作者: CuteHand
金融学博士,专注于Python在金融领域的应用
微信公众号:Python金融量化(ID: tkfy920)
一切事物的开头总是困难这句话,在任何一种科学上都是适用的。——马克思

前言
“手把手教你”系列将为Python初学者一一介绍Python在量化金融中运用最广泛的几个库(Library): NumPy(数组、线性代数)、SciPy(统计)、pandas(时间序列、数据分析)、matplotlib(可视化分析)。建议安装Anaconda软件(自带上述常见库),并使用Jupyter Notebook交互学习。
1、使用“import”命令导入numpy库
import numpy as np
2、生成数组,使用命令np.array(),括号里的数据类型为系列(list)
a=[1,2,3,4,5,6,7,8] #a是系列(list)
b=np.array(a) #b是数组
print(a,b) #打印a和b
print(type(a),type(b)) #查看a和b的类型
[1, 2, 3, 4, 5, 6, 7, 8] [1 2 3 4 5 6 7 8]
<class 'list'> <class 'numpy.ndarray'>
对数组进行操作:
b=b.reshape(2,4) #改变数组的维度
print(b) #从原来的1x8变成2x4 (两行四列)
#元素访问
print("取第1行第2列元素:",b[1][2]) #注意是从0行0列开始数!!!
[[1 2 3 4]
[5 6 7 8]]
取第1行第2列元素: 7
变成三维数组:
c=b.reshape(2,2,2)
print(c)
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
特殊的数组有特别定制的命令生成,如零和1矩阵:
d=(3,4)
print(np.zeros(d)) #零矩阵
print(np.ones(d))
#默认生成的类型是浮点型,可以通过指定类型改为整型
print(np.ones(d,dtype=int))
[[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]]
[[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]]
[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]
3、常用函数
arange指定范围和数值间的间隔生成 array,注意范围包左不包右
注意:系统自带的range生成的是tupe,要产生list需要使用循环取出元素
#使用range产生list
L=[i for i in a]
print(L)
[1, 2, 3, 4, 5, 6, 7, 8]
b=np.arange(10) #注意包含0,不包含10
c=np.arange(0,10,2) #2表示间隔
d=np.arange(1,10,3) #3表示间隔
print(b,c,d)
[0 1 2 3 4 5 6 7 8 9] [0 2 4 6 8] [1 4 7]
金融分析常常需要产生随机数,Numpy的random函数派上用场。均匀分布:
a=np.random.rand(3,4) #创建指定为3行4列)的数组(范围在0至1之间)
b=np.random.uniform(0,100) #创建指定范围内的一个数
c=np.random.randint(0,100) #创建指定范围内的一个整数
print("创建指定为3行4列)的数组:\n",a) #\n 表示换行
print("创建指定范围内的一个数:%.2f" %b) #%.2f 表示结果保留2位小数
print("创建指定范围内的一个整数:",c)
创建指定为3行4列)的数组:
[[ 0.41381256 0.92295862 0.93350059 0.78374808]
[ 0.71077228 0.27084757 0.50303507 0.46643957]
[ 0.39789158 0.93730999 0.24616428 0.43307303]]
创建指定范围内的一个数:66.05
创建指定范围内的一个整数: 77
正态分布
给定均值/标准差/维度的正态分布np.random.normal(u, r, (x, y)) 数组的索引
#正态生成3行4列的二维数组
a= np.random.normal(1.5, 3, (3, 4)) #均值为1.5,标准差为3
print(a)
# 截取第1至2行的第2至3列(从第0行、0列算起算起)
b = a[1:3, 2:4]
print("截取第1至2行的第2至3列: \n",b)
[[-0.77790783 7.09340234 3.46848684 3.13337912]
[-1.98384413 4.14324286 3.98562892 3.58336292]
[-0.80908369 -0.23560019 -0.67037947 2.25007073]]
截取第1至2行的第2至3列:
[[ 3.98562892 3.58336292]
[-0.67037947 2.25007073]]
4、数组ndarray 运算
元素之间依次相加、减、乘、除;统计运算
a = np.array([1,2,3,4]) #1行4列
b = np.array(2) #只有一个元素
a - b,a+b
(array([-1, 0, 1, 2]), array([3, 4, 5, 6]))
python的次方使用**实现:
File "<ipython-input-12-d58dcb39be5e>", line 1
python的次方使用**实现:
^
SyntaxError: invalid character in identifier
a**2 #二次方,a里元素的平方
array([ 1, 4, 9, 16], dtype=int32)
np.sqrt(a) #开根号
array([ 1. , 1.41421356, 1.73205081, 2. ])
np.exp(a) #e 求方
array([ 2.71828183, 7.3890561 , 20.08553692, 54.59815003])
np.floor(10*np.random.random((2,2))) #向下取整
array([[ 1., 8.],
[ 6., 5.]])
a.resize(2,2) #变换结构
a
array([[1, 2],
[3, 4]])
统计运算:
需要知道二维数组的最大最小值怎么办?想计算全部元素的和、按行求和、按列求和怎么办?NumPy的ndarray类已经做好函数了
a=np.arange(20).reshape(4,5)
print("原数组a:\n",a)
print("a全部元素和: ", a.sum())
print("a的最大值: ", a.max())
print("a的最小值: ", a.min())
print("a每行的最大值: ", a.max(axis=1)) #axis=1代表行
print("a每列的最大值: ", a.min(axis=0)) #axis=0代表列
print("a每行元素的求和: ", a.sum(axis=1))
print("a每行元素的均值:",np.mean(a,axis=1))
print("a每行元素的标准差:",np.std(a,axis=1))
原数组a:
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
a全部元素和: 190
a的最大值: 19
a的最小值: 0
a每行的最大值: [ 4 9 14 19]
a每列的最大值: [0 1 2 3 4]
a每行元素的求和: [10 35 60 85]
a每行元素的均值: [ 2. 7. 12. 17.]
a每行元素的标准差: [ 1.41421356 1.41421356 1.41421356 1.41421356]
5、矩阵及其运算
A = np.array([[0,1], [1,2]]) #数组
B = np.array([[2,5],[3,4]]) #数组
print("对应元素相乘:\n",A*B)
print("矩阵点乘:\n",A.dot(B))
print("矩阵点乘:\n",np.dot(A,B)) #(M行, N列) * (N行, Z列) = (M行, Z列)
print("横向相加:\n",np.hstack((A,B)))
print("纵向相加:\n",np.vstack((A,B)))
对应元素相乘:
[[0 5]
[3 8]]
矩阵点乘:
[[ 3 4]
[ 8 13]]
矩阵点乘:
[[ 3 4]
[ 8 13]]
横向相加:
[[0 1 2 5]
[1 2 3 4]]
纵向相加:
[[0 1]
[1 2]
[2 5]
[3 4]]
数组可以通过asmatrix或者mat转换为矩阵,或者直接生成也可以
A=np.arange(6).reshape(2,3)
A=np.asmatrix(A) #将数组转化成矩阵
print (A)
B=np.matrix('1.0 2.0 3.0;4.0 5.0 6.0') #直接生成矩阵
print(B)
[[0 1 2]
[3 4 5]]
[[ 1. 2. 3.]
[ 4. 5. 6.]]
A*B.T #A和B已经是矩阵了,但A的列要与B的行相等才能相乘,对B进行转置(B.T)
matrix([[ 8., 17.],
[ 26., 62.]])
线性代数运算
矩阵求逆:
import numpy.linalg as nlg #线性代数函数
import numpy as np
a=np.random.rand(2,2)
a=np.mat(a)
print(a)
ia=nlg.inv(a)
print("a的逆:\n",ia)
[[ 0.05263888 0.6813566 ]
[ 0.81685383 0.02770063]]
a的逆:
[[-0.04990111 1.22742491]
[ 1.47151541 -0.09482594]]
求特征值和特征向量
a=np.array([2,4,3,9,1,4,3,4,2]).reshape(3,3)
eig_value,eig_vector=nlg.eig(a)
print("特征值:",eig_value)
print("特征向量:",eig_vector)
特征值: [ 10.48331477 -4.48331477 -1. ]
特征向量: [[-0.50772731 -0.36224208 -0.28571429]
[-0.69600716 0.85881392 -0.42857143]
[-0.50772731 -0.36224208 0.85714286]]
实例分析:假设股票收益率服从正态分布,使用numpy产生正态分布随机数,模拟股票收益率,并采用正态分布策略进行交易。
假设有2000只股票,一年股市共250个交易日。一年365天-全民法定节假日=365-每周双休日*52-节日放假日 (国庆3天+春节3天+劳动节、元旦、清明、端午、中秋共11天)=365-104-11=250日,产生2000x500的数组。
stocks = 2000 # 2000支股票
days = 500 # 两年大约500个交易日
# 生成服从正态分布:均值期望=0,标准差=1的序列
stock_day = np.random.standard_normal((stocks, days))
print(stock_day.shape) #打印数据组结构
# 打印出前五只股票,头五个交易日的涨跌幅情况
print(stock_day[0:5, :5])
(2000, 500)
[[-0.07551455 0.29357958 -0.30444034 1.92766721 -0.23077118]
[-0.10149728 -0.66709552 1.53380182 -0.27389357 -0.96988518]
[ 0.53005545 1.12241132 0.49236533 -0.67694298 0.67307296]
[-0.199584 0.47197832 -0.25854041 0.16278091 0.68747893]
[-0.74029997 0.25514721 -0.69150807 -1.9827364 -0.49419039]]
正态分布买入策略:
# 保留后250天的随机数据作为策略验证数据
keep_days = 250
# 统计前450, 切片切出0-250day,days = 500
stock_day_train = stock_day[:,0:days - keep_days]
# 打印出前250天跌幅最大的三支,总跌幅通过np.sum计算,np.sort对结果排序
print(np.sort(np.sum(stock_day_train, axis=1))[:3])
# 使用np.argsort针对股票跌幅进行排序,返回序号,即符合买入条件的股票序号
stock_lower = np.argsort(np.sum(stock_day_train, axis=1))[:3]
# 输出符合买入条件的股票序号
stock_lower
[-48.47837792 -47.2409051 -46.15811624]
array([1348, 1376, 1325], dtype=int64)
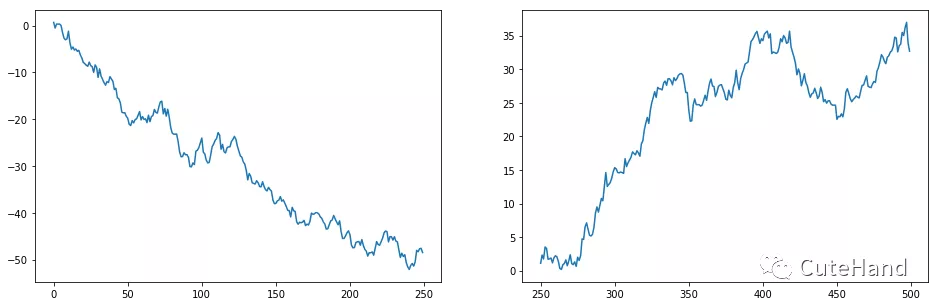
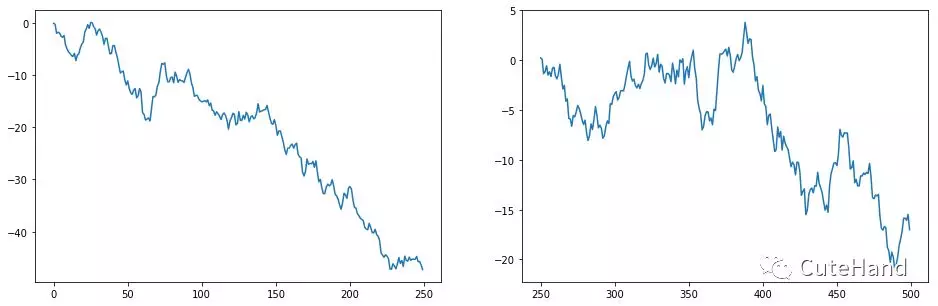
封装函数plot_buy_lower()可视化选中的前3只跌幅最大的股票前450走势以及从第454日买入后的走势
import matplotlib.pyplot as plt #引入画图库
%matplotlib inline
#python定义函数使用def 函数名:然后enter
def buy_lower(stock):
#设置一个一行两列的可视化图表
_, axs=plt.subplots(nrows=1,ncols=2,figsize=(16,5))
#绘制前450天的股票走势图,np.cumsum():序列连续求和
axs[0].plot(np.arange(0,days-keep_days),
stock_day_train[stock].cumsum())
#从第250天开始到500天的股票走势
buy=stock_day[stock][days-keep_days:days].cumsum()
#绘制从第450天到500天中股票的走势图
axs[1].plot(np.arange(days-keep_days,days),buy)
#返回从第450天开始到第500天计算盈亏的盈亏序列的最后一个值
return buy[-1]
#假设等权重地买入3只股票
profit=0 #盈亏比例
#遍历跌幅最大的3只股票序列序号序列
for stock in stock_lower:
#profit即三只股票从第250天买入开始计算,直到最后一天的盈亏比例
profit+=buy_lower(stock)
print("买入第{}只股票,从第250个交易日开始持有盈亏:{:.2f}%".format(stock,profit))
买入第1348只股票,从第250个交易日开始持有盈亏:32.69%
买入第1376只股票,从第250个交易日开始持有盈亏:15.69%
买入第1325只股票,从第250个交易日开始持有盈亏:16.40%

Python的爱好者社区历史文章大合集:
Python的爱好者社区历史文章列表
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“ 课程 ”即可获取:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python的入门免费视频课程!
小编的Python的快速上手matplotlib可视化库!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告扩展制作免费学习视频。
玩转大数据分析!Spark2.X + Python精华实战课程免费学习视频。


