
作者:我叫丶钱小钱 Python爱好者社区专栏作者

简要概述:
话不多说先上词云,我们来看下网易云上张学友从1985-01-01《BTB 3EP张学友 + 黄凯芹》到 2014-12-23《醒着做梦》一共108张专辑,1300多首歌曲里到底唱了什么!?

先从网易云上获取张学友所有歌曲的歌词,然后把所有的歌词去重后全拼接成一个大文本,再然后~通过文本切词将文本切开获取所有的名词及动名词,切分后的结果如下:
爱情 0.07072471042756841
世界 0.06268317887188746
感觉 0.05650215736324936
眼泪 0.044849511174034074
伤心 0.039332645851527105
思念 0.03834038757061952
世间 0.03682804854767579
故事 0.03475690253214765
眼睛 0.03445409416550336
天空 0.03350860508998348
流泪 0.03312398416346928
梦想 0.03280878370931647
心窝 0.03243319396705214
记忆 0.03158641388911513
风雨 0.031456840476264326
星光 0.031069493653815176
笑容 0.030964867927921528
心痛 0.0307011710153588
空虚 0.029434459508895196
春风 0.02918087252372948
感情 0.028306639850443988
痴心 0.02801903059970057
深宵 0.027155899335446567
光阴 0.02679152211589159
情人 0.026615621955302014
黑夜 0.026111296684488385
我会 0.025771411677059368
人生 0.02545445923579143
背影 0.02465825420524522
词云生成用到了Tagul。非常棒的词云在线生成工具,你只需要下载一个unicode编码的字体包,如:arial unicode ms.ttf,接下来只需要将上面列表复制进词云表单里就可以生成酷炫的词云了。Tagul官网传送门:https://wordart.com/gallery
歌词的获取和文本切词,使用的语言是python,主要用到几个模块,bs4,requests,jieba,mysqldb 等,这些模块都可以通过pip install xxx这个指令快速安装,由于这里只获取张学友歌词所以没必要用到scrapy太重了,如果需要爬去全站的可以使用scrapy框架。
策略&思路:
获取网易音乐的信息比较不容易,基本上都是动态加载,反爬机制较完善。如果你是初学,一定在这上面会遇到不少会坑的地方,这里简单说下爬取思路。经供参考
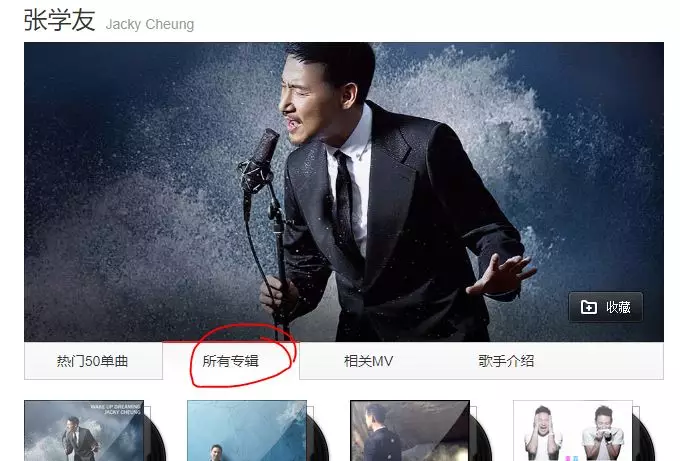
因为只想分析学友唱了什么,所以就直接在搜索栏搜学友,点选所有专辑如上图,我们看到这样一串链接http://music.163.com/#/artist/album?id=6460,看不出是什么?别急

我们点选到第二页看看变化,我们看到此时的url是http://music.163.com/#/artist/album?id=6460&limit=12&offset=12
第三页http://music.163.com/#/artist/album?id=6460&limit=12&offset=24
我们分析出其实offset从12变化到了24,有经验的爬友们可以知道limit12其实是每个页面有12张专辑,所以每翻一页url的offset+12,那么我们不用做翻,看他他总页数是9页那么9*12=108,那么学友至今108张专辑,真的是牛逼了。
那么我们尝试将url改成http://music.163.com/#/artist/album?id=6460&limit=108 不需要翻页,让页面直接显示108张专辑,ok我们接下来开始requests.get...Beautifulsoup...。
如果你们真的requests.get...Beautifulsoup...了,那么恭喜你,你成功被耍了。因为你返回的页面没有你要的数据。
好!我们打开chrome抓包,在密密麻麻的加载项中发现一个非常熟悉的链接,点开发现他真实request url其实是不带#号的,说明之前那个url是假的
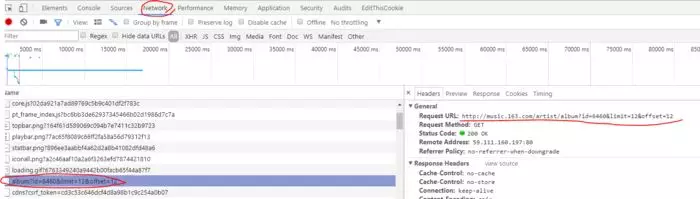
ok再次requests.get...Beautifulsoup
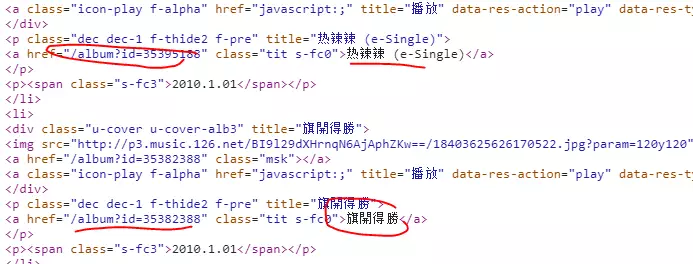
我们要的数据也取到了,然后获取该专辑href,然后做链接拼接再进入专辑详情页。这里详情页获取同上需要进入抓包分析具体链接
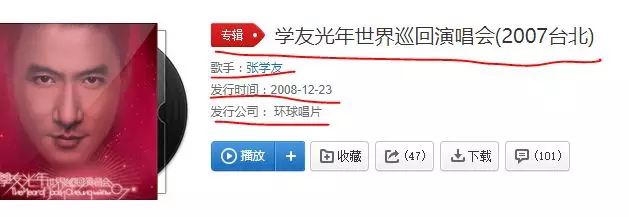
爬爬爬~ 都爬了~ 经过之地寸草不生~
在爬去歌单的时候需要获取后面的歌曲id如下图

然后拼接歌词api,api是由百度提供~我们只需要将歌曲id放入去拼接出url,再次requests即可获取详细歌词
http://music.163.com/api/song/lyric?os=pc&id= str(song_id) &lv=-1&kv=-1&tv=-1
注意事项:
这里注意爬取的时候频繁返回503,经常会报错或者漏爬,短时间不能再次爬取,时间大概在半小时,所以大家可以类似这样的代码去判断爬取失败的循环
if response.status_code <> 200:
requests_error_list.append(response.url)
time.sleep(300)有了爬去失败列表那么在最后将这些url再拿出来再次爬取,同样先判断状态是否200,然后判断url后缀,类似album?id=19008这样的则是专辑名url,song?id=187449则为歌曲url
参考代码:
if requests_error_list:
for url in requests_error_list:
if 'album?id=' in url:
requests_album_url()
if 'song?id=' in url:
requests_song_url()
response.status_code <> 200: requests_error_list.append(url)
time.sleep(300)爬虫代码:
conn = MySQLdb.connect(host="localhost",
user="root",
passwd="root",
db="webspider",
charset="utf8",
use_unicode=True)
cursor = conn.cursor()
cursor2 = conn.cursor()
def ua_random():
headers = {
"User-Agent": UserAgent().Chrome, "Connection": "keep-alive",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8", "Referer": "http: // music.163.com /"
}
return headers
url = 'http://music.163.com/artist/album?id=6460&limit=108'response = requests.get(url, headers=ua_random())
print(response.status_code)
soup = BeautifulSoup(response.content, 'lxml')
album_href_taglist = soup.select('a.tit.s-fc0')
album_href_list = [_.get('href') for _ in album_href_taglist]
album_id_list = [_.split('=')[1].strip() for _ in album_href_list]
print(album_id_list)
for album_id in album_id_list:
url2 = ''.join(['http://music.163.com/album?id=', album_id])
response2 = requests.get(url2, headers=ua_random())
soup2 = BeautifulSoup(response2.content, 'lxml') # print(soup2)
song_taglist = soup2.select('ul.f-hide a')
# print(song_taglist)
song_href_list = [_.get('href') for _ in song_taglist]
song_id_list = [_.split('=')[1].strip() for _ in song_href_list]
# print(song_id_list)
album_id = album_id.strip()
try:
album_name = soup2.select_one('h2.f-ff2').get_text().strip()
album_issue_date = soup2.select('p.intr')[1].get_text().split(':')[1].strip()
try:
issue_company_name = soup2.select('p.intr')[2].get_text().split(':')[1].strip()
except IndexError:
issue_company_name = None
except:
album_name = None
album_issue_date = None
print(response2.status_code, response2.url)
continue
insert_sql = """INSERT INTO album_info(album_id ,album_name,album_issue_date,issue_company_name)
VALUES (%s, %s, %s, %s)
"""
print(album_id,
album_name,
album_issue_date,
issue_company_name)
cursor.execute(insert_sql, (album_id,
album_name,
album_issue_date,
issue_company_name))
song_info_temp = soup2.textarea.get_text()
song_info = json.loads(song_info_temp)
for v in song_info:
song_id = v['id']
song_name = v['name']
singer = ','.join([_['name'] for _ in v['artists']])
song_time = None
album_id = album_id.strip()
url3 = ''.join(['http://music.163.com/api/song/lyric?os=pc&id=',
str(song_id),
'&lv=-1&kv=-1&tv=-1'])
response3 = requests.get(url3, headers=ua_random())
# time.sleep(1)
soup3 = BeautifulSoup(response3.content, 'lxml')
# print(soup3.get_text())
try:
lrc_temp = json.loads(soup3.get_text())['lrc']['lyric']
lyric = re.sub(r"\[(.*)\]", '', lrc_temp)
except KeyError:
lyric = '无歌词'
except json.decoder.JSONDecodeError:
lyric = None
print(response3.status_code, response3.url)
insert_sql = """INSERT INTO song_info(song_id,song_name,song_time,singer,lyric,album_id)
VALUES (%s, %s, %s, %s, %s, %s)
"""
cursor2.execute(insert_sql, (song_id,
song_name,
song_time,
singer,
lyric,
album_id))
conn.commit()
conn.close()
jieba分词代码:
conn = MySQLdb.connect(host="localhost",
user="root",
passwd="root",
db="webspider",
charset="utf8", use_unicode=True)
sql = '''
SELECT * from webspider.album_info as a
left join webspider.song_info as b on a.album_id = b.album_id
where b.lyric IS NOT NULL AND b.lyric <> '无歌词'
'''
df = pandas.read_sql(sql, con=conn, )
# print(df.head(10))
t_list = df.lyric
all_union_text = ';'.join(t_list).replace('作曲 :', '').replace('作词 :', '')
text = ','.join(set(','.join(set(all_union_text.split('\n'))).split()))
# seg_list = jieba.cut(all_union_text,cut_all=True)
# print(' '.join(seg_list))
keywords = jieba.analyse.extract_tags(text, topK=20, withWeight=True, allowPOS=('n', 'nv'))
for i in keywords:
print(i[0], i[1])

Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门免费视频课程!!!
【最新免费微课】小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
