作者:我爱小詹
公众号:小詹学Python
这是第 3 篇读者投稿文章 ,欢迎亲爱的读者们踊跃投稿哦 。
不会英语的程序员不是好程序员 ?小詹不敢乱立 flag ,但是我知道的是程序员就喜欢自己动手干些实事 ,比如今天教大家自己动手做个有意思的项目——从历年四级英语真题中获取词频最高的 5000 个词汇 ,并进行翻译 !综合用到了爬虫 、数据分析等知识 ,亲爱的读者们不来试试吗 ?
程序介绍
这是一个单词频率统计程序 ,基于python3 ,我将往年真题按照词频排序得到了四级词库 :总结出了 5000 个出现频率极高的单词 。
在结合到大量的往年 cet-4 真题库的情况下
工作流程
settings.py 配置查询文档
work.py 自动分析数据保存至voca.db数据库文件
translate.py 自动打开数据库调用api翻译单词并保存到数据库里
db2csv.py 将数据库文件转换成csv表格文件
python work.py
python translate.py
python db2csv.py
具体实现
数据 (docx 复杂的文档结构不好用,可以在word里面以txt方式保存)
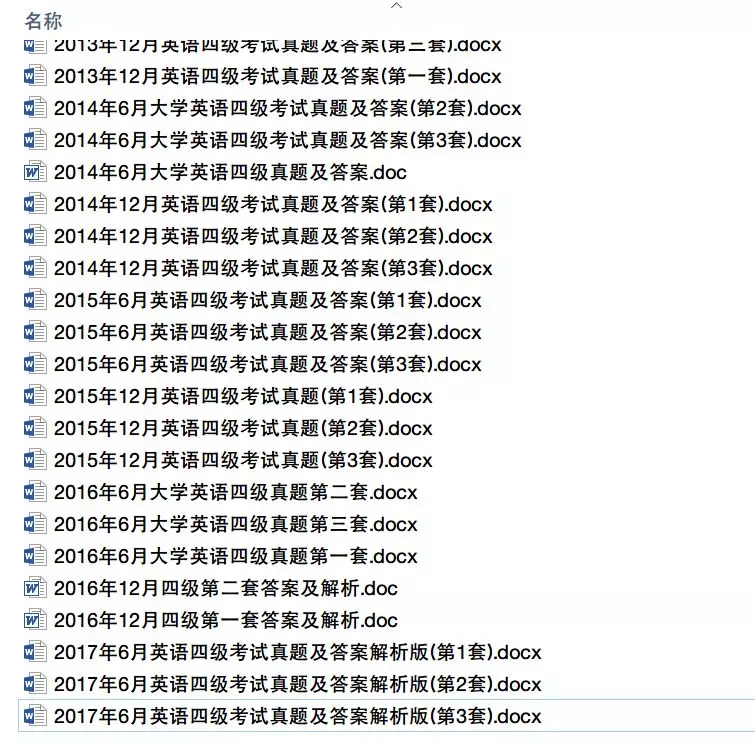
读入文件拿到所有单词
def _open_file(self,filename):#打开文件,返回所有单词list
with open(filename,'r',encoding='utf-8')as f:
raw_words = f.read()
low_words = raw_words.lower()
words = re.findall('[a-z]+',low_words) #正则re找到所有单词
return words
剔除 常用单词(is am are do……)
def _filter_words(self,raw_words,count=NUMBERS):#载入未处理的所有单词列表 和 默认count值
new_words = []
for word in raw_words:#找出非exclude 和 长度大于1 的单词 -> new_words
if word not in exclude_list and len(word) > 1:
new_words.append(word)
pass
计数
from collections import Counter #计数器
pass
c = Counter(words) #list new_words
return c.most_common(5000) #拿到出现次数最多的5000单词,返回从大到小的排序list[(and,1),....]
数据库初始化 peewee模块
from peewee import *
db = SqliteDatabase('voca.db')
class NewWord(Model):
# 单词名
name = CharField()
# 解释
explanation = TextField(default='')
# 词频
frequency = IntegerField(default=0)
# 音标
phonogram = CharField(default='')
class Meta:
database = db
加入单词到数据库
def insert_data(self,words_times):
# 向数据库内插入数据
for word,fre in words_times:
word_ins = NewWord.create(name = word , frequency = fre) #直接调用create
book.is_analyzed = True
book.save()
翻译
#iciba翻译函数
def trans(self, word):
url = 'http://www.iciba.com/index.php?a=getWordMean&c=search&word=' + word
try:
req = requests.get(url)
req.raise_for_status()
info = req.json()
data = info['baesInfo']['symbols'][0]
assert info['baesInfo']['symbols'][0]
# 去除没有音标的单词
assert data['ph_am'] and data['ph_en']
# 去除没有词性的单词
assert data['parts'][0]['part']
except:
return ('none','none')
ph_en = '英 [' + data['ph_en'] + ']'
ph_am = '美 [' + data['ph_am'] + ']'
ex = ''
for part in data['parts']:
ex += part['part'] + ';'.join(part['means']) + ';'
return ph_en+ph_am, ex
#调用翻译函数,保存中文到数据库
for i in NewWord.select():
i.explanation = str(t.trans(i.name)[1])
i.save()
提取所有单词到csv
import csv
#提取所有数据库内容生成迭代对象 yield ~ 好好看看如何使用
def extract()
pass
for word in NewWord.select():
for i in [word.name, word.explanation, word.frequency]:
datas.append(i)
yield datas
#保存函数
def save(data):
with open('words.csv', 'a+', errors='ignore', newline='')as f:
csv_writer = csv.writer(f)
csv_writer.writerow(data)
#主程序
datas = extract() #yeild 迭代对象
while True:
try:
data = next(datas)
except:
break
save(data)
收获成果啦
翻译过程

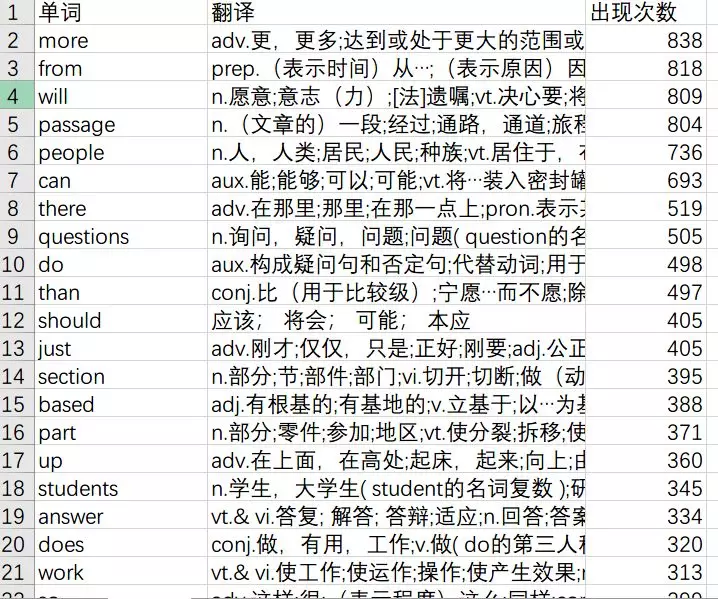
出现次数最多的简单词
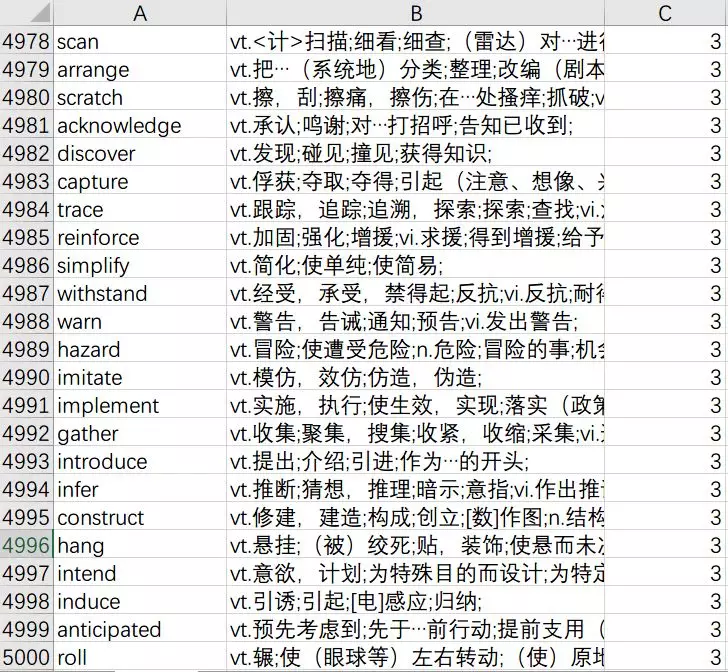
出现次数较少,值得一背的词
上述完整代码和获取到的统计结果(5000个高频词),公号后台回复关键词 “四级” 即可获取 。最后 ,小詹只想说 so 因吹斯听~

Python的爱好者社区历史文章大合集:
2018年Python爱好者社区历史文章合集(作者篇)
2018年Python爱好者社区历史文章合集(类型篇)
 福利:文末扫码关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“ 课程 ”即可获取:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python的入门免费视频课程!
小编的Python的快速上手matplotlib可视化库!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告扩展制作免费学习视频。
玩转大数据分析!Spark2.X + Python精华实战课程免费学习视频。

