作者:菜鸟分析
个人介绍:一个痴迷于Python语言的业余程序猿,未来的理想是能够与一群痴迷于Python语言的程序猿改变世界
知乎专栏: https://zhuanlan.zhihu.com/c_149865214
专栏介绍:恋习Python|因痴恋Python而起,因学习Python而聚,与大家一起疯狂练习Python代码
在日常工作或学习中,经常会遇到这样的无奈:
“小任,你把这个PDF中的文件码出来发我”
倒霉,2M的PDF12点也完不了啊!

很多时候在学习时发现许多文档都是PDF格式,PDF格式却不利于学习使用,因此需要将PDF转换为Word文件,但或许你从网上下载了很多软件,但只能转换前五页(如WPS等),要不就是需要收费,那有没有免费的转换软件呢?
so,菜鸟分析给各位带来了一个免费简单快速的方法,手把手教你用Python批量处理PDF格式文件,获取自己想要的内容,存为word形式。
在实现PDF转Word功能之前,我们需要一个python的编写和运行环境,同时安装好相关的依赖包。 对于python环境,我们推荐使用PyCharm。 在本地电脑环境,anaconda提供了非常便利的安装和部署。
PDF转Word功能所需的依赖包如下:
PDFParser(文档分析器),PDFDocument(文档对象),PDFResourceManager(资源管理器),PDFPageInterpreter(解释器),PDFPageAggregator(聚合器),LAParams(参数分析器)
一、前期准备工作
说明:菜鸟分析是在Windows7下使用python最新的3.6版本
1.安装pdfminer3k模块
安装anaconda后,直接可以通过pip安装

2.若安装不成功,可以试试下面方法
首先下载pdfminer3k:https://pypi.python.org/pypi/pdfminer3k;然后安装pdfminer
将下载好的pdfminer3k解压到D:或其他合适的盘符,通过win+r 打开运行窗口,输入cmd;
输入D:切换到D盘,cd pdfminer3k(pdf解压的文件夹),输入setup.py install安装软件。
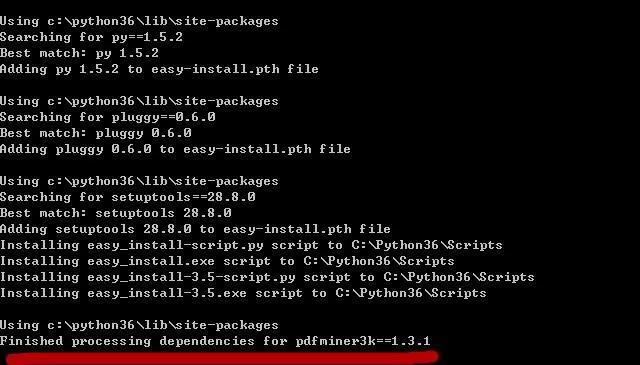
最终显示Finished,则代表成功
二、代码实操
导入相关包
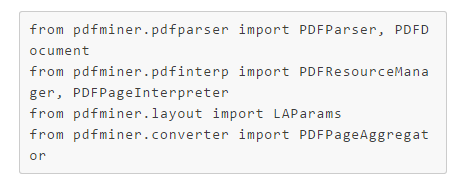
整体思路为:构造文档对象,解析文档对象,提取所需内容

构造文档对象
构造解释器
2.导入需要解析的PDF文件
将所需解析的文件与执行代码放到同一个目录下,如图:

test.pdf内容
3.具体代码如下:


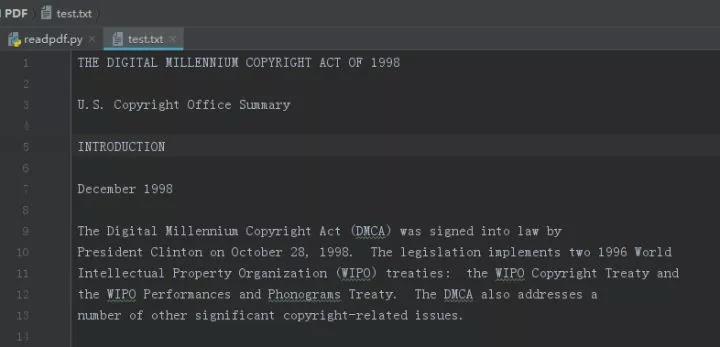
最终得到的test.txt结果如下:
结束:对于Python批量PDF转Word的操作介绍就到此,本文仅仅作为一种运用库展示代码编写过程,具体技术还需要有兴趣的朋友,与我一起讨论专研,互相学习进步。
Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战免费学习视频。

