
# 前几章设计到的数据都是整理好的数据框,可以直接输入到ggplot(),qplot()中
# 但实际数据并不会这么理想,通常需要经过整理和变换才能使用
# 9.1 如何用plyr包实现ggplot2内部的统计变换
# 9.2 时间序列图和平行坐标图里很有用的长数据
# 9.3 如何用R对象作图(而不是数据框),以及线性模型诊断
9.1 plyr包简介
# ddply()函数能够同时在数据的多个子集上作统计汇总
# 该函数能够根据行的取值,吧数据框分解成几个子集
# 分别把各个子集输入某个函数,最后把结果综合在一个数据框内
# ddply(.data,.variables,.fun,...)
# .data 是用来作图的数据
# .variables 是对数据取子集的分组变量,形式是 .(var1,var2)
# .fun 是要在各子集上运行的统计汇总函数
# subset() 用来对数据取子集的函数
library(ggplot2)
library(plyr)
# 选取各个颜色里最小的钻石
ddply(diamonds,.(color),subset,carat == min(carat))
# 选取最小的两颗钻石
ddply(diamonds,.(color),subset,order(carat) <= 2)
# 选取每组里大小为前1% 的钻石
ddply(diamonds,.(color),subset,carat > quantile(carat,0.99))
# 选出所有比组平均值大的钻石
ddply(diamonds,.(color),subset,price > mean(price))
# transform() 用来进行数据变换
# 与ddply()一起可以计算分组统计量,例如各组的标准差
# 把每个颜色组里钻石的价格标准化,使其均值为0,方差为1 (scale,标准化函数)
ddply(diamonds,.(color),transform,price = scale(price))
# 减去组均值
ddply(diamonds,.(color),transform,price = price - mean(price))
# colwise() 用来向量化一个普通函数
# 能把原本只接受向量输入的函数变成可以接受数据框输入的函数
# 要注意colwise()返回的是一个新的函数而不是函数运行结果
# 下面例子中的函数 nmissing() 计算向量里缺失值的数目
nmissing <- function(x) sum(is.na(x))
nmissing(msleep$name)
nmissing(msleep$brainwt)
# 使用colwise()向量化
nmissing_df <- colwise(nmissing)
# 计算整个数据框中 各列的缺失值数目
nmissing_df(msleep)
# 便捷的方法
colwise(nmissing)(msleep)
# 各列缺失值结果
name genus vore order conservation sleep_total sleep_rem sleep_cycle awake brainwt bodywt
1 0 0 7 0 29 0 22 51 0 27 0
# numcolwise()是一个特殊版本,功能类似。
# 但值对数值类型的列操作
# 例如,numcolwise(median)对每个数值类型的列计算中位数
# 相应地 catcolwise(),只对分类类型的列操作
msleep2 <- msleep[,-6]
numcolwise(median)(msleep2,na.rm = T)
sleep_rem sleep_cycle awake brainwt bodywt
1 1.5 0.3333333 13.9 0.0124 1.67
numcolwise(quantile)(msleep2,na.rm = T)
sleep_rem sleep_cycle awake brainwt bodywt
1 0.1 0.1166667 4.10 0.00014 0.005
2 0.9 0.1833333 10.25 0.00290 0.174
3 1.5 0.3333333 13.90 0.01240 1.670
4 2.4 0.5791667 16.15 0.12550 41.750
5 6.6 1.5000000 22.10 5.71200 6654.000
numcolwise(quantile)(msleep2,probs = c(0.25,0.75),na.rm = T)
sleep_rem sleep_cycle awake brainwt bodywt
1 0.9 0.1833333 10.25 0.0029 0.174
2 2.4 0.5791667 16.15 0.1255 41.750
# 以上这些函数与ddply一起可以对数据进行各种分组统计
ddply(msleep2,.(vore),numcolwise(median),na.rm = T)
vore sleep_rem sleep_cycle awake brainwt bodywt
1 carni 1.95 0.3833333 13.6 0.044500 20.490
2 herbi 0.95 0.2166667 13.7 0.012285 1.225
3 insecti 3.00 0.1666667 5.9 0.001200 0.075
4 omni 1.85 0.5000000 14.1 0.006600 0.950
5 <NA> 2.00 0.1833333 13.4 0.003000 0.122
ddply(msleep2,.(vore),numcolwise(mean),na.rm = T)
vore sleep_rem sleep_cycle awake brainwt bodywt
1 carni 2.290000 0.3733333 13.62632 0.07925556 90.75111
2 herbi 1.366667 0.4180556 14.49062 0.62159750 366.87725
3 insecti 3.525000 0.1611111 9.06000 0.02155000 12.92160
4 omni 1.955556 0.5924242 13.07500 0.14573118 12.71800
5 <NA> 1.880000 0.1833333 13.81429 0.00762600 0.85800
9.1.1 拟合多个模型
# 本节演示stat_smooth生成平滑数据的过程
# 平滑数据--指用平滑函数得到的预测值
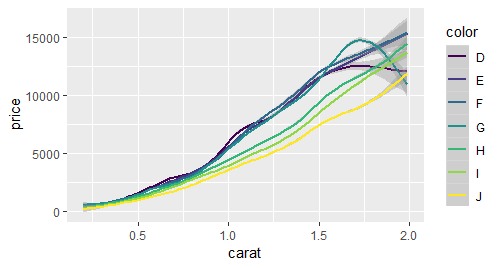
qplot(carat,price,data = diamonds,geom = "smooth",colour = color)
dense <- subset(diamonds,carat < 2)
qplot(carat,price,data = dense,geom = "smooth",colour = color,fullrange = T)

# 如何用plyr生成一摸一样的图?
# 通过stat_smooth()的文档,看到
# 对于大数据,用的是gam(y s(x,bs = "cs"))
library(mgcv)
# 创建自己的smooth方法
smooth <- function(df) {
mod <- gam(price ~ s(carat,bs = "cs"),data = df)
grid <- data.frame(carat = seq(0.2,2,length = 50))
pred <- predict(mod,grid,se = T)
grid$price <- pred$fit
grid$se <- pred$se.fit
grid
}
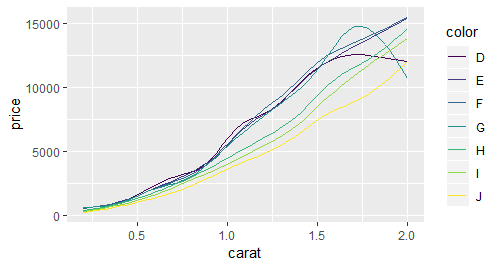
# 通过ddply对 color分组,并分组进行自定义的smooth操作
smoothes <- ddply(dense,.(color),smooth)
# 绘制线图
qplot(carat,price,data = smoothes,colour = color,geom = "line")
# 增加误差范围
qplot(carat,price,data = smoothes,colour = color,geom = "smooth",
ymax = price + 2*se,ymin = price - 2*se)

9.2 把数据化“宽”为“长”
# ggplot2进行数据分组时必须根据行,而不能根据列。
# 因而需要将数据从“宽”变成“长”
# 本节实用reshape2 包中的melt()函数,它有三个参数
# data:待变形的原数据
# id.vars:依旧放在列上、位置保持不变的变量
# measure.vars:需要被放进同一列的变量
9.2.1 多重时间序列
# 一种方法是:画图时把两个变量放在两个不同的图层上
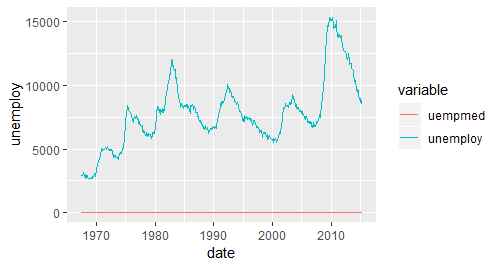
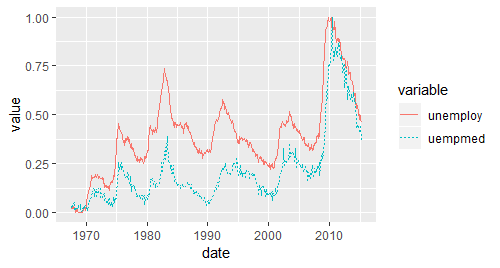
ggplot(economics,aes(date)) + geom_line(aes(y = unemploy,colour = "unemploy")) +
geom_line(aes(y = uempmed,colour = "uempmed")) +
scale_colour_hue("variable")# 另一种方法是:把数据变成一个“长”格式,然后再可视化
library(reshape2)
emp <- melt(economics,id = "date",measure = c("unemploy","uempmed"))
head(emp)
qplot(date,value,data = emp,geom = "line",colour = variable)
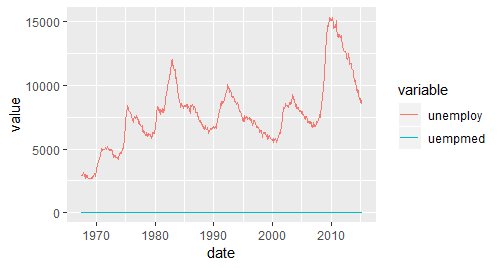
# 两个方法画出来的图是一样的。
# 但存在一个共同的问题:两个变量取值差异太大,uempemed变量变成了图形底下一条平坦的线
# ggplot2有两个比较直观的改进方法:把数据标度调整到相同的范围或使用自由标度的分面
# 把数据调整到相同的范围
# (x - min(x))/ (max(x) - min(x)) 0~1标准化,将数据调整到0~1这个相同的范围
range01 <- function(x){
rng <- range(x,na.rm = T)
(x - rng[1])/diff(rng)
}
emp2 <- ddply(emp,.(variable),transform,value = range01(value))
head(emp2)
qplot(date,value,data = emp2,geom = "line",
colour = variable,linetype = variable)
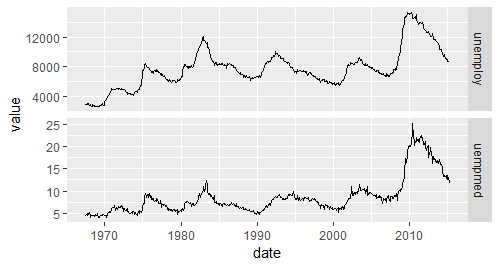
# 使用自由标度的分面
qplot(date,value,data = emp,geom = "line") +
facet_grid(variable ~ .,scales = "free_y")
9.2.2 平行坐标图
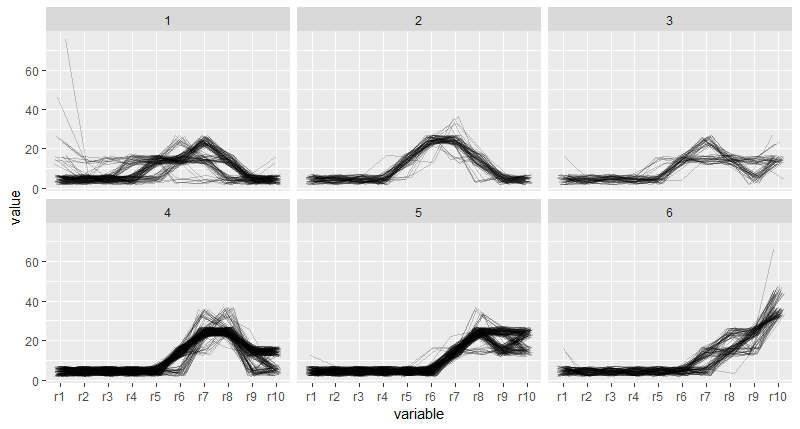
# 同样的方法能把原数据化为“长”数据,然后画出平行坐标图
# 下面的平行坐标图用的是840部电影的用户评分数据
head(movies)
popular <- subset(movies,votes > 1e4)
ratings <- popular[,7:16] # r1~r10 分值:1~10分
ratings$.row <- rownames(ratings)
head(ratings)
molten <- melt(ratings,id = ".row")
head(molten)
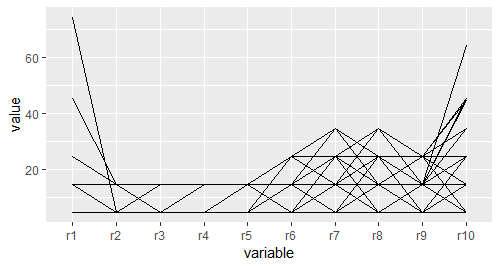
# 数据整理完毕后,以variables为x轴,value为y轴,.row分组,画折线,就得到了平行坐标图
pcp <- ggplot(molten,aes(variable,value,group = .row))
pcp + geom_line()
pcp + geom_line(colour = "black",alpha = 1/20)
jit <- position_jitter(width = 0.25,height = 2.5)
pcp + geom_line(position = jit)
pcp + geom_line(colour = "black",alpha = 1/20,position = "jitter")
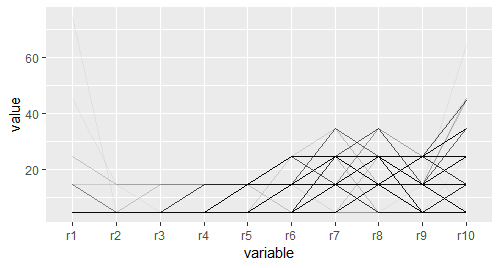
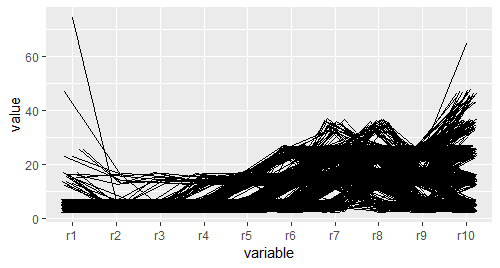
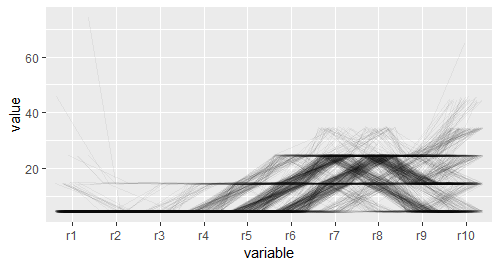
# 结果并不理想,大量的线条使图形的细节看不清,很难得到可靠的结论
# 为了更清楚的观察电影得分规律,我们进行聚类分析,使投票模式相近的被分为一类
# 使用kmeans把电影分成6类,再把每组的均值单独画在一张图上作为补充
cl <- kmeans(ratings[1:10],6)
head(popular)
head(ratings)
ratings$cluster <- reorder(factor(cl$cluster),popular$rating)
levels(ratings$cluster) <- seq_along(levels(ratings$cluster))
molten <- melt(ratings,id = c(".row","cluster"))
head(molten)# 使用平行坐标图展示各类数据,全数据
pcp_cl <- ggplot(molten,aes(variable,value,group = .row,colour = cluster))
pcp_cl + geom_line(position = "jitter",alpha = 1/5)
# 使用不同分类的均值作图
pcp_cl + stat_summary(aes(group = cluster),fun.y = mean,geom = "line")
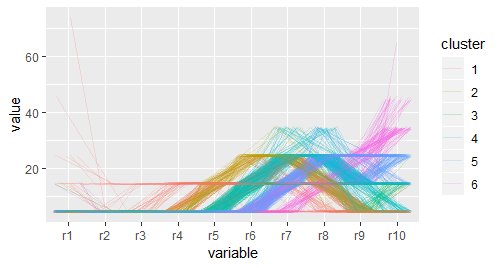
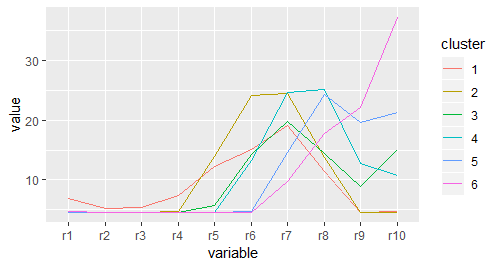
# 可以很好的看出 类之间的差异,但不能看出聚类效果好不好
# 使用faceting把每类数据画在单独的图内,查看聚类效果
pcp_cl + geom_line(position = jit,colour = "black",alpha = 1/5) +
facet_wrap(~ cluster)
9.3 ggplot() 方法
# ggplot() 是一个泛型函数,能根据不同的数据调用不同的方法
# 最常见的数据类型是数据框,所以本章一直以数据框为例
# ggplot()函数也可以接收其他数据类型,但是具体实现方法上有着本质的不同
# ggplot2只提供作图所需的工具
# ggplot2 需要借助fortify()来完成整个过程
# fortify() 能接收一个模型或对象,以及一个可选的原始数据作为第二参数
# 然后把它变成能输入到ggplot2的形式,比如数据框
# ggplot2最重要的理念之一就是数据变形和图形展示尽可能分开进行
# qplot() 只是把ggplot()进行了简单的包装,所以qplot()也可以接受不同类型的输入
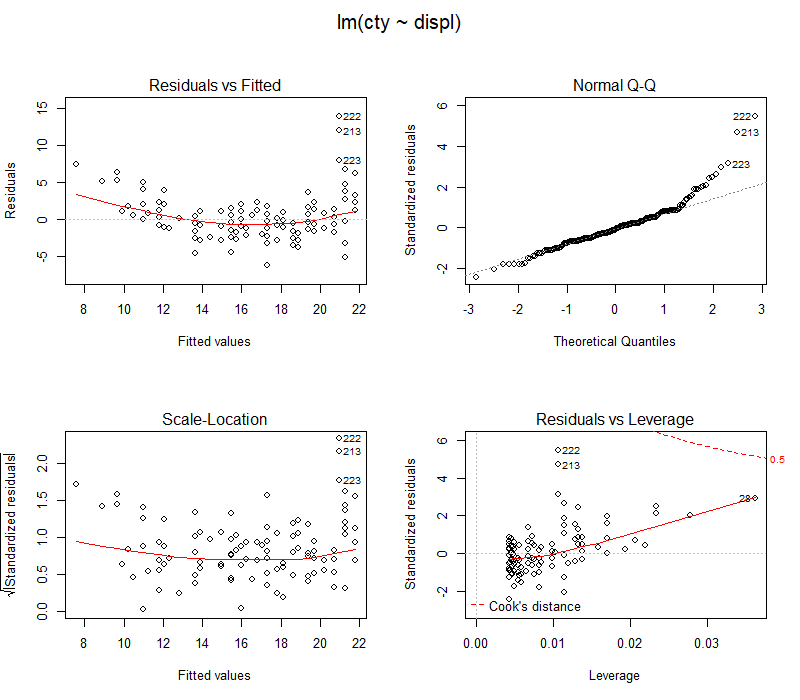
9.3.1 线性模型
# ggplot2目前只有一种适合线性模型的fortify方法
# plot.lm() 这个方法很死板,因为想改动其中任何一个地方,都必须去修改它的源代码。
# 而ggplot2把数据整理和展示完全分离开
# fortify()方法负责数据变形,ggplot2负责画图
# plot.lm plot函数输入的是lm模型
mpgmod <- lm(cty ~ displ, data = mpg)
par(mfrow = c(2, 2), oma = c(0, 0, 2, 0))
plot(mpgmod)
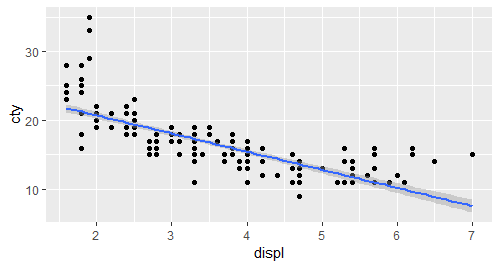
# 简单的使用ggplot模仿第一张图
qplot(displ,cty,data = mpg) + geom_smooth(method = "lm")
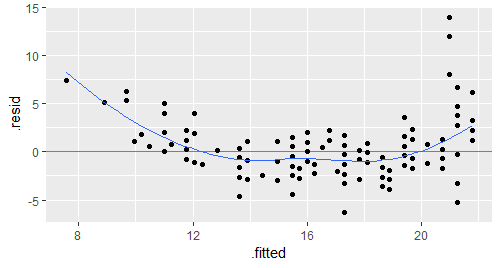
# 下面的例子就演示了如何模仿并扩展plot.lm的第一幅图
# 还可以继续改进,比如用标准化残差替代未标准化残差,或让点的大小代表Cook距离
mpgmod <- lm(cty ~ displ, data = mpg)
basic <- ggplot(mpgmod,aes(.fitted,.resid)) +
geom_hline(yintercept = 0,colour = "grey50",size = 0.5) +
geom_point() + geom_smooth(size = 0.5,se = F)
basic
basic + aes(y = .stdresid)
basic + aes(size = .cooksd) + scale_size_area("Cook`s distance")

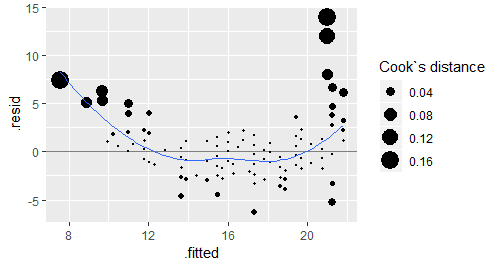
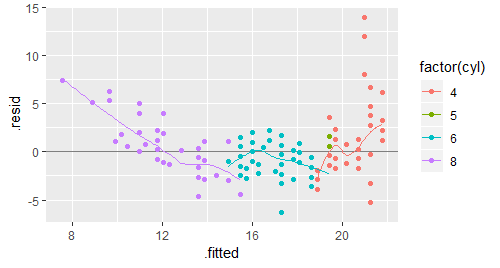
# 继续增补数据集,将不同气缸数的点标上不同的颜色
full <- basic %+% fortify(mpgmod,mpg)
full + aes(colour = factor(cyl))
full + aes(displ,colour = factor(cyl))
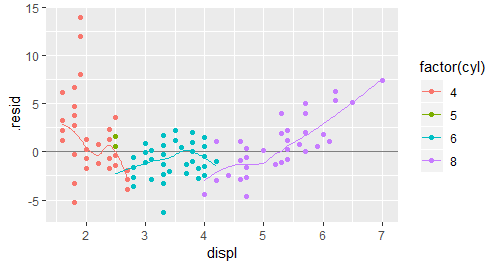
9.3.2 编写自己的方法
# 编写自己的fortify()方法,需要知道哪些变量对模型诊断有用以及如何把他们返回给使用者。
# 编写自己的方法并不简单,请参阅更多R方面的书籍。