作者:ApacheCN【翻译】 Python机器学习爱好者
Python爱好者社区专栏作者
GitHub:https://github.com/apachecn/hands_on_Ml_with_Sklearn_and_TF
鸟类启发我们飞翔,牛蒡植物启发了尼龙绳,大自然也激发了许多其他发明。从逻辑上看,大脑是如何构建智能机器的灵感。这是启发人工神经网络(ANN)的关键思想。然而,尽管飞机受到鸟类的启发,但它们不必拍动翅膀。同样的,ANN 逐渐变得与他们的生物表兄弟有很大的不同。一些研究者甚至争辩说,我们应该完全放弃生物类比(例如,通过说“单位”而不是“神经元”),以免我们把我们的创造力限制在生物学的系统上。
人工神经网络是深度学习的核心。它们具有通用性、强大性和可扩展性,使得它们能够很好地解决大型和高度复杂的机器学习任务,例如分类数十亿图像(例如,谷歌图像),强大的语音识别服务(例如,苹果的 Siri),通过每天追踪数百万的用户的行为推荐最好的视频(比如 YouTube),或者通过在游戏中击败世界冠军,通过学习数百万的游戏,然后与自己对抗(DeepMind 的 AlgFaGo)。
在本章中,我们将介绍人工神经网络,从快速游览的第一个ANN架构开始。然后,我们将提出多层感知器(MLP),并基于TensorFlow实现MNIST数字分类问题(在第3章中介绍)。
从生物到人工神经元
令人惊讶的是,人工神经网络已经存在了相当长的一段时间:它们最初是由神经生理学家 Warren McCulloch 和数学家 Walter Pitts 在 1943 提出。McCulloch 和 Pitts 在其里程碑式的论文中提出了“神经活动内在的逻辑演算”,提出了一个简化的计算模型,即生物神经元如何在动物大脑中协同工作,用逻辑进行复杂的计算。这是第一个人工神经网络体系结构。从那时起,正如我们将看到的,许多其他的神经元结构已经被发明.
直到 20 世纪 60 年代,安纳斯的早期成功才使人们普遍相信我们很快就会与真正的智能机器对话。当显然的这个承诺将不会被兑现(至少相当长一段时间)时,资金飞向别处,ANN 进入了一个漫长的黑暗时代。20 世纪 80 年代初,随着新的网络体系结构的发明和更好的训练技术的发展,人们对人工神经网络的兴趣也在重新燃起。但到了 20 世纪 90 年代,强大的可替代机器学习技术的,如支持向量机(见第5章)受到大多数研究者的青睐,因为它们似乎提供了更好的结果和更强的理论基础。最后,我们现在目睹了另一股对 ANN 感兴趣的浪潮。这波会像以前一样消失吗?有一些很好的理由相信,这一点是不同的,将会对我们的生活产生更深远的影响:
现在有大量的数据可用于训练神经网络,ANN 在许多非常复杂的问题上经常优于其他 ML 技术。
自从 90 年代以来,计算能力的巨大增长使得在合理的时间内训练大型神经网络成为可能。这部分是由于穆尔定律,但也得益于游戏产业,它已经产生了数以百万计的强大的 GPU 显卡。
改进了训练算法。公平地说,它们与上世纪 90 年代使用的略有不同,但这些相对较小的调整产生了巨大的正面影响。
在实践中,人工神经网络的一些理论局限性是良性的。例如,许多人认为人工神经网络训练算法是注定的,因为它们很可能陷入局部最优,但事实证明,这在实践中是相当罕见的(或者如果它发生,它们也通常相当接近全局最优)。
ANN 似乎已经进入了资金和进步的良性循环。基于 ANN 的惊人产品定期成为头条新闻,吸引了越来越多的关注和资金,导致越来越多的进步,甚至更惊人的产品。
生物神经元
在我们讨论人工神经元之前,让我们快速看一个生物神经元(如图 10-1 所示)。它是一种异常细胞,主要见于动物大脑皮层(例如,你的大脑),由包含细胞核和大多数细胞复杂成分的细胞体组成,许多分支扩展称为树突,加上一个非常长的延伸称为轴突。轴突的长度可能比细胞体长几倍,或长达几万倍。在它的末端附近,轴突分裂成许多称为 telodendria 的分支,在这些分支的顶端是微小的结构,称为突触末端(或简单的突触),它们连接到其他神经元的树突(或直接到细胞体)。生物神经元接收短的电脉冲,称为来自其他神经元的信号,通过这些突触。当神经元在几毫秒内接收到来自其他神经元的足够数量的信号时,它就发射出自己的信号。

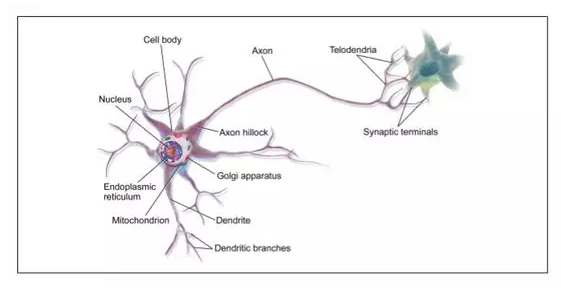
因此,个体的生物神经元似乎以一种相当简单的方式运行,但是它们组织在一个巨大的数十亿神经元的网络中,每个神经元通常连接到数千个其他神经元。高度复杂的计算可以由相当简单的神经元的巨大网络来完成,就像一个复杂的蚁穴可以由每个蚂蚁的努力构造出来。生物神经网络(BNN)的体系结构仍然是主动研究的主题,但是大脑的某些部分已经被映射,并且似乎神经元经常组织在连续的层中,如图 10-2 所示。

神经元的逻辑计算
Warren McCulloch 和 Pitts 提出一个非常简单的生物神经元模型,这后来作为一个人工神经元成为众所周知:它有一个或更多的二进制(ON/OFF)输入和一个二进制输出。当超过一定数量的输入是激活时,人工神经元会激活其输出。McCulloch 和 Pitts 表明,即使用这样一个简化的模型,也有可能建立一个人工神经元网络来计算任何你想要的逻辑命题。例如,让我们构建一些执行各种逻辑计算的 ANN(见图 10-3),假设当至少两个输入是激活的时候神经元被激活。
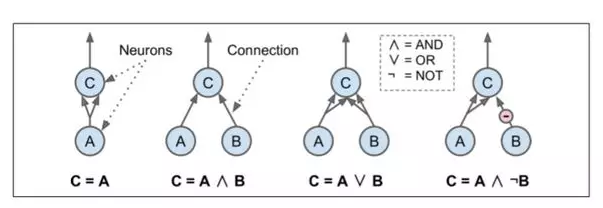
左边的第一个网络仅仅是确认函数:如果神经元 A 被激活,那么神经元 C 也被激活(因为它接收来自神经元 A 的两个输入信号),但是如果神经元 A 关闭,那么神经元 C 也关闭。
第二网络执行逻辑 AND:神经元 C 只有在激活神经元 A 和 B(单个输入信号不足以激活神经元 C)时才被激活。
第三网络执行逻辑 OR:如果神经元 A 或神经元 B 被激活(或两者),神经元 C 被激活。
最后,如果我们假设输入连接可以抑制神经元的活动(生物神经元是这样的情况),那么第四个网络计算一个稍微复杂的逻辑命题:如果神经元 B 关闭,只有当神经元A是激活的,神经元 C 才被激活。如果神经元 A 始终是激活的,那么你得到一个逻辑 NOT:神经元 C 在神经元 B 关闭时是激活的,反之亦然。
您可以很容易地想象如何将这些网络组合起来计算复杂的逻辑表达式(参见本章末尾的练习)。
感知器
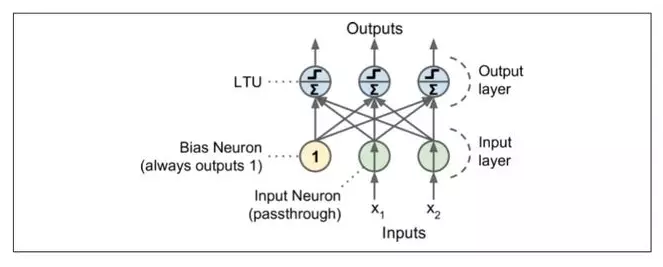
感知器是最简单的人工神经网络结构之一,由 Frank Rosenblatt 发明于 1957。它是基于一种稍微不同的人工神经元(见图 10-4),称为线性阈值单元(LTU):输入和输出现在是数字(而不是二进制开/关值),并且每个输入连接都与权重相连。LTU计算其输入的加权和(z = W1×1 + W2×2 + ... + + WN×n = Wt·x),然后将阶跃函数应用于该和,并输出结果:HW(x) = STEP(Z) = STEP(W^T·x)。
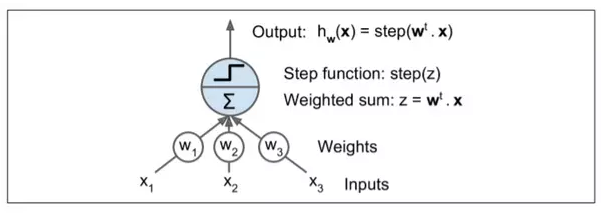
最常见的在感知器中使用的阶跃函数是 Heaviside 阶跃函数(见方程 10-1)。有时使用符号函数代替。
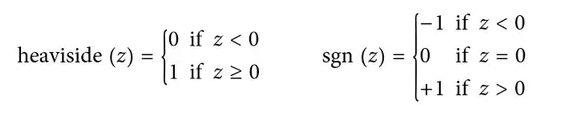
单一的 LTU 可被用作简单线性二元分类。它计算输入的线性组合,如果结果超过阈值,它输出正类或者输出负类(就像一个逻辑回归分类或线性 SVM)。例如,你可以使用单一的 LTU 基于花瓣长度和宽度去分类鸢尾花(也可添加额外的偏置特征x0=1,就像我们在前一章所做的)。训练一个 LTU 意味着去寻找合适的W0和W1值,(训练算法稍后提到)。
感知器简单地由一层 LTU 组成,每个神经元连接到所有输入。这些连接通常用特殊的被称为输入神经元的传递神经元来表示:它们只输出它们所输入的任何输入。此外,通常添加额外偏置特征(X0=1)。这种偏置特性通常用一种称为偏置神经元的特殊类型的神经元来表示,它总是输出 1。
图 10-5 表示具有两个输入和三个输出的感知器。该感知器可以将实例同时分类为三个不同的二进制类,这使得它是一个多输出分类器。
那么感知器是如何训练的呢?Frank Rosenblatt 提出的感知器训练算法在很大程度上受到 Hebb 规则的启发。在 1949 出版的《行为组织》一书中,Donald Hebb 提出,当一个生物神经元经常触发另一个神经元时,这两个神经元之间的联系就会变得更强。这个想法后来被 Siegrid Löwel 总结为一个吸引人的短语:“一起燃烧的细胞,汇合在一起。”这个规则后来被称为 Hebb 规则(或 HebBIN 学习);也就是说,当两个神经元具有相同的输出时,它们之间的连接权重就会增加。使用这个规则的变体来训练感知器,该规则考虑了网络所犯的错误;它不加强导致错误输出的连接。更具体地,感知器一次被馈送一个训练实例,并且对于每个实例,它进行预测。对于每一个产生错误预测的输出神经元,它加强了输入的连接权重,这将有助于正确的预测。该规则在公式 10-2 中示出。
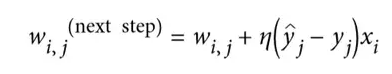
每个输出神经元的决策边界是线性的,因此感知机不能学习复杂的模式(就像 Logistic 回归分类器)。然而,如果训练实例是线性可分离的,Rosenblatt 证明该算法将收敛到一个解。这被称为感知器收敛定理。
sklearn 提供了一个感知器类,它实现了一个 LTU 网络。它可以像你所期望的那样使用,例如在 iris 数据集(第 4 章中介绍):
import numpy as np
from sklearn.datasets
import load_iris from sklearn.linear_model import Perceptron
iris = load_iris() X = iris.data[:, (2, 3)] # 花瓣长度,宽度
y = (iris.target == 0).astype(np.int)
per_clf = Perceptron(random_state=42)
per_clf.fit(X, y)
y_pred = per_clf.predict([[2, 0.5]])
您可能已经认识到,感知器学习算法类似于随机梯度下降。事实上,sklearn 的感知器类相当于使用具有以下超参数的 SGD 分类器:loss="perceptron",learning_rate="constant"(学习率),eta0=1,penalty=None(无正则化)。
注意,与逻辑斯蒂回归分类器相反,感知机不输出类概率,而是基于硬阈值进行预测。这是你喜欢逻辑斯蒂回归很好的一个理由。
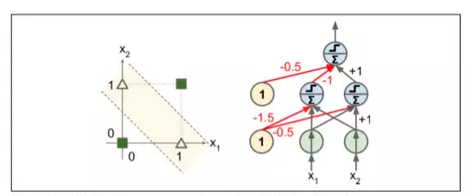
在他们的 1969 个题为“感知者”的专著中,Marvin Minsky 和 Seymour Papert 强调了感知机的许多严重缺陷,特别是它们不能解决一些琐碎的问题(例如,异或(XOR)分类问题);参见图 10-6 的左侧)。当然,其他的线性分类模型(如 Logistic 回归分类器)也都实现不了,但研究人员期望从感知器中得到更多,他们的失望是很大的:因此,许多研究人员放弃了联结主义(即神经网络的研究),这有利于更高层次的问题,如逻辑、问题解决和搜索。
然而,事实证明,感知器的一些局限性可以通过堆叠多个感知器来消除。由此产生的人工神经网络被称为多层感知器(MLP)。特别地,MLP 可以解决 XOR 问题,因为你可以通过计算图 10-6 右侧所示的 MLP 的输出来验证输入的每一个组合:输入(0, 0)或(1, 1)网络输出 0,并且输入(0, 1)或(1, 0)它输出 1。
Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门免费视频课程!!!
【最新免费微课】小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。

