作者:ApacheCN【翻译】 Python机器学习爱好者
Python爱好者社区专栏作者
GitHub:https://github.com/apachecn/hands_on_Ml_with_Sklearn_and_TF
梯度提升
另一个非常著名的提升算法是梯度提升。与 Adaboost 一样,梯度提升也是通过向集成中逐步增加分类器运行的,每一个分类器都修正之前的分类结果。然而,它并不像 Adaboost 那样每一次迭代都更改实例的权重,这个方法是去使用新的分类器去拟合前面分类器预测的残差 。
让我们通过一个使用决策树当做基分类器的简单的回归例子(回归当然也可以使用梯度提升)。这被叫做梯度提升回归树(GBRT,Gradient Tree Boosting 或者 Gradient Boosted Regression Trees)。首先我们用DecisionTreeRegressor去拟合训练集(例如一个有噪二次训练集):
>>>from sklearn.tree import DecisionTreeRegressor
>>>tree_reg1 = DecisionTreeRegressor(max_depth=2)
>>>tree_reg1.fit(X, y)
现在在第一个分类器的残差上训练第二个分类器:
>>>y2 = y - tree_reg1.predict(X)
>>>tree_reg2 = DecisionTreeRegressor(max_depth=2)
>>>tree_reg2.fit(X, y2)
随后在第二个分类器的残差上训练第三个分类器:
>>>y3 = y2 - tree_reg1.predict(X)
>>>tree_reg3 = DecisionTreeRegressor(max_depth=2)
>>>tree_reg3.fit(X, y3)
现在我们有了一个包含三个回归器的集成。它可以通过集成所有树的预测来在一个新的实例上进行预测。
>>>y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
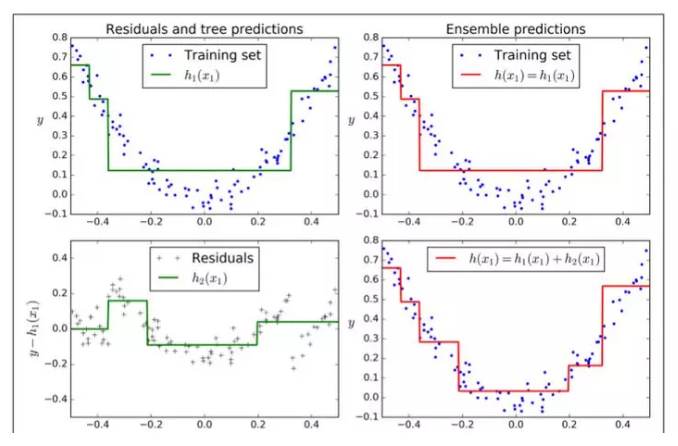
图7-9在左栏展示了这三个树的预测,在右栏展示了集成的预测。在第一行,集成只有一个树,所以它与第一个树的预测相似。在第二行,一个新的树在第一个树的残差上进行训练。在右边栏可以看出集成的预测等于前两个树预测的和。相同的,在第三行另一个树在第二个数的残差上训练。你可以看到集成的预测会变的更好。
我们可以使用 sklean 中的GradientBoostingRegressor来训练 GBRT 集成。与RandomForestClassifier相似,它也有超参数去控制决策树的生长(例如max_depth,min_samples_leaf等等),也有超参数去控制集成训练,例如基分类器的数量(n_estimators)。接下来的代码创建了与之前相同的集成:
>>>from sklearn.ensemble import GradientBoostingRegressor
>>>gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
>>>gbrt.fit(X, y)
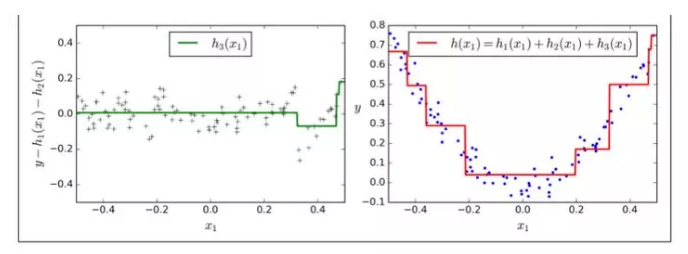
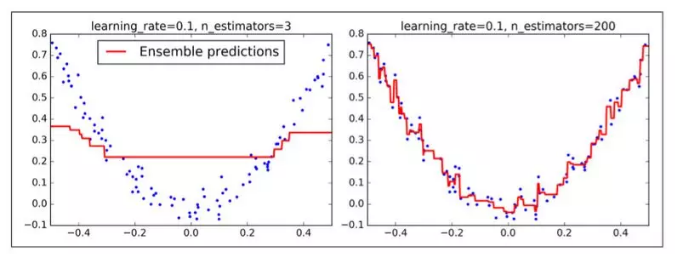
超参数learning_rate 确立了每个树的贡献。如果你把它设置为一个很小的树,例如 0.1,在集成中就需要更多的树去拟合训练集,但预测通常会更好。这个正则化技术叫做 shrinkage。图 7-10 展示了两个在低学习率上训练的 GBRT 集成:其中左面是一个没有足够树去拟合训练集的树,右面是有过多的树过拟合训练集的树。
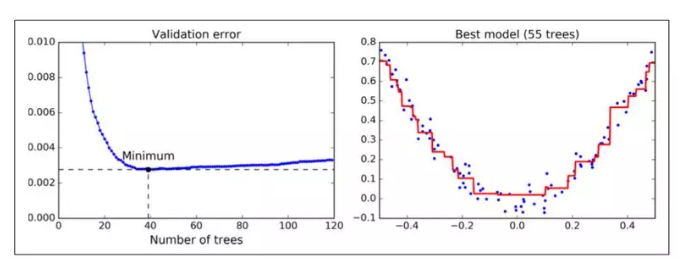
为了找到树的最优数量,你可以使用早停技术(第四章讨论)。最简单使用这个技术的方法就是使用staged_predict():它在训练的每个阶段(用一棵树,两棵树等)返回一个迭代器。加下来的代码用 120 个树训练了一个 GBRT 集成,然后在训练的每个阶段验证错误以找到树的最佳数量,最后使用 GBRT 树的最优数量训练另一个集成:
>>>import numpy as np
>>>from sklearn.model_selection import train_test_split
>>>from sklearn.metrics import mean_squared_error
>>>X_train, X_val, y_train, y_val = train_test_split(X, y)
>>>gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120)
>>>gbrt.fit(X_train, y_train)
>>>errors = [mean_squared_error(y_val, y_pred)
for y_pred in gbrt.staged_predict(X_val)]
>>>bst_n_estimators = np.argmin(errors)
>>>gbrt_best = GradientBoostingRegressor(max_depth=2,n_estimators=bst_n_estimators)
>>>gbrt_best.fit(X_train, y_train)
验证错误在图 7-11 的左面展示,最优模型预测被展示在右面。

你也可以早早的停止训练来实现早停(与先在一大堆树中训练,然后再回头去找最优数目相反)。你可以通过设置warm_start=True来实现 ,这使得当fit()方法被调用时 sklearn 保留现有树,并允许增量训练。接下来的代码在当一行中的五次迭代验证错误没有改善时会停止训练:
>>>gbrt = GradientBoostingRegressor(max_depth=2, warm_start=True)
min_val_error = float("inf")
error_going_up = 0
for n_estimators in range(1, 120):
gbrt.n_estimators = n_estimators
gbrt.fit(X_train, y_train)
y_pred = gbrt.predict(X_val)
val_error = mean_squared_error(y_val, y_pred)
if val_error < min_val_error:
min_val_error = val_error
error_going_up = 0
else:
error_going_up += 1
if error_going_up == 5:
break # early stopping
GradientBoostingRegressor也支持指定用于训练每棵树的训练实例比例的超参数subsample。例如如果subsample=0.25,那么每个树都会在 25% 随机选择的训练实例上训练。你现在也能猜出来,这也是个高偏差换低方差的作用。它同样也加速了训练。这个技术叫做随机梯度提升。
也可能对其他损失函数使用梯度提升。这是由损失超参数控制(见 sklearn 文档)。
Stacking
本章讨论的最后一个集成方法叫做 Stacking(stacked generalization 的缩写)。这个算法基于一个简单的想法:不使用琐碎的函数(如硬投票)来聚合集合中所有分类器的预测,我们为什么不训练一个模型来执行这个聚合?图 7-12 展示了这样一个在新的回归实例上预测的集成。底部三个分类器每一个都有不同的值(3.1,2.7 和 2.9),然后最后一个分类器(叫做 blender 或者meta learner )把这三个分类器的结果当做输入然后做出最终决策(3.0)。
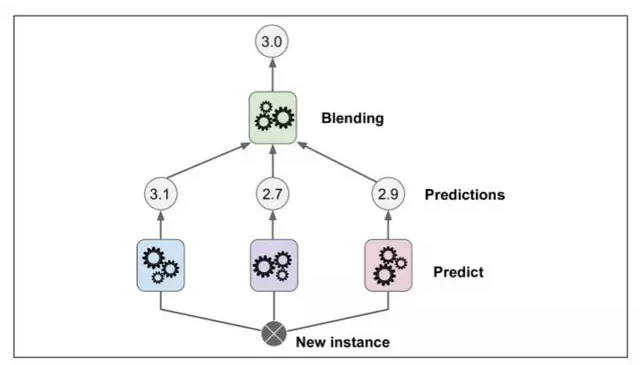
为了训练这个 blender ,一个通用的方法是采用保持集。让我们看看它怎么工作。首先,训练集被分为两个子集,第一个子集被用作训练第一层(详见图 7-13).
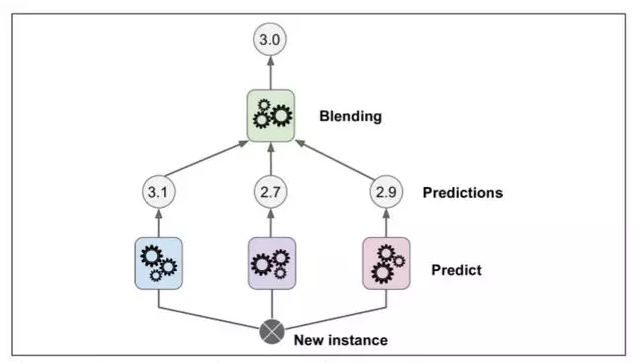
接下来,第一层的分类器被用来预测第二个子集(保持集)(详见 7-14)。这确保了预测结果很“干净”,因为这些分类器在训练的时候没有使用过这些事例。现在对在保持集中的每一个实例都有三个预测值。我们现在可以使用这些预测结果作为输入特征来创建一个新的训练集(这使得这个训练集是三维的),并且保持目标数值不变。随后 blender 在这个新的训练集上训练,因此,它学会了预测第一层预测的目标值。
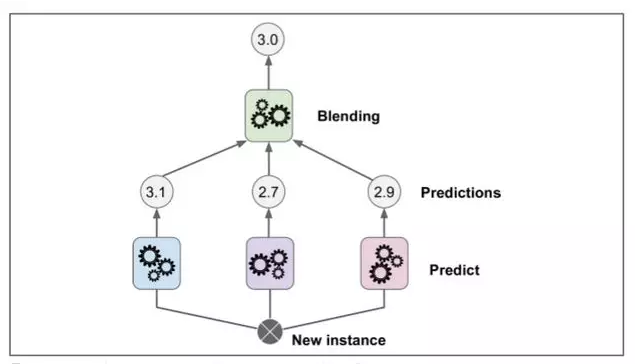
显然我们可以用这种方法训练不同的 blender (例如一个线性回归,另一个是随机森林等等):我们得到了一层 blender 。诀窍是将训练集分成三个子集:第一个子集用来训练第一层,第二个子集用来创建训练第二层的训练集(使用第一层分类器的预测值),第三个子集被用来创建训练第三层的训练集(使用第二层分类器的预测值)。以上步骤做完了,我们可以通过逐个遍历每个层来预测一个新的实例。详见图 7-15.
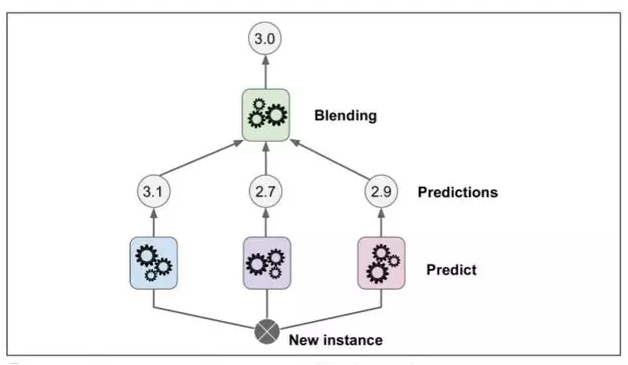
然而不幸的是,sklearn 并不直接支持 stacking ,但是你自己组建是很容易的(看接下来的练习)。或者你也可以使用开源的项目例如 brew (网址为 https://github.com/viisar/brew)
练习
如果你在相同训练集上训练 5 个不同的模型,它们都有 95% 的准确率,那么你是否可以通过组合这个模型来得到更好的结果?如果可以那怎么做呢?如果不可以请给出理由。
软投票和硬投票分类器之间有什么区别?
是否有可能通过分配多个服务器来加速 bagging 集成系统的训练?pasting 集成,boosting 集成,随机森林,或 stacking 集成怎么样?
out-of-bag 评价的好处是什么?
是什么使 Extra-Tree 比规则随机森林更随机呢?这个额外的随机有什么帮助呢?那这个 Extra-Tree 比规则随机森林谁更快呢?
如果你的 Adaboost 模型欠拟合,那么你需要怎么调整超参数?
如果你的梯度提升过拟合,那么你应该调高还是调低学习率呢?
导入 MNIST 数据(第三章中介绍),把它切分进一个训练集,一个验证集,和一个测试集(例如 40000 个实例进行训练,10000 个进行验证,10000 个进行测试)。然后训练多个分类器,例如一个随机森林分类器,一个 Extra-Tree 分类器和一个 SVM。接下来,尝试将它们组合成集成,使用软或硬投票分类器来胜过验证集上的所有集合。一旦找到了,就在测试集上实验。与单个分类器相比,它的性能有多好?
从练习 8 中运行个体分类器来对验证集进行预测,并创建一个新的训练集并生成预测:每个训练实例是一个向量,包含来自所有分类器的图像的预测集,目标是图像类别。祝贺你,你刚刚训练了一个 blender ,和分类器一起组成了一个叠加组合!现在让我们来评估测试集上的集合。对于测试集中的每个图像,用所有分类器进行预测,然后将预测馈送到 blender 以获得集合的预测。它与你早期训练过的投票分类器相比如何?
练习的答案都在附录 A 上。
Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战免费学习视频。

