作者:凌岸 终身学习者@数据分析&数据挖掘^Python爱好者社区专栏作者
知乎专栏:https://www.zhihu.com/people/yuan-fang-20-16
建模不能脱离商业环境和业务诉求。有时候数学上的最佳答案并不是商业上最佳选择。
——范若愚《大数据时代的商业建模》
建模之前的几个假设:
研究对象未来的行为模式与过去的相似;
社会政治经济的大环境基本不变。
Lending Club是全球最大的撮合借款人和投资人的线上金融平台,它利用互联网模式建立了一种比传统银行系统更有效率的、能够在借款人和投资人之间自由配置资本的机制。
经过1000多行的代码,我完成了构建lending club的评分卡模型。
文章大致分为下列几个阶段
好坏定义说明
样本概述和说明
输入变量和单变量探索以及部分数据字典
缺失值处理,同值化处理
筛选变量(基于随机森林和IV值)
最优分箱
初步模型结果
参数估计结果
初步评分卡结果
初步模型结果
模型的稳定性校验
最终模型结果
(一)好坏定义说明
要开发一个申请的评分卡,最重要的就是先定义好坏。也就是编码y变量,0和1 。
我们先要去了解一下Lending Club的大概情况:
http://www.360doc.com/content/15/0611/08/5473201_477300580.shtml
查看本次数据的y值如下:

得知lending club的贷款产品贷款期限在36期或者60期,也就是分期产品。
贷款金额普遍在1000$ - 40000$之间
其实我们看到很多同学在做这个lending club的分析或者建模的时候,对于好坏的分析太多不清晰,大部分人都是粗暴的直接分为好坏,而没有划分Indeterminate(不确定)。
根据行业经验,正常还款12期以上的借款人,逾期率会趋于稳定,我们用来定义好坏。
并且我们定义逾期30天以上的客户为坏客户。
Bad: Late (31-120 days) , Charged Off(坏账)
Indeterminate: Late (16-30 days) ,In Grace Period (处于宽限期)
Good: Current, Fully Paid(结清)
#########################
#定义好坏
#定义新函数 , 给出目标Y值
def coding(col, codeDict):
colCoded = pd.Series(col, copy=True)
for key, value in codeDict.items():
colCoded.replace(key, value, inplace=True)
return colCoded
#把贷款状态LoanStatus编码为逾期=1, 正常=0:
pd.value_counts(df["loan_status"])
df["loan_status"] = coding(df["loan_status"], {'Current':0,'Fully Paid':0,
'Late (31-120 days)':1,'Charged Off':1,
'Late (16-30 days)':2,'In Grace Period':2,'Default':2})
print( '\nAfter Coding:')
(二)样本概述和说明
表现窗口:在时间轴上从观察点向后推得的表现窗口,用来提取目标变量和进行表现排除。
观察窗口:从观察点向前推一段时间得到观察窗口,用来提取自变量信息和进行观察窗口排除,观察窗口一般长度通常为6-12个月。
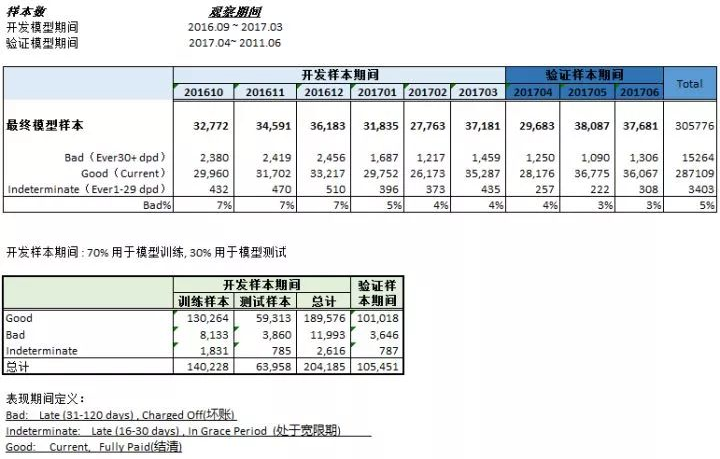
样本概述
我们开发的样本到目前为止全部到期,客户已经还款到了12个月。验证样本在未来3个月也会全部全部还款到12个月。
本次开发样本总共有204185条数据;验证样本数据有101018条数据,所以我们的数据量还是比较大的。
df.groupby('y').size()
'''
y
0.0 186091
1.0 11618
6.24%
'''
我们这里的数据,bad占比为6%多,数据属于不平衡样本。后期要做不平衡样本处理。
(三)输入变量和单变量探索以及部分数据字典
我们的数据里面有145个变量, 部分比较重要的变量及其解释如下。
由于本人英文水平和业务水平有限,部分变量可能翻译不准。
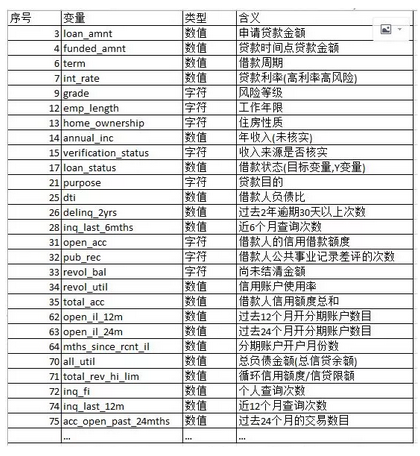
输入变量以及解释
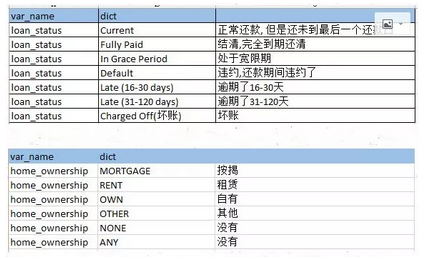
部分数据字典
部分变量如下:
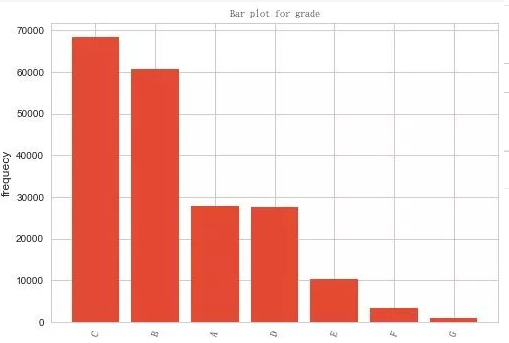
风险等级,可以看到BC两档中风险的申请的人最多。高风险的人基本很少。
部分变量如下:
风险等级,可以看到BC两档中风险的申请的人最多。高风险的人基本很少。
工作年限,看到大部分都是10年以上的;
年收入来源,三者比较相当,比如来源确定,不确定。
房产性质,按揭和租赁的最多。
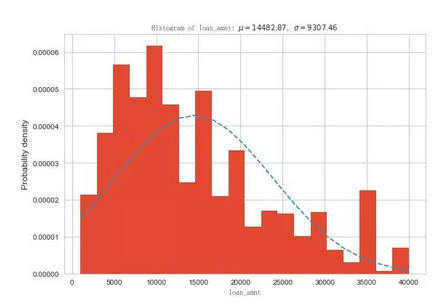
申请贷款金额;基本符合正态分布
总负债金额(总信贷金额),符合正态分布
贷款利率,基本符合正态分布
最近开设循环账户(信用卡)的月份数, 符合正态分布
过去24个的交易数目
(四)缺失值处理,同值化处理
1.删除一些无意义的变量
在进行缺失值处理之前,我会将一部分无意义的,或贷中,贷后变量删掉,以免向模型提前泄露信息。
'id','member_id', 变量为空值,本身对建模无意义。
'url','desc','zip_code','addr_state' 数据对建模无意义。
删除后,变量由145个变为139个。
2.同值化处理
变量的同值性如果一个变量大部分的观测都是相同的特征,那么这个特征或者输入变量就是无法用来区分目标时间,一般来说,临界点在90%。但是最终的结果还是应该基于业务来判断。
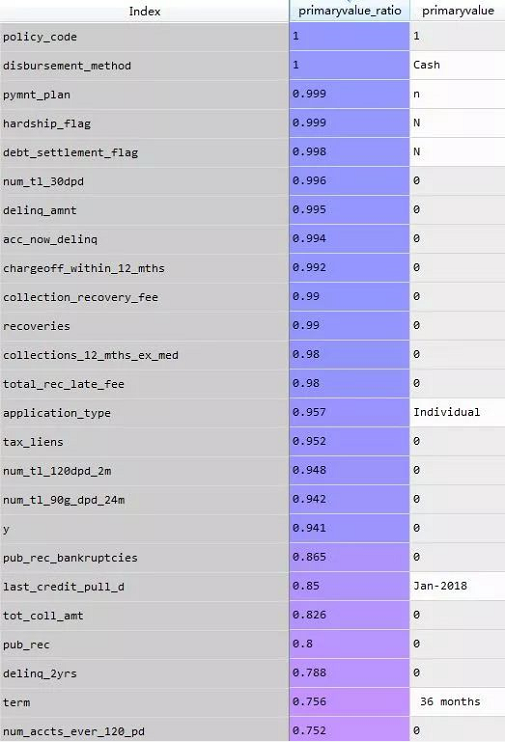
同值化占比
本次处理,我删掉了 临界值大于94.1%的变量。
变量由139变为122个。
3.缺失值处理
对于缺失值处理,各种资料给出很多方法,
包括填充法,插值法(拉格朗日插值法),机器学习算法拟合或预测缺失值。
我们这里采取对缺失值大于95.7%的变量进行删除。对于缺失值10%-80%的变量单独和Y变量编组,然后计算这几个变量的IV值,R语言这个时候很好的计算出了缺失值的IV值。我们看到这些变量除了mths_since_recent_inq和il_util,其他IV值都是小于0.01的,可以直接删除。
##针对缺失值进行IV值计算和分箱
null_data = df3[['mths_since_last_record','mths_since_recent_bc_dlq','mths_since_last_major_derog',
'mths_since_recent_revol_delinq','mths_since_last_delinq','il_util','mths_since_recent_inq','y']]
所以,查看缺失值情况,变量由122变为83个;其中几个40%-80%的缺失值其意义不大,无需进行missing编码,也就是归为一类。il_util缺失12%,该变量的缺失部分可以分类进入0,所以赋值为0。其他变量的缺失部分占比都非常小,所以我们对其缺失部分赋值为0。
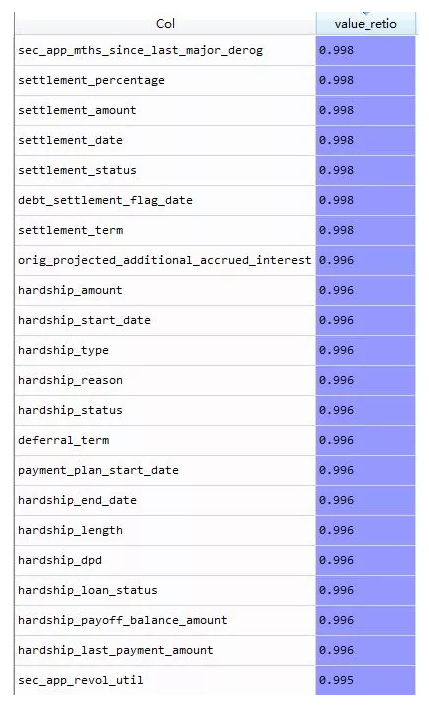
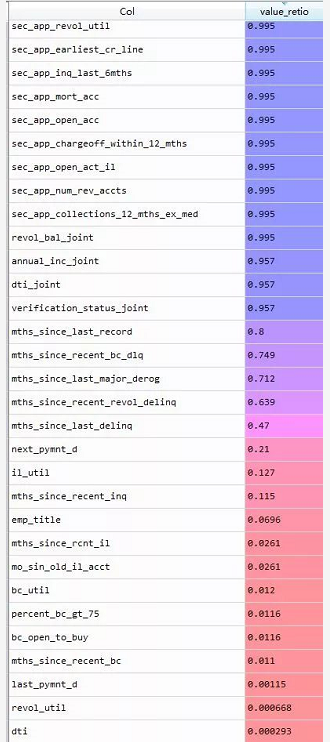
数据里面有一些变量的观测值不是数据值型,我们要做处理:
如:
##处理带有百分号的数据
df4['revol_util'] = df4['revol_util'].str.rstrip('%').astype('float')
df4['int_rate'] = df4['int_rate'].str.rstrip('%').astype('float')
df4['term'] = df4['term'].str.rstrip('months').astype('float')
##删掉一些无意义或者重复的变量,变量由83变为72个
##删除一些贷后的变量的,这些变量会向申请模型泄露信息
=============================================================================
# next_pymnt_d : 客户下一个还款时间,没有意义
# emp_title :数据分类太多,实用性不大
# last_pymnt_d :最后一个还款日期,无意义
# last_credit_pull_d :最近一个贷款的时间,没有意义
# sub_grade : 与grade重复,分类太多
# title: title与purpose的信息基本重复,数据分类太多
# issue_d : 放款时间,申请模型用不上
# earliest_cr_line : 贷款客户第一笔借款日期
# =============================================================================
'''
total_rec_prncp 已还本金
total_rec_int 已还利息
out_prncp 剩余未偿本金总额
last_pymnt_d 最后一个还款日
last_pymnt_amnt 最后还款金额
next_pymnt_d 下一个还款日
installment 每月分期金额
bc_open_to_buy 数据字典中未找到
percent_bc_gt_75 数据字典中未找到
tot_hi_cred_lim 无法译出真实意义
mths_since_recent_inq 数据字典中未找到
total_bc_limit 数据字典中未找到
'''
然后对字符型的数据进行编码:
mapping_dict = {"initial_list_status":
{"w": 0,"f": 1,},
"emp_length":
{"10+ years": 11,"9 years": 10,"8 years": 9,
"7 years": 8,"6 years": 7,"5 years": 6,"4 years":5,
"3 years": 4,"2 years": 3,"1 year": 2,"< 1 year": 1,
"n/a": 0},
"grade":
{"A": 0,"B": 1,"C": 2, "D": 3, "E": 4,"F": 5,"G": 6},
"verification_status":
{"Not Verified":0,"Source Verified":1,"Verified":2},
"purpose":
{"credit_card":0,"home_improvement":1,"debt_consolidation":2,
"other":3,"major_purchase":4,"medical":5,"small_business":6,
"car":7,"vacation":8,"moving":9, "house":10,
"renewable_energy":11,"wedding":12},
"home_ownership":
{"MORTGAGE":0,"ANY":1,"NONE":2,"OWN":3,"RENT":4}}
df6 = df5.replace(mapping_dict)
(五)筛选变量(基于随机森林和IV值)
为了创建评分卡,所以我们采用了计算WOE值,不对数据进行归一化,哑变量处理。
1.IV值筛选变量
分箱的方法有几种,包括等距分箱,等宽分箱,最优分箱等。
分箱的重要性及其优势
离散特征的增加和减少都很容易,易于模型的快速迭代;
稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
离散化后的特征对异常数据有很强的鲁棒性;
离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
可以将缺失作为独立的一类带入模型。
本次我在做分箱时候,采用了 等距分箱,基于卡方的最优分箱,基于R语言smbinning包进行最优分箱。最终手动调整分箱结果。

IV值的预测能力如下:
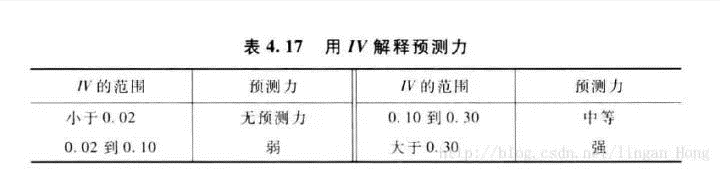
我先使用等距分箱对变量进行10等份处理,删除掉IV<0.02的变量;
IV保留大于0.02的变量,63个变量保留26个
### 利用IV值来删除不重要的特征
def filter_iv(data, group=10):
iv_value,all_iv_detail = iv.cal_iv(data, group=group)
##利用IV值,先删除掉IV值<0.02的特征
'''IV值小于0.02,变量的预测能力太弱'''
list_value = iv_value[iv_value.ori_IV <= 0.02].var_name
filter_data = iv_value[['var_name','ori_IV']].drop_duplicates()
print(filter_data)
new_list = list(set(list_value))
print('小于0.02的变量有:',len(new_list))
print(new_list)
#new_list.sort(key = list_value.index)
drop_list = new_list
new_data = data.drop(drop_list, axis = 1)
return new_data, iv_value
var_name ori_IV
group_num
0.0 int_rate 0.503969
0.0 grade 0.477303
0.0 verification_status 0.081455
0.0 acc_open_past_24mths 0.073015
0.0 inq_last_12m 0.064279
0.0 inq_last_6mths 0.063781
0.0 num_tl_op_past_12m 0.061375
0.0 mths_since_rcnt_il 0.046776
0.0 open_il_12m 0.045933
0.0 open_rv_24m 0.045544
0.0 open_il_24m 0.044963
0.0 il_util 0.043836
0.0 mo_sin_rcnt_tl 0.043547
0.0 open_acc_6m 0.041515
0.0 dti 0.039186
0.0 all_util 0.036719
0.0 inq_fi 0.034688
0.0 mo_sin_rcnt_rev_tl_op 0.031869
0.0 open_rv_12m 0.030429
0.0 total_rec_int 0.028272
0.0 mths_since_recent_bc 0.027211
0.0 home_ownership 0.026728
0.0 tot_cur_bal 0.025399
0.0 mort_acc 0.023417
0.0 avg_cur_bal 0.023055
0.0 total_rev_hi_lim 0.020263
0.0 mo_sin_old_rev_tl_op 0.020119
0.0 funded_amnt 0.018039
0.0 loan_amnt 0.018039
0.0 initial_list_status 0.017818
... ... ...
0.0 annual_inc 0.014477
0.0 purpose 0.013933
0.0 revol_util 0.013595
0.0 emp_length 0.012634
0.0 mo_sin_old_il_acct 0.010858
0.0 max_bal_bc 0.008319
0.0 total_bal_il 0.005845
0.0 total_cu_tl 0.004788
0.0 revol_bal 0.004608
0.0 open_act_il 0.004265
0.0 pub_rec 0.004245
0.0 num_actv_rev_tl 0.004183
0.0 num_actv_bc_tl 0.003610
0.0 total_bal_ex_mort 0.003407
0.0 pub_rec_bankruptcies 0.003173
0.0 delinq_2yrs 0.003014
0.0 num_rev_tl_bal_gt_0 0.002778
0.0 num_accts_ever_120_pd 0.002239
0.0 total_il_high_credit_limit 0.002144
0.0 num_bc_tl 0.001969
0.0 num_sats 0.001968
0.0 open_acc 0.001959
0.0 num_bc_sats 0.001590
0.0 num_il_tl 0.001559
0.0 num_tl_90g_dpd_24m 0.001533
0.0 pct_tl_nvr_dlq 0.001360
0.0 num_rev_accts 0.001337
0.0 total_acc 0.001138
0.0 num_op_rev_tl 0.001016
0.0 tot_coll_amt 0.000925
[62 rows x 2 columns]
小于0.02的变量有: 35
['revol_bal', 'num_il_tl', 'num_bc_tl', 'num_actv_rev_tl', 'funded_amnt', 'max_bal_bc', 'revol_util', 'num_bc_sats', 'num_sats', 'tot_coll_amt', 'num_accts_ever_120_pd', 'open_act_il', 'term', 'total_cu_tl', 'purpose', 'num_rev_tl_bal_gt_0', 'pct_tl_nvr_dlq', 'emp_length', 'mo_sin_old_il_acct', 'num_rev_accts', 'pub_rec', 'delinq_2yrs', 'pub_rec_bankruptcies', 'open_acc', 'loan_amnt', 'total_bal_ex_mort', 'total_il_high_credit_limit', 'num_tl_90g_dpd_24m', 'num_actv_bc_tl', 'bc_util', 'num_op_rev_tl', 'annual_inc', 'total_acc', 'total_bal_il', 'initial_list_status']
然后对数据按照IV大小顺序进行排序,以便于删除相关性较高里面IV值低的变量。
逻辑回归对于相关性比较高的变量很敏感,所以要计算相关性。
皮尔森系数绘图,观察多重共线的变量多变量分析,保留相关性低于阈值0.6的变量。对产生的相关系数矩阵进行比较,并删除IV比较小的变量,由26个变量,保留20个变量。
回归分析中有一个假设,就是模型的变量中输入的变量,即方程
y = a0 + a1x1 +a2x2 + ...anxn,
这里的系数都是需要独立不相关的。皮尔森系数>0.75(或<-0.75),在这里,我们采用threshold = 0.60。
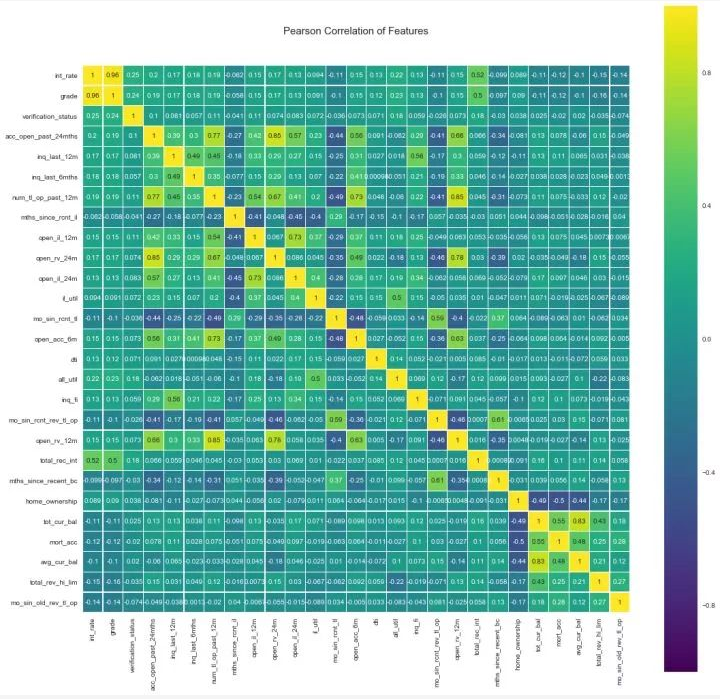
变量之间的相关系数
上图中,黄色部分就是正相关性比较高的,深紫色是负相关性比较高。
删除了相关性高于阈值的变量,再做可视化:
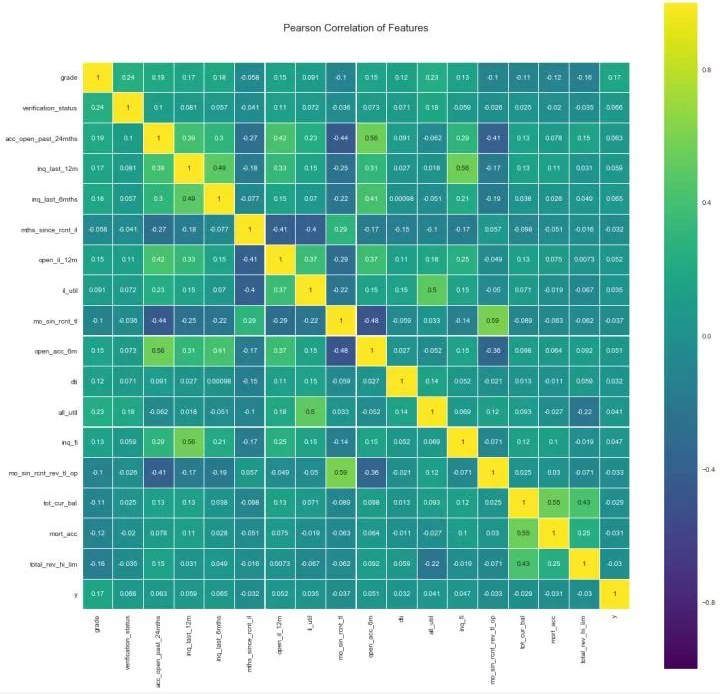
变量之间的相关系数
2.随机森林筛选数据
机器学习里面有很多特征选择的方法(变量筛选,如递归消除算法来暴力选择特征,顶层特征选择算法;稳定性选择,顶层特征选择算法),这里我也会做一下基于随机森林的特征选择,然后作为IV值筛选之后的一个参考和筛选。
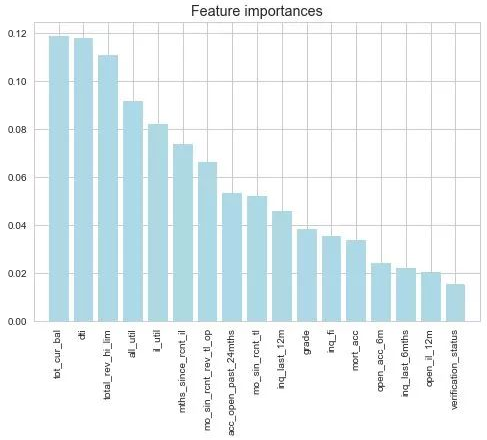
随机森林拟合后的变量重要性
3.最优分箱结果
分箱结果如下:
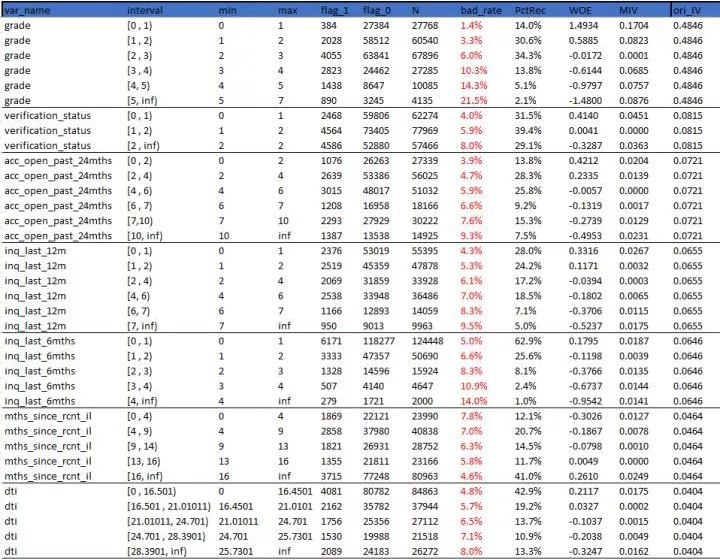
最优分箱
(六)初步模型结果
我们要将iv中分组的WOE值根据区间大小回填到原始的数据样本中,做逻辑回归拟合。
并做膨胀因子检验,一般大小5或者10的变量是要删除掉的。
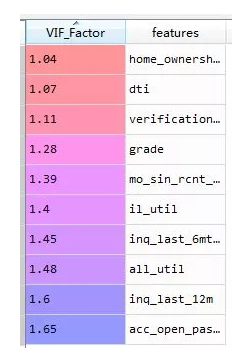
VIF,膨胀因子
建模是一个多次迭代的过程,我们对模型做了多次迭代,结果如下:
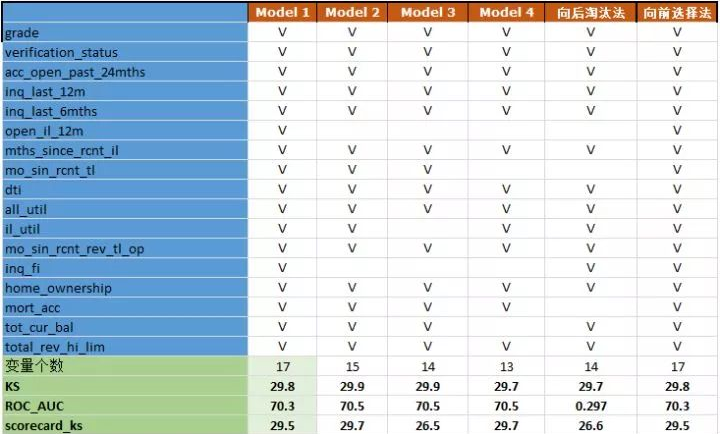
每一次删除掉一些变量,是他们的回归系数较小而删除,因为回归系数较小,评分卡最后几乎没有什么区分能力,这样的变量对模型的贡献度比较低。
我们这里的数据,bad占比为6%多,数据属于不平衡样本。
我们会将数据按照70%和30%随机划分为训练集和测试集,然后使用下面几种方法来计算最终的各项指标的结果。
baseline模型,不划分训练集和测试集,一般全变量建模,参数使用class_weight ='balanced'。
划分训练集和测试集,使用class_weight ='balanced',对训练集和拟合,做网格搜索算法求出最佳参数,然后对测试集进行验证。
baseline模型,不划分训练集和测试集,一般全变量建模,使用SMOTE算法过采样。
划分训练集和测试集,使用使用SMOTE算法过采样。,对训练集和拟合,对测试集进行验证。
向后淘汰法和向前选择法。
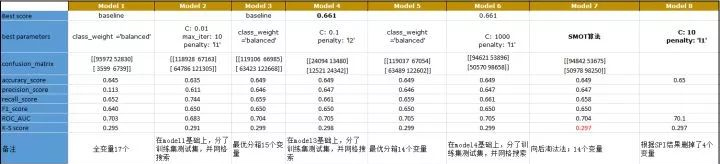
对此,我们还有向后淘汰法和向前选择法。结果如下:
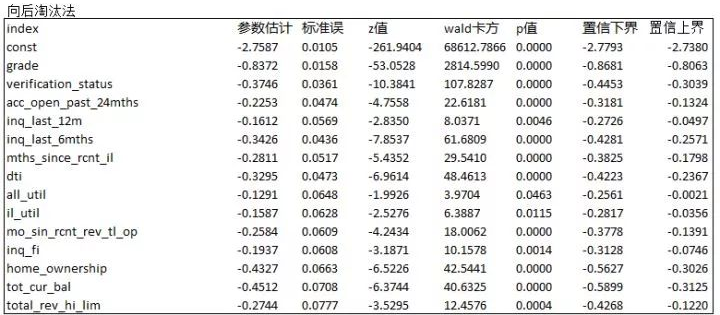
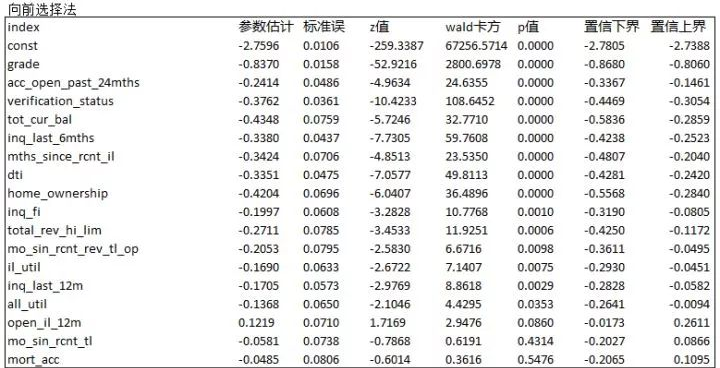

使用了多种方法以后,我们给出了最终的结果。保留14个变量,KS = 29.7。
Test set accuracy score: 0.64758
precision recall f1-score support
0.0 0.65 0.64 0.65 186091
1.0 0.65 0.65 0.65 186091
avg / total 0.65 0.65 0.65 372182
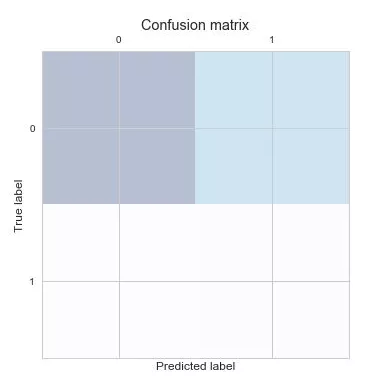
The confusion_matrix is:
[[119368 66723]
[ 64443 121648]]
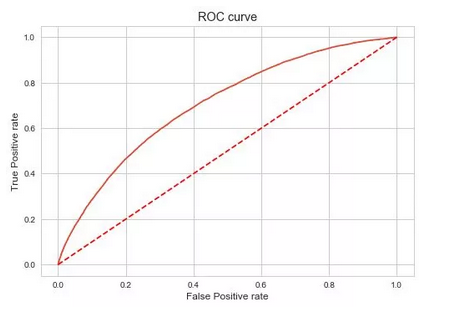
accuracy_score 0.647575648473
precision_score 0.645789426186
recall_score 0.653701683585
ROC_AUC is 0.702947965916
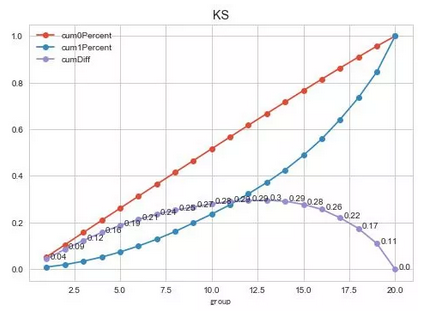
K-S score 0.295828385037
(七)参数估计结果
每次迭代都保存下面的记录。回归系数和截图。
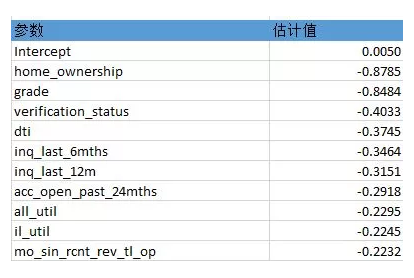
(八)初步评分卡结果

接下来,我们代入WOE值,截距和系数,就可以算出评分卡了。
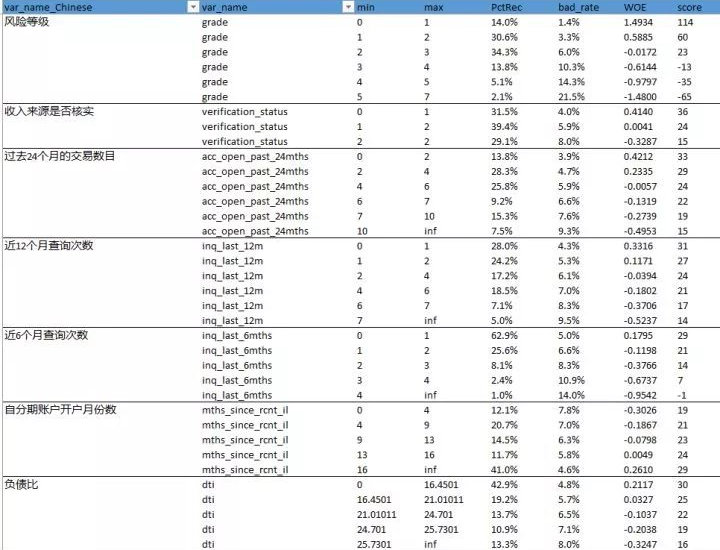
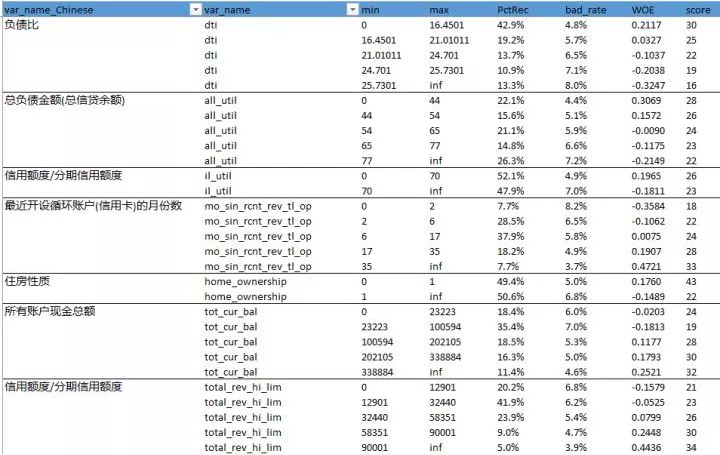
评分卡
(九)初步模型结果
我们将每个样本的分数都计算出来,然后计算出开发样本的KS = 29.7%
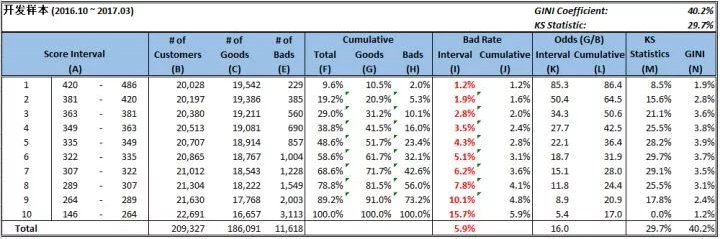
使用上述的评分卡结果去计算出KS = 31.0%,说明我们的模型基本准确,还有就是2017.4-2017-06的数据,很多人还款还没有到12期。
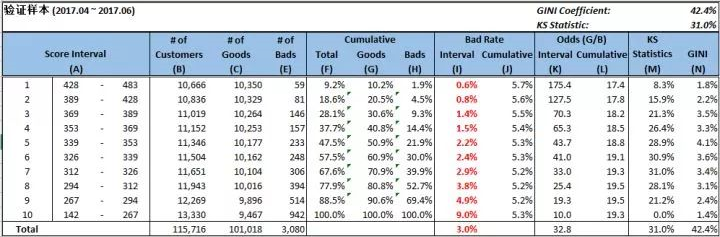
在开发样本数上分数分布如下:
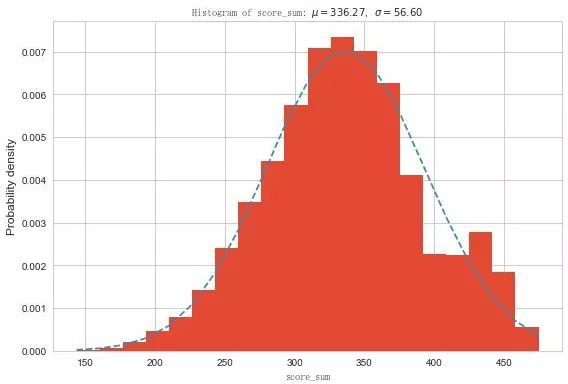
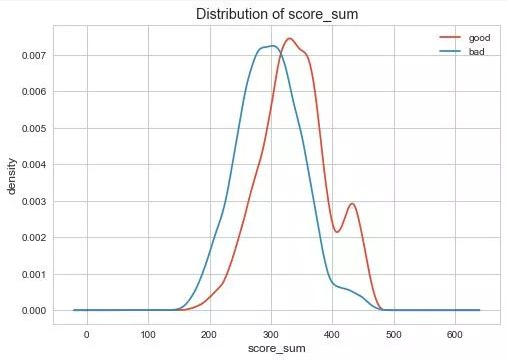
分数符合正态分布。以及下列的概率密度函数,看得出好坏是有一部分是分离的。
(十)模型的稳定性校验
我们要计算每个变量的SPI指标,校验数据在验证集上的表现差异。


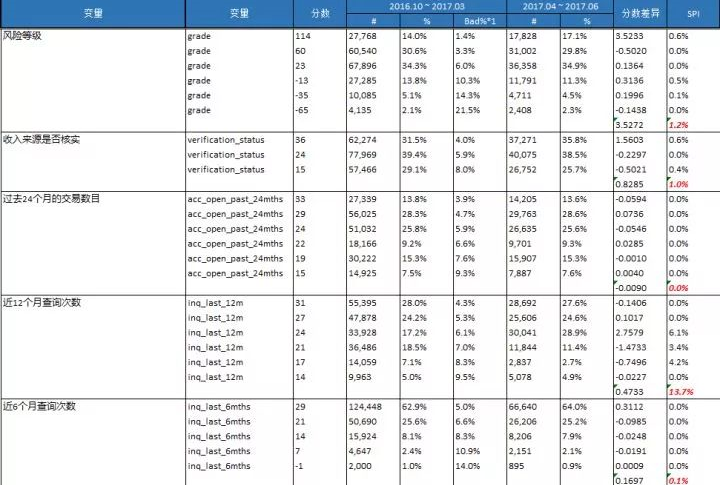
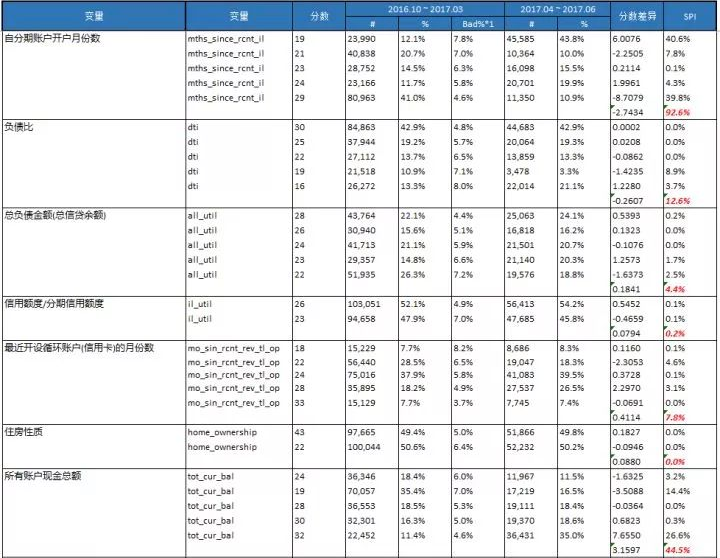

mths_since_rcnt_il ,tot_cur_bal ,total_rev_hi_lim这三个变量的SPI >25%
其中有三个变量SPI值>25%,我们需要重新判断模型。我采取的是直接删除这3个变量。
(十一)最终模型结果
删除SPI>0.25的三个变量,然后再重新按照上述的步骤计算一遍最终的结果如下:
验证样本KS = 30.8% 。
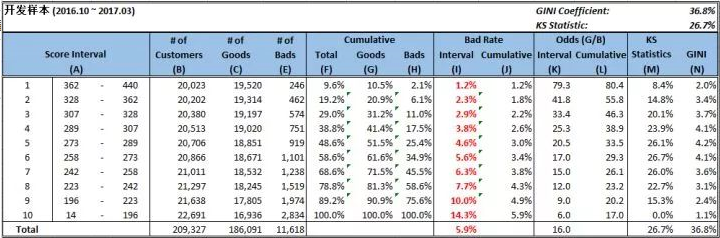
开发样本结果
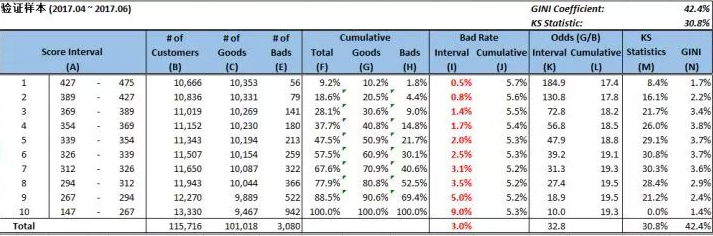
验证样本结果
由于本人水平有限,文章不可避免有错误,还请大佬们指摘。
喜欢的话点个赞哈哈哈。转载文章请注明出处。
参考资料
[1]:《SAS开发经典案例解析》(杨驰然)
[2]:《大数据时代的商业建模》(范若愚)
[3]:《Python数据分析与挖掘实战》(张良均)
Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战免费学习视频。

