下图所示。
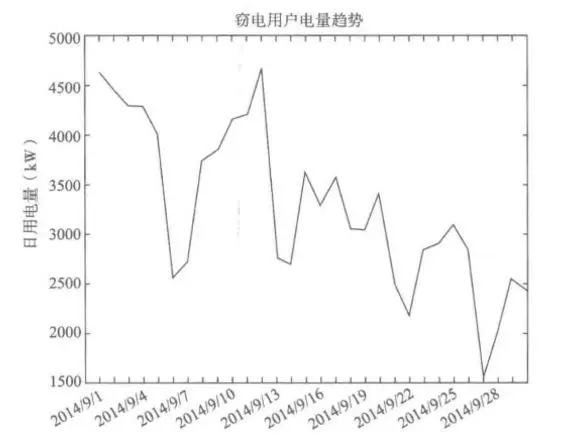
分析结论:窃漏电的过程就是用电量持续下降的过程。
四、数据预处理
数据本身的样子可能并不适合我们处理,比如跟预测结论没有关系的数据,我们可以过滤掉。比如存在一些缺失值,样本很多的情况下我们就大方的删了,但样本很少的时候,我们就需要把它补上。比如好多个数据之间有明显的关系,我们可以把他们合并为一个数据作为特征明显指标。总之,我们对于数据的预处理目的就是:用尽可能少的数据探索出尽可能精准的结果。
1、缺失值可以删除也可以插补,插补的方法很多,我们这里使用“拉格朗日插值法”进行数据的补充,(该数学推导请看这里):https://wltongxue.github.io/%E6%8B%89%E6%A0%BC%E6%9C%97%E6%97%A5%E6%8F%92%E5%80%BC%E6%B3%95/
我们这里调用python库中已经实现的拉格朗日函数对样本数据进行插值,代码如下:
1234567891011121314151617181920212223242526#-*-coding:utf-8 -*-#拉格朗日插值代码import pandas as pd #导入数据分析库from scipy.interpolate import lagrange #导入拉格朗日函数inputfile = '../data/missing_data.xls'#输入数据路径,需要使用ecel格式outputfile= '../tmp/missing_data_processed.xls' #输出数据路径,需要使用Excel格式data=pd.read_excel(inputfile,header=None) #读入数据#自定义列向量插值函数#s为列向量(表中某个字段的所有数据),n为被插值的位置,k为取前后的数据个数,默认为5#取总共11个数据构建拉格朗日函数def ployinterp_column(s,n,k=5): y=s[list(range(n-k,n)) + list(range(n+1,n+1+k))] y=y[y.notnull()]#剔除空值 return lagrange(y.index,list(y))(n) #插值并返回插值结果#逐个元素判断是否需要插值for i in data.columns: for j in range(len(data)): if(data[i].isnull())[j]:#如果为空即插值 data[i][j]=ployinterp_column(data[i],j)#输出结果data.to_excel(outputfile,header=None,index=False)
如下图,拉格朗日插补法的效果如下:
 我们就使用这样的方法处理所有的数据,这里就不再赘述,紧接着我们从大量数据中抽取291个专家样本数据(使用这291个数据进行模型构建)。从原始数据开始到现在为止,其实我们已经做了三件事情了:
我们就使用这样的方法处理所有的数据,这里就不再赘述,紧接着我们从大量数据中抽取291个专家样本数据(使用这291个数据进行模型构建)。从原始数据开始到现在为止,其实我们已经做了三件事情了:
1、过滤掉无关的属性,例如用户编号。
2、缺失值处理。
3、从大量数据中选取291个样本数据。
现在,我们要对291个样本数据进行降维处理(也就是将相关属性合并为一个属性)
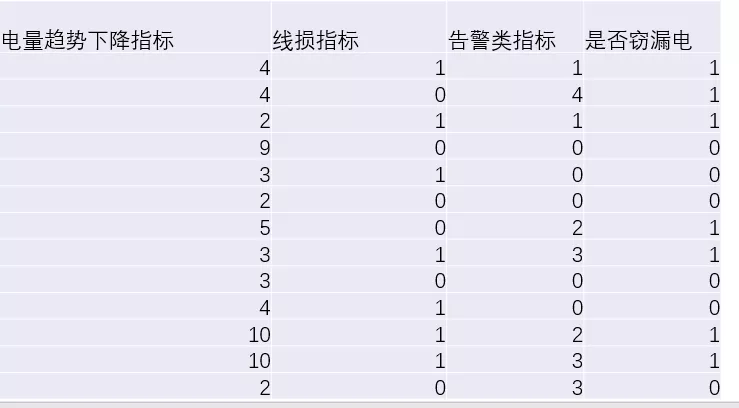
我们构建三个指标(新属性,由旧属性变换而来):
(1)电量趋势下降指标。对每天的前后5天(总共11天)计算电量的下降趋势(即斜率)
(2)线损指标。若第L天的线路供电为S,线路上各个用户用电总量为W,则线损率T=(S-W)/S * 100%
(3)告警类指标。计算终端报警的次数总和。
这里只展示最终数据,数据变换的过程根据实际意义可以进行修改。最终数据如下,最后一列给定结果是为了模型的学习和模型的评估,最终是为了这个模型可以预测其他的不可知漏电行为。
五、模型构建
我们已经完成的数据的处理,现在的数据可以用来训练和测试模型。
重点来了,由于我们是分类问题,所以我们从分类模型中选择模型。这里实际上是一个二分类问题,结果只有0或者1,此时我们就不会选择回归分析(因为回归分析是分析连续性结果);并且我们的属性并不多,所以我们会更倾向选择决策树算法或者神经网络算法。这里在决策树算法中选择CART算法(算法详解请看这里“https://wltongxue.github.io/CART/”),在神经网络算法中选择LM算法(算法详解请看这里:https://wltongxue.github.io/LM-BP/)。实际上其他一些算法也能应用于该问题,感兴趣的读者也可以尝试效果,我们在这里只选择两个常见的进行比较。
我们的整体过程如下图,
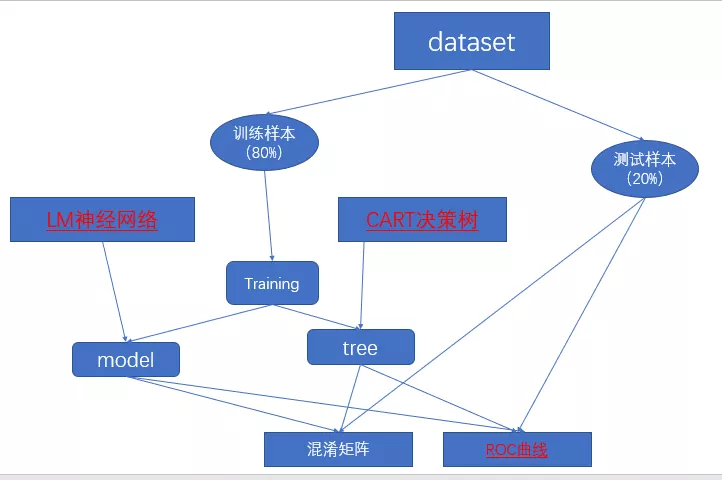
这里稍微简单的说一下机器学习的过程,首先切分数据集为训练集和测试集(也可以是独立的两个数据集),然后我们选择合适的算法,每种算法模型都可以有多种参数,但是确定什么样的参数才能解决我们当前的问题,这就需要训练集一个一个的带入到算法模型里然后一步一步的调整到合适的参数获得模型。最后我们需要把测试集代入到训练好的模型里,评估一下这个模型是不是在任何该问题的数据下都能够准确的得到预测结果。评估分类模型的指标也有很多(参考数据挖掘实战讲解系列(1)——什么是数据挖掘),本章我们选择ROC曲线(什么是ROC曲线:https://wltongxue.github.io/ROC/)。
按照上图的步骤我们进行代码的编写:
1、数据划分代码:
导入291个样本,将数据分为训练集和测试集
1234567891011import pandas as pd #导入数据分析库from random import shuffle #导入随机函数shuffle,用来打乱数据datafile='../data/model.xls' #数据名data=pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签data=data.as_matrix() #将表格转换为矩阵shuffle(data) #随机打乱数据p = 0.8 #设置训练数据比例train=data[:int(len(data)*p),:]#前80%为训练集test=data[int(len(data)*p):,:]#后20%为测试集
2、LM神经网络算法:
这里用到了python的神经网络库keras,构建三层网络模型,训练模型并且保存模型。这里的ROC曲线代码在评估阶段提供
1234567891011121314151617181920212223242526272829#########构建LM神经网络模型##########from keras.models import Sequential #导入神经网络初始化函数from keras.layers.core import Dense,Activation #导入神经网络层函数、激活函数from keras.models import load_modelnetfile='../tmp/net.model' #构建的神经网络模型存储路径net = Sequential() #简历神经网络net.add(Dense(input_dim=3,output_dim=10)) #添加输入层(3节点)到隐藏层(10节点)的连接net.add(Activation('relu')) #隐藏层使用relu激活函数net.add(Dense(input_dim=10,output_dim=1)) #添加隐藏层(10节点)到输出层(1节点)的连接net.add(Activation("sigmoid"))#输出层使用sigmoid激活函数#导入训练好的model_weights#net.load_weights(netfile)#编译模型,使用adam方法求解net.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])#:3标识前3列(因为第四列是标签)net.fit(train[:,:3],train[:,3],nb_epoch=1000,batch_size=1)#训练模型,循环1000次net.save_weights(netfile) #保存模型predict_result = net.predict_classes(train[:,:3]).reshape(len(train))#预测结果变形'''这里要提醒的是,keras用predict给出预测概率,predict_class才是给出预测类别, 而且两者的预测结果都是n x 1维数组,而不是通常的1 下n'''from cm_plot import * #导入自行编写的混淆矩阵可视化函数()cm_plot(train[:,3],predict_result).show() #显示混淆矩阵可视化结果#显示ROC曲线predict_result_test=net.predict(test[:,:3]).reshape(len(test)) #预测结果变形roc_plot(test[:,3],predict_result_test ,'ROC of LM')
3、CART决策树
这里使用python的sklearn库
12345678910111213141516#构建CART决策树模型from sklearn.tree import DecisionTreeClassifier #导入决策树模型treefile='../tmp/tree.pk1'#模型输出名字tree = DecisionTreeClassifier() #建立决策树模型tree.fit(train[:,:3],train[:,3]) #训练#保存模型from sklearn.externals import joblibjoblib.dump(tree,treefile)from cm_plot import * #导入画混淆矩阵和ROC曲线的模块(自定义模块)cm_plot(train[:,3],tree.predict(train[:,:3])).show() #显示混淆矩阵#注意到Scikit-Learn使用predict方法直接给出预测结果#显示roc曲线roc_plot(test[:,3],tree.predict_proba(test[:,:3])[:,1],'ROC of CART')
4、ROC曲线
123456789101112131415161718192021222324252627282930313233import matplotlib.pyplot as plt #包含画图工具'''画混淆矩阵图'''def cm_plot(y, yp): from sklearn.metrics import confusion_matrix #导入混淆矩阵函数 cm = confusion_matrix(y, yp) #混淆矩阵 plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。 plt.colorbar() #颜色标签 for x in range(len(cm)): #数据标签 for y in range(len(cm)): plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') #坐标轴标签 plt.xlabel('Predicted label') #坐标轴标签 return plt'''画ROC曲线图'''#绘制决策树模型的ROC曲线from sklearn.metrics import roc_curve #导入ROC曲线函数def roc_plot(x,xp,l): fpr,tpr,thresholds=roc_curve(x,xp, pos_label=1) plt.plot(fpr,tpr,linewidth=2,label=l) #做出ROC曲线 plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.ylim(0,1.05)#边界范围 plt.xlim(0,1.05)#边界范围 plt.legend(loc=4)#图列 plt.show() #显示作图结果 return plt
在这里补充一下,每一次随机分的训练集和测试集并不完全相同,代码运行一次,分一次数据集,就不一样一次,所以每一次的训练得出的模型并不是完全相同的,但我们希望比较两个算法的优缺点时,我们希望他们要用同一个训练集,同一个测试集,所以这里补充一下,把两个算法写在一起训练并且比较ROC曲线更有说服力。(ps:上面的训练集划分和两个算法的代码可以等同于如下:)
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859#coding=utf-8import sysreload(sys)sys.setdefaultencoding('ISO-8859-1')'''读取数据,设置数据'''import pandas as pd #导入数据分析库from random import shuffle #导入随机函数shuffle,用来打乱数据datafile='../data/model.xls' #数据名data=pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签data=data.as_matrix() #将表格转换为矩阵shuffle(data) #随机打乱数据p = 0.8 #设置训练数据比例train=data[:int(len(data)*p),:]#前80%为训练集test=data[int(len(data)*p):,:]#后20%为测试集#让LM和CART使用同一个数据分法进行比较'''LM预测'''#########构建LM神经网络模型##########from keras.models import Sequential #导入神经网络初始化函数from keras.layers.core import Dense,Activation #导入神经网络层函数、激活函数from keras.models import load_modelnetfile='../tmp/net.model' #构建的神经网络模型存储路径net = Sequential() #简历神经网络net.add(Dense(input_dim=3,output_dim=10)) #添加输入层(3节点)到隐藏层(10节点)的连接net.add(Activation('relu')) #隐藏层使用relu激活函数net.add(Dense(input_dim=10,output_dim=1)) #添加隐藏层(10节点)到输出层(1节点)的连接net.add(Activation("sigmoid"))#输出层使用sigmoid激活函数#编译模型,使用adam方法求解net.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])#:3标识前3列(因为第四列是标签)net.fit(train[:,:3],train[:,3],nb_epoch=1000,batch_size=1)#训练模型,循环1000次net.save_weights(netfile) #保存模型predict_result = net.predict_classes(train[:,:3]).reshape(len(train))#预测结果变形'''这里要提醒的是,keras用predict给出预测概率,predict_class才是给出预测类别, 而且两者的预测结果都是n x 1维数组,而不是通常的1 下n''''''CART预测'''#构建CART决策树模型from sklearn.tree import DecisionTreeClassifier #导入决策树模型tree = DecisionTreeClassifier() #建立决策树模型tree.fit(train[:,:3],train[:,3]) #训练'''画混淆矩阵和ROC曲线'''from cm_plot import * #导入自行编写的混淆矩阵可视化函数()cm_plot(train[:,3],predict_result).show() #显示混淆矩阵可视化结果cm_plot(train[:,3],tree.predict(train[:,:3])).show() #显示混淆矩阵#显示ROC曲线predict_result_test=net.predict(test[:,:3]).reshape(len(test)) #预测结果变形roc_plot(test[:,3],predict_result_test ,'ROC of LM')roc_plot(test[:,3],tree.predict_proba(test[:,:3])[:,1],'ROC of CART')
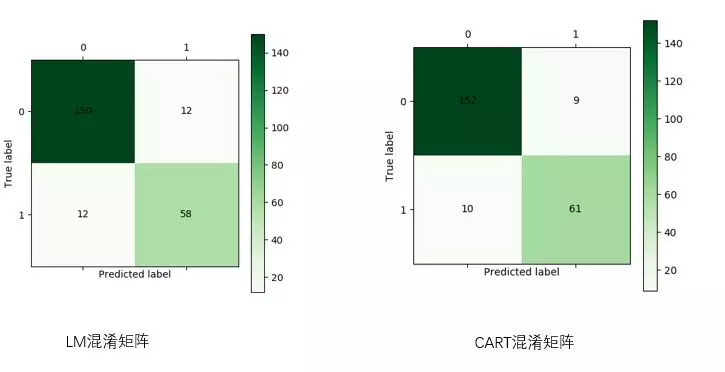
六、模型评价
根据上述两个算法同时比较的代码,可得到如下ROC曲线。
Python的爱好者社区历史文章大合集:
 福利:文末扫码关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“ 课程 ”即可获取:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python的入门免费视频课程!
小编的Python的快速上手matplotlib可视化库!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告扩展制作免费学习视频。
玩转大数据分析!Spark2.X + Python精华实战课程免费学习视频。
