作者:宅必备
一个会写Python的Oracle DBA
个人公众号:宅必备
作者其他文章:
[Python程序]利用微信企业号发送报警信息
好久没更新Python相关的内容了,这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分。
第一节我们介绍如何爬取静态网页
静态网页指的是网页的内容不是通过js动态加载出来的
我们可以直接使用一些开发者工具查看
这里我采用谷歌浏览器的开发者工具
开发环境
操作系统:windows 10
Python版本 :3.6
爬取网页模块:requests
分析网页模块:Beautiful Soup 4
模块安装
pip3 install requests
pip3 install beautifulsoup4
网页分析
我们使用炉石传说的页面来开始分析
https://www.douyu.com/directory/game/How
我们可以通过左上角的箭头来定位网页内容对应的源
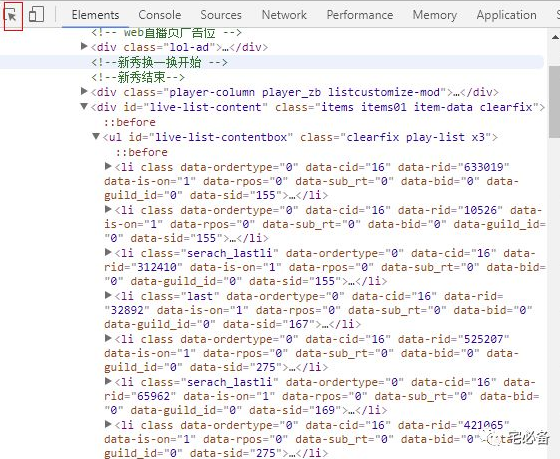

从上面我们可以看出单个直播的信息都在li标签下面,包括:
代码介绍
这里逐行介绍代码
1. import相关的模块
import requests
from bs4 import BeautifulSoup
2. 使用request模块打开并获取网页内容
verify=False 在打开https网页时使用
url='HTTPs://www.douyu.com/directory/game/'+douyugame
r = requests.get(url,verify=False)
content=r.content
3. 使用bs4格式化获取的网页
这时就可以使用bs4的功能来处理网页了
soup = BeautifulSoup(content,"lxml")
4. 获取所有li标签
这里获取所有具有data-cid属性的li标签
live_list=soup.find_all('li',attrs = {'data-cid' : True})
5.循环获取到li标签,然后提取需要的信息
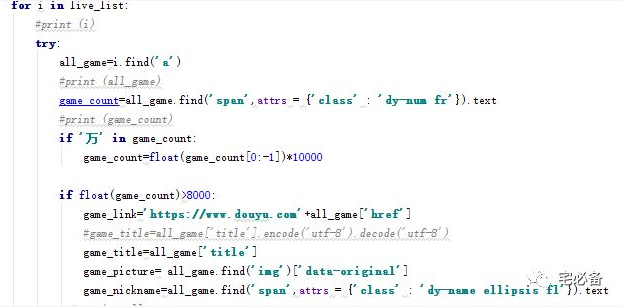
我们这里只提取在线人数大于8000的直播间
game_count=all_game.find('span',attrs = {'class' : 'dy-num fr'}).text
代表查找一个span标签,其class属性值为dy-num fr,然后获取它的内容
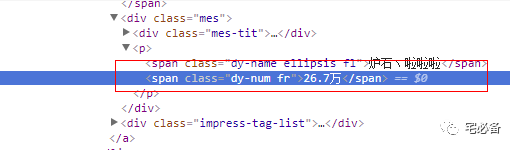
game_link='https://www.douyu.com'+all_game['href']
代表获取a标签中href属性的值
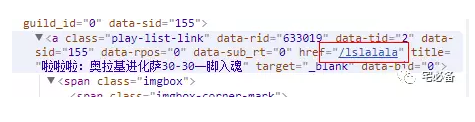
剩下的同理
6. 最后将获取到的信息放入字典中

这时我们可以将结果存入数据库中供查看,这里就不多说了
执行结果

源码位置
源码请访问我的github主页
https://github.com/bsbforever/spider/blob/master/static_web.py
Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战免费学习视频。

