
作者介绍:宋天龙(TonySong),资深大数据技术专家,历任软通动力集团大数据研究院数据总监、Webtrekk(德国最大的网站数据分析服务提供商)中国区技术和咨询负责人、国美在线大数据中心经理。
本文来自《Python数据分析与数据化运营》配套书籍第6章节内容,机械工业出版社华章授权发布,未经允许,禁止转载!
此书包含 50个数据工作流知识点,14个数据分析和挖掘主题,8个综合性运营案例。涵盖了会员、商品、流量、内容4大数据化运营主题,360°把脉运营问题并贴合数据场景落地。
书籍购买链接:https://item.jd.com/12254905.html
课程学习链接:网站数据分析场景和方法——效果预测、结论定义、数据探究和业务执行https://edu.hellobi.com/course/221
往期回顾:Python数据分析与数据化运营:会员数据化运营1-概述与关键指标
Python数据分析与数据化运营:会员数据化运营2-应用场景与分析模型
Python数据分析与数据化运营:会员数据化运营3-分析小技巧
Python数据分析与数据化运营:会员数据化运营4-“大实话”
Python数据分析与数据化运营:会员数据化运营5-案例:基于RFM的用户价值度分析
Python数据分析与数据化运营:商品数据化运营1-概述与关键指标
Python数据分析与数据化运营:商品数据化运营2-应用场景与分析模型
Python数据分析与数据化运营:商品数据化运营3-分析小技巧
Python数据分析与数据化运营:商品数据化运营4-“大实话”
6.7.1 案例背景
商品销售预测几乎是每个运营部门的必备数据支持项目,无论是大型促销活动还是单品营销都是如此。本案例就是针对某单品做的订单量预测应用。
本节案例的输入源数据products_sales.txt和源代码chapter6_code1.py位于“附件-chapter6”中,默认工作目录为“附件-chapter6”(如果不是,请cd切换到该目录下,否则会报“IOError: File products_sales.txt does not exist”)。程序的输出预测数据直接打印输出,没有写入文件。
6.7.2 案例主要应用技术
本案例用到的主要技术包括:
- 基本预处理:包括缺失值填充、异常值处理以及特征变量的相关性校验。
- 数据建模:超参数交叉检验和优化方法GridSearchCV、集成回归方法GradientBoostingRegressor。
- 图形展示:使用matplotlib做折线图展示。
主要用到的库包括:numpy、pandas、sklearn、matplotlib,其中sklearn是数据建模的核心库。
本案例的技术应用重点是设置集成回归算法的不同参数值,通过GridSearchCV方法对每个参数值(或值对)做遍历,从指定的交叉检验得分中寻找最优值并得到最优值下的集成回归算法模型。这是一种更为自动化的参数优化方法。
6.7.3 案例数据
案例数据是某企业的运营活动数据,其中一些数据来源于每次销售系统,有些来源于每次运营系统,还有一些来源于手动运营记录。以下是数据概况:
- 特征变量数:10
- 数据记录数:731
- 是否有NA值:有
- 是否有异常值:有
以下是本数据集的10个特征变量,包括:
- limit_infor:是否有限购字样信息提示,1代表有,0代表没有。
- campaign_type:促销活动类型,分类型变量,值域为[0,6]代表7种不同类型的促销活动,例如单品活动、跨店铺活动、综合性活动、3C大品类活动等。
- campaign_level:促销活动重要性,分类型变量,值域为[0,1],分别代表促销活动本身的不重要或重要性程度。
- product_level:产品重要性分级,分类型变量,值域为[1,3],分别代表运营部门对于商品重要性的分级。
- resource_amount:促销资源位数量,整数型变量,代表每次该商品在参加促销活动时有多少个资源位入口。
- email_rate:发送电子邮件中包含该商品的比例,浮点型变量,值域[0,1],值越大代表包含该商品的电子邮件越多。
- price:单品价格,整数型变量,代码商品在不同阶段的实际销售价格。
- discount_rate:折扣率,浮点型变量,值域[0,1],值越大代表折扣力度越大。
- hour_resouces:在促销活动中展示的小时数,整数型变量,值越大代表展示的时间越长。
- campaign_fee:该单品的促销费用,整数型变量,值越大代表用于该单品的综合促销费用越高,这里面包含促销费用、广告费用、优惠券费用等综合摊派的费用。
目标变量:orders,代表该单品在每次活动中形成的订单量。
6.7.4 案例过程
步骤1 导入库
import numpy as np # 导入numpy库
import pandas as pd # 导入pandas库
from sklearn.ensemble import GradientBoostingRegressor # 集成方法回归库
from sklearn.model_selection import GridSearchCV # 导入交叉检验库
import matplotlib.pyplot as plt # 导入图形展示库本案例主要用到了以下库:
- numpy:基本数据处理。
- pandas:数据读取、审查、异常值处理、缺失值处理、相关性分析等。
- GradientBoostingRegressor:集成方法GradientBoosting的回归库,本案例核心库之一。
- GridSearchCV:对超参数进行交叉检验优化的库。
- matplotlib:画折线图。
步骤2 读取数据,该步骤使用pandas的read_table方法读取txt文件,指定数据分隔符为逗号。
raw_data = pd.read_table('products_sales.txt', delimiter=',')步骤3 数据审查和校验,该步骤包含了数据概览、类型分布、描述性统计值域分布、缺失值审查、相关性分析4个部分。
第一部分 数据概览,目的是查看基本概况、分布规律等。
print ('{:*^60}'.format('Data overview:'))
print (raw_data.tail(2)) # 打印原始数据后2条
print ('{:*^60}'.format('Data dtypes:'))
print (raw_data.dtypes) # 打印数据类型
print ('{:*^60}'.format('Data DESC:'))
print (raw_data.describe().round(1).T) # 打印原始数据基本描述性信息该部分的内容在之前很多章节都有介绍,重点介绍其中两个略有差异的应用点:
- raw_data.tail()用来展示最后2条数据,跟raw_data.head()方法相对应。
- 使用round()方法保留1位小数,这样展示的内容更加简洁。
- 通过.T的方法做矩阵转置操作,该操作等同于transpose(),转置的目的也是展示更加简洁。
上述代码执行后输入如下结果:
基本数据审查结果,发现数据读取格式跟源数据相同。
***********************Data overview:***********************
limit_infor campaign_type campaign_level product_level \
729 0 6 0 1
730 0 6 0 1
resource_amount email_rate price discount_rate hour_resouces \
729 8 0.8 150.0 0.87 987
730 9 0.8 149.0 0.84 1448
campaign_fee orders
729 2298 3285
730 3392 4840 数据类型结果,数据类型可以正确读取。
************************Data dtypes:************************
limit_infor int64
campaign_type int64
campaign_level int64
product_level int64
resource_amount int64
email_rate float64
price float64
discount_rate float64
hour_resouces int64
campaign_fee int64
orders int64
dtype: object数据描述性统计结果
*************************Data DESC:*************************
count mean std min 25% 50% 75% max
limit_infor 731.0 0.0 0.4 0.0 0.0 0.0 0.0 10.0
campaign_type 731.0 3.0 2.0 0.0 1.0 3.0 5.0 6.0
campaign_level 731.0 0.7 0.5 0.0 0.0 1.0 1.0 1.0
product_level 731.0 1.4 0.5 1.0 1.0 1.0 2.0 3.0
resource_amount 731.0 5.0 1.8 1.0 3.0 5.0 7.0 9.0
email_rate 731.0 0.5 0.2 0.1 0.3 0.5 0.6 0.8
price 729.0 162.8 14.3 100.0 152.0 163.0 173.0 197.0
discount_rate 731.0 0.8 0.1 0.5 0.8 0.8 0.9 1.0
hour_resouces 731.0 848.2 686.6 2.0 315.5 713.0 1096.0 3410.0
campaign_fee 731.0 3696.4 1908.6 20.0 2497.0 3662.0 4795.5 33380.0
orders 731.0 4531.1 1932.5 22.0 3199.0 4563.0 6011.5 8714.0在描述性统计结果中,以行为单位查看每个特征变量的基本信息,发现以下异常点:
limit_infor的值域应该是0或1,但是最大值却出现了10。
campaign_fee的标准差非常大,说明分布中存在异常点,并且最大值是33380,严重超过均值。
price的记录数只有729,而其他特征变量的有效记录是731,说明该列有2个缺失值。第二部分查看值域分布,目的是查看分类变量的各个变量的值域分布。在第一部分中发现了属于分类变量中出现了异常分布值,这里需要做下进一步验证。
col_names = ['limit_infor', 'campaign_type', 'campaign_level', 'product_level'] # 定义要查看的列
for col_name in col_names: # 循环读取每个列
unque_value = np.sort(raw_data[col_name].unique()) # 获得列唯一值
print ('{:*^50}'.format('{1} unique values:{0}').format(unque_value, col_name)) # 打印输出实现过程中先定义了要查看的分类变量,然后通过for循环读取每个特征名称,并使用dataframe的unique方法获取唯一值,然后使用numpy的sort方法排序并打印输出。上述执行输入结果如下:
**************limit_infor unique values:[ 0 1 10]***************
**************campaign_type unique values:[0 1 2 3 4 5 6]***************
**************campaign_level unique values:[0 1]***************
**************product_level unique values:[1 2 3]***************从结果看出,limit_infor确实存在值域分布问题,其他的分类变量则正常。
相关知识点:使用多种方法做数据框切片
Pandas提供了多种方法可以用来做数据框切片,本书的示例中用到的主要是基于指定列名的方法。下面以limit_infor为例说明选择不同列(特征)的具体用法:
通过列名方法选择
用法:raw_data['limit_infor'],这是最常用的选择方法,这种方法无需知晓目标列的具体索引值,只需知晓列名即可,可充分利用pandas的良好交互优势。当然,也可以使用raw_data[[0]]来选取,其选择的结果是一个矩阵,而前者则是一个Series(列表)。
通过属性方法选择
用法:raw_data.limit_infor,该方法的效果跟raw_data['limit_infor']是等同的。
通过loc方法选择
用法:raw_data.loc[:,'limit_infor']。loc方法也是通过列名标签来获取列的常用方法,通过对行和列的限制可以选择特定数据块、片和单个数据体。例如通过raw_data.loc[1:10,'limit_infor']选择该列第2到第11个值。
通过iloc方法选择
用法:raw_data.iloc[:,0]。iloc方法也可以实现选择列,跟loc的用法类似,都可以做灵活的数据选取。但iloc的初衷是用于选择行数据,并且选择是通过列索引实现,而非标签实现。
通过ix方法选择
用法:raw_data.ix[:,'limit_infor']或raw_data.ix[:,0]。ix方法可以看做是loc和iloc的结合体,并且由于它结合了二者的用法,在做列选取时即可使用索引值,也可以使用列名标签。因此是实用性最广的灵活选择方法。
综上来看,在选择方法时,以下是主要区别点:
- 如果单纯做全列选取,raw_data['limit_infor']和raw_data.limit_infor最常用。
- 如果要做多条件的灵活选取,使用ix则更加适合,其次选择loc和iloc方法。
第三部分 缺失值审查,目的是验证在第一部分中得到的关于price缺失的结论,同时再次确认下其他列的缺失情况。
na_cols = raw_data.isnull().any(axis=0) # 查看每一列是否具有缺失值
print ('{:*^60}'.format('NA Cols:'))
print (na_cols) # 查看具有缺失值的列
na_lines = raw_data.isnull().any(axis=1) # 查看每一行是否具有缺失值
print ('Total number of NA lines is: {0}'.format(na_lines.sum())) # 查看具有缺失值的行总记录数实现过程跟之前的章节基本一致,主要方法用途如下:
isnull():用于判断是否存在缺失值,存在则为True,否则为False。
any(axis=0):用于判断以列为单位的缺失值,如果一列中存在任何一个缺失值则为True。
any(axis=1):用于判断以行为单位的缺失值,如果一行中存在任何一个缺失值则为True
sum():用于对指定对象求和,True作为1、False作为0参与计算。上述代码执行后返回结果输出结果也验证了第一部分的结论(price有两条缺失数据),具体如下:
**************************NA Cols:**************************
limit_infor False
campaign_type False
campaign_level False
product_level False
resource_amount False
email_rate False
price True
discount_rate False
hour_resouces False
campaign_fee False
orders False
dtype: bool
Total number of NA lines is: 2第五部分 相关性分析,主要用来做回归的共线性问题检验。如果存在比较严重的线性问题则需要使用特定算法或做降维处理。
print ('{:*^60}'.format('Correlation Analyze:'))
short_name = ['li', 'ct', 'cl', 'pl', 'ra', 'er', 'price', 'dr', 'hr', 'cf', 'orders']
long_name = raw_data.columns
name_dict = dict(zip(long_name, short_name))
print (raw_data.corr().round(2).rename(index=name_dict, columns=name_dict)) # 输出所有输入特征变量以及预测变量的相关性矩阵
print (name_dict)该方法主要使用了pandas的corr()方法做所有特征变量的相关性分析,使用round(2) 保留2位小数。在输出时,由于原变量名称过长,因此这里使用rename方法对索引和列名做修改,先定义一个缩写列表,使用columns方法获取原始变量名,然后使用dict结合zip方法将两个列表组成字典。最后输出相关性矩阵和变量名对应信息如下:
********************Correlation Analyze:********************
li ct cl pl ra er price dr hr cf orders
li 1.00 -0.03 -0.08 -0.04 0.05 0.04 -0.02 0.00 0.01 -0.04 -0.02
ct -0.03 1.00 0.04 0.03 0.01 -0.01 -0.05 -0.01 0.06 0.06 0.06
cl -0.08 0.04 1.00 0.06 0.05 0.05 0.02 0.02 -0.52 0.26 0.05
pl -0.04 0.03 0.06 1.00 -0.12 -0.12 0.59 -0.04 -0.25 -0.23 -0.30
ra 0.05 0.01 0.05 -0.12 1.00 0.98 0.13 0.15 0.54 0.46 0.62
er 0.04 -0.01 0.05 -0.12 0.98 1.00 0.14 0.18 0.54 0.47 0.63
price -0.02 -0.05 0.02 0.59 0.13 0.14 1.00 0.25 -0.08 -0.11 -0.10
dr 0.00 -0.01 0.02 -0.04 0.15 0.18 0.25 1.00 0.17 0.19 0.23
hr 0.01 0.06 -0.52 -0.25 0.54 0.54 -0.08 0.17 1.00 0.32 0.66
cf -0.04 0.06 0.26 -0.23 0.46 0.47 -0.11 0.19 0.32 1.00 0.76
orders -0.02 0.06 0.05 -0.30 0.62 0.63 -0.10 0.23 0.66 0.76 1.00
{'campaign_type': 'ct', 'campaign_fee': 'cf', 'email_rate': 'er', 'hour_resouces': 'hr', 'price': 'price', 'campaign_level': 'cl', 'resource_amount': 'ra', 'limit_infor': 'li', 'discount_rate': 'dr', 'orders': 'orders', 'product_level': 'pl'}从相关性矩阵中发现,er('email_rate)和ra(resource_amount)具有非常高的相关性,相关系数达到0.98,通常意味着我们需要对此做处理,更多共线性的问题参见“3.7 解决运营数据的共线性问题”。
步骤4 数据预处理,包括异常值处理、分割数据集两部分。
第一部分 异常值处理。根据步骤3得到的结论,包括price中的缺失值、limit_infor中值域为10的记录以及campaign_fee为33380的记录都要做针对性处理。
sales_data = raw_data.fillna(raw_data['price'].mean()) # 缺失值替换为均值
# sales_data = raw_data.drop('email_rate',axis=1) # 丢弃缺失值
sales_data = sales_data[sales_data['limit_infor'].isin((0, 1))] # 只保留促销值为0和1的记录
sales_data['campaign_fee'] = sales_data['campaign_fee'].replace(33380, sales_data['campaign_fee'].mean()) # 将异常极大值替换为均值
print ('{:*^60}'.format('transformed data:'))
print (sales_data.describe().round(2).T.rename(index=name_dict)) # 打印处理完成数据基本描述性信息实现过程中,各个主要功能点如下:
- 通过raw_data['price'].mean()获得price列的均值,使用raw_data.fillna方法填充缺失值
- 对limit_infor中值域为10的记录做丢弃,使用isin((0,1)方法只获取值为0或1的数据记录
- campaign_fee值为33380的记录,使用replace方法将其替换为本列均值
- 打印输出时,使用describe()获得矩阵描述性统计结果,使用round(2)保留两位小数,使用.T做矩阵转置,使用rename(index=name_dict)将索引设置为缩写值。
上述过程完成后,打印输出结果如下:
*********************transformed data:**********************
count mean std min 25% 50% 75% max
li 730.0 0.03 0.17 0.00 0.00 0.00 0.00 1.00
ct 730.0 3.00 2.01 0.00 1.00 3.00 5.00 6.00
cl 730.0 0.68 0.47 0.00 0.00 1.00 1.00 1.00
pl 730.0 1.40 0.55 1.00 1.00 1.00 2.00 3.00
ra 730.0 4.95 1.84 1.00 3.00 5.00 7.00 9.00
er 730.0 0.47 0.16 0.08 0.34 0.48 0.61 0.84
price 730.0 162.82 14.26 100.00 152.00 163.00 173.00 197.00
dr 730.0 0.81 0.08 0.49 0.77 0.82 0.87 0.98
hr 730.0 848.51 687.03 2.00 315.25 717.00 1096.50 3410.00
cf 730.0 3655.61 1561.27 20.00 2495.00 3660.00 4783.25 6946.00
orders 730.0 4531.27 1933.85 22.00 3196.50 4566.00 6021.25 8714.00第二部分 分割数据集X和y
X = sales_data.ix[:, :-1] # 分割X
y = sales_data.ix[:, -1] # 分割y该部分使用前面介绍过的ix方法,对数据集做切分,形成输入自变量X和因变量y。上述过程中,我们提到了一个共线性的问题还没有解决,这个问题留在后面的模型优化里面具体解释。
步骤5模型最优化参数训练及检验,这是本案例实现的核心功能,目标是通过交叉检验自动得到最优结果时的模型参数以及模型对象。包括模型最优化参数训练及检验、获取最佳训练模型两部分。
第一部分 模型最优化参数训练及检验
model_gbr = GradientBoostingRegressor() # 建立GradientBoostingRegressor回归对象
parameters = {'loss': ['ls', 'lad', 'huber', 'quantile'],
'min_samples_leaf': [1, 2, 3, 4, 5],
'alpha': [0.1, 0.3, 0.6, 0.9]} # 定义要优化的参数信息
model_gs = GridSearchCV(estimator=model_gbr, param_grid=parameters, cv=5) # 建立交叉检验模型对象
model_gs.fit(X, y) # 训练交叉检验模型
print ('Best score is:', model_gs.best_score_) # 获得交叉检验模型得出的最优得分
print ('Best parameter is:', model_gs.best_params_) # 获得交叉检验模型得出的最优参数实现过程中的主要功能点如下:
先建立GradientBoostingRegressor模型对象,然后设置交叉检验时用到的模型可选参数,也就是GradientBoostingRegressor中的的调节参数,这里用到了三个参数:
- loss:loos是GradientBoostingRegressor的损失函数,主要包括四种ls、lad、huber、quantile。ls(Least squares),默认方法,是基于最小二乘法方法的基本方法,也是普通线性回归的基本方法;lad(Least absolute deviation)是用于回归的鲁棒损失函数,它可以降低异常值和数据噪音对回归模型的影响;huber是一个结合ls和lad的损失函数,它使用alpha来控制对异常值的灵敏度;quantile是分位数回归的损失函数,使用alpha来指定分位数用于预测间隔。
- min_samples_leaf:作为叶子节点的最小样本数。如果设置为数字,那么将指定对应数量的样本,如果设置为浮点数,则指定为总样本量的百分比。
- alpha:用于huber或quantile的调节参数。
这里设置了loss的所有可用损失函数,以字符串列表的形式定义;min_samples_leaf则是具体值作为定义,而非样本比例;alpha定义了常用的覆盖了0到1之间的间隔值。这里定义为列表或元组都可以,只要是能实现迭代读取即可。
再使用GridSearchCV建立交叉检验模型对象,设置参数如下:
- estimator:用来设置要训练的模型器,本示例中是集成回归对象model_gbr
- param_grid:用来设置要检验的所有参数列表值,本示例定义的值放在parameters中。该值是一个字典或者字典的列表。
- cv:用来定义交叉检验的方法。如果为空,则使用默认的3折交叉检验;如果为数字,则定义为交叉检验的次数,这里自定义为5可以获得更准确的结论;如果设置为一个对象,那么这是一个自定义的交叉检验方法;如果设置为可迭代的训练集和测试集对象,那么将循环读取分割好的数据集做交叉检验。我们在第五章的第二个案例中,就是用了自定义的交叉检验方法。
除此以外,GridSearchCV还提供了大量可供设置的参数,例如自定义交叉检验得分标准,可以通过scoring来定义,关于自定义交叉检验得分标准的内容,请参见第五章第二个案例中的get_best_model部分。
交叉检验模型对象创建完成之后,使用fit方法做训练,然后分别通过训练后的对象的best_score_和best_params_属性获取最佳结果的得分以及最佳参数组合。返回结果如下:
('Best score is:', 0.93144793519798985)
('Best parameter is:', {'alpha': 0.9, 'min_samples_leaf': 3, 'loss': 'huber'})程序通过交叉检验验证了所有可用的组合之后,得到了最优的得分以及参数值的组合。如果读者想要了解每次交叉检验的详细结果,可以使用model_gs.cv_results_获取,该方法可以获取所有组合下的运行时间、得分、排名等具体信息。
第二部分 获取最佳训练模型,我们已经知道了最佳模型的参数,下面通过设置最佳模型做数据集训练。
model_best = model_gs.best_estimator_ # 获得交叉检验模型得出的最优模型对象
model_best.fit(X, y) # 训练最优模型
plt.style.use("ggplot") # 应用ggplot自带样式库
plt.figure() # 建立画布对象
plt.plot(np.arange(X.shape[0]), y, label='true y') # 画出原始变量的曲线
plt.plot(np.arange(X.shape[0]), model_best.predict(X), label='predicted y') # 画出预测变量曲线
plt.legend(loc=0) # 设置图例位置
plt.show() # 展示图像我们并不打算“手动”将参数填充到模型对象中,而是直接通过交叉检验的训练对象的属性直接获取。使用model_gs.best_estimator_获得交叉检验模型得出的最优模型并建立对象model_best,对模型通过fit方法做训练。
为了验证效果,我们通过折线图来展示预测值与实际值的拟合程度:先使用Matplotlib自带的ggplot样式库,这样免去自己设置图形信息的步骤;然后建立画布并分别画出原始变量曲线和预测变量曲线,设置图例位置为自动调整之后展示图像,这些步骤之前都多次提到,图形结果如下:
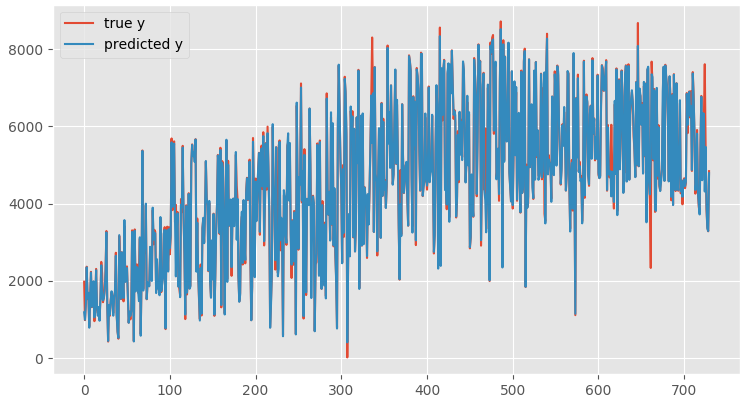
图6-6预测值与真实值对比
从图形输出结果看,预测值与真实值的拟合程度比较高。
步骤6 新数据集预测
业务方给出一个新的数据标准,即limit_infor=1,campaign_type=1,campaign_level=0,product_level=1,resource_amount=15,email_rate=0.5,price=177,discount_rate=0.66,hour_resouces=101,campaign_fee=798,针对该条数据做预测。
New_X = np.array([[1, 1, 0, 1, 15, 0.5, 177, 0.66, 101, 798]]) # 要预测的新数据记录
print ('{:*^60}'.format('Predicted orders:'))
print (model_best.predict(New_X).round(0)) # 打印输出预测值该数据定义为数组New_X,然后将该数据使用model_best(最佳模型对象)的predict方法做预测,结果不保留小数位数。结果如下:
*********************Predicted orders:**********************
[ 779.]由此得到预测的订单量为779.
提示 将浮点型数据保存为浮点型,可以使用round()方法,也可以使用int方法。以本次预测应用为例, model_best.predict(New_X)输出的原始结果为778.51283186。如果使用round(0)则得到四舍五入的结果779,如果实现int(model_best.predict(New_X))则输出结果为778,说明int方法是对数据做截取,只保留整数部分。二者对于预测结果的影响不大,但是对于过程中的预处理则会产生非常大的影响。
6.7.5 案例数据结论
本案例是一个应用型的模型示例,通过业务方给出的训练集以及预测自变量得到最终订单量预测值。
从交叉检验得到的最佳模型的得分为0.93,该得分由GradientBoostingRegressor的score产生,其值是预测的决定系数R2,该得分越高意味着自变量对因变量的解释能力越强,最高得分为1,5次交叉检验0.93的得分已经能够充分说明回归模型的预测能力比较强且效果相对稳定。
6.7.6 案例应用和部署
该模型给到业务部门后,业务部门针对该单品策划了一个跨品类活动,然后分别针对输入变量值落实运营要素。
对于本模型来讲,由于很多数据都是业务人工收集,难免这个过程会出现一些数据异常,而这些数据异常大多难以预料。例如:resource_amount和hour_resouces需要根据运营系统的记录做手动汇总整理,campaign_fee需要跟多个部门做沟通然后汇总多方来源。另外,也由于该模型每次运行的时间不长,并且总数据量也不大,因此每次人工运行以便应对临时性、突发性的数据问题。
6.7.7 案例注意点
本案例的应用核心是通过自动化优化方法,从众多指定的参数集合中通过交叉检验得到最优模型以及参数组合。该过程中有以下需要重点注意的内容:
q 本案例中的异常值比较多,异常值的处理必不可少,即使GradientBoostingRegressor的损失函数对异常值不敏感,通常也建议读者做预先处理。
q 虽然本案例是一个自动优化的实现思路,但参数值域还需要分析师人工指定,对于有固定值域的参数例如loss而言,这不会有什么影响,最多使用所有值域做训练优化;但对于有开放性值的参数而言,仍然是一个多次尝试的过程。例如min_samples_leaf笔者分别尝试了指定比例(浮点型)和整数型才找到相对较好的测试方案。
6.7.8 案例引申思考
问题一 本案例中,不同的自变量之间其实存在量纲的差异,针对这种情况是否需要做先对每一列做标准化然后再做回归分析?
问题二 本案例没有对具有非常高相关性的变量做任何处理,这是否得当?
笔者关于引申思考的想法
问题一 对于回归分析而言,是否做标准化取决于具体场景。在本案例中,回归分析的目的是做预测,因此无需做标准化;而如果要做特征重要性的分析,那么必须要做标准化。标准化的目的是去除量纲对于回归系数的影响,如果不做标准化,本案例中的因变量将主要受campaign_fee,即该变量系数的绝对值最大。
问题二 本案例应用的是集成方法,具体参数通过交叉检验得到的是使用huber损失函数做回归评估,它已经能够兼顾(一定程度上解决共线性)的问题。因为在应用GradientBoostingRegressor方法中,有一个参数learning_rate是用来通过正则化的方法控制梯度下降过程的步长,它通过收缩正常化(learning_rate <1.0)来提高模型性能。笔者可以在代码文件中取消65行的注释,该行代码会将email_rate列去掉,然后再做模型最优化评估会发现得分结果仍然是0.93(小数点后面几位会有差异,但已经非常不明显)。