最近有点瞎忙活,海贼王电影都没有来得及看。周末单休,累并充实着。还好11月底就考试了,所以也就一个月。还好还好。

说到Text Function,最基础的就是截取了。这个基本上涉及到数据分析,处理都是会用到的。至于截取好之后,你想Text转化成Date,或者想把一个字段里面截取的内容和另一个字段内的内容比较。(此文是同一个行row上的数据比较。想列层次的lookup的话,可以参考之前DAX基础8里面关于LOOKUPVALUE function的分享).
在说这个Text的函数基础之前,先提两点。
要先理清楚逻辑。我要实现什么,逻辑关系是不是清楚。只有想清楚了,才能继续做下去。要做正确的事。
想不出来的时候。就停下来,先不要做了,干点下一个优先级的事情。然后差不多了再回过头来看。这个不是我说的,是SQLBI网站的那两个意大利人说的,我觉得很有道理,也确实这么做的,觉得很有效果。

1. MID函数。
Returns a string of characters from the middle of a text string, given a starting position and length.
MID(<text>, <start_num>, <num_chars>)
MID(要截取的text,从第几位开始,截几位)这里“从第几位开始”,是从1开始数的,”截几位“是正整数。这个函数和数据库的Substring,substr或者Mid是一样。不一样的数据库里面的语法不一样,几种数据库用下来,就这几个关键字。所以如果想在数据库或者ETL工具里面实现你DAX的MID函数,基本上就是以上三个关键字吧。
有时候,我们有一个字段是“2019-09-20”这样的Text,但是要转化成Date来和今天做比较,或者和其他字段的Date做比较,这个时候,我们可以分别截取出来年月日,然后得到一个Date类型的Date。
那如果是“9/9/2019”这样的Text呢,怎么拆分出来年月日呢?嗯,有一个最简单不用DAX也不用M Query的方法。
转到Edit Query这个页面,里面有一个Split Column。你可以从左到右,从右到左,随便怎么拆啊。哈哈哈,这里就用/来拆出三个字段了。
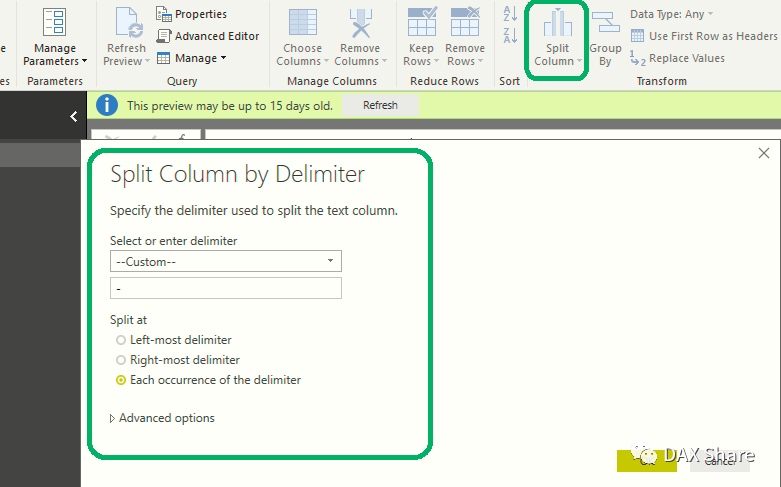
当然,你也可以用DAX来拆。从右边先拆出来4位做年。用RIGHT函数。
RIGHT(要截取的text,从右截几位)。月和日,可以结合下面的FIND函数,LEN函数,还有IF的判断,把下面我举例的代码改改就行。
正常情况下,好像没人会这么折腾DATE。不过,可以拆拆身份证号码,订单内容啥的。反正Text的内容随便拆呗。
2. FIND函数
Returns the starting position of one text string within another text string. FIND is case-sensitive.
FIND(<find_text>, <within_text>[, [<start_num>][, <NotFoundValue>]])
FIND(要找的text,在哪里找,后两个参数是选填的)
3. LEN函数
Returns the number of characters in a text string.
LEN(<text>) 用来判断一个text的长度。这个通常用于处理动态的text长度的时候很好用。
4. SEARCH函数
Returns the number of the character at which a specific character or text string is first found, reading left to right. Search is case-insensitive and accent sensitive.
SEARCH(<find_text>, <within_text>[, [<start_num>][, <NotFoundValue>]])
SEARCH(要找的内容, 在哪里找)
5. EXACT函数
Compares two text strings and returns TRUE if they are exactly the same, FALSE otherwise. EXACT is case-sensitive but ignores formatting differences. You can use EXACT to test text being entered into a document.
EXACT(<text1>,<text2>)
对比两个Text,一样的TRUE,不一样FALSE。
好了,我们现在举个例子来随便用用Text的函数吧。
需求,在一个描述性的Description字段里,内容是系统里,用户对一个订单的Comments。对于特定的2类订单,大家统一会在Comments里面有一个特别的"@D2"这个内容,但是没有确定在哪个位置有这个内容,可能comments的开头,可能中间,还有可能在结尾。有的时候@D2XXX中2XXX如果是这个订单的代号,那即使找到"@D2",也不能算是目标"@D2"。
逻辑还是很清晰的。要找Decription字段里面带"@D2"的,找到了就设置成Y,否则是N,其中如果找到的内容有订单代号,也不是Y。
因为逻辑有点麻烦,我做了两个Calculated Column。
Y_N_contain = IF(ISERROR(SEARCH("@D2",Approval[Note])),0,1)
在Approval[Note]这个Description字段里面去查@D2,我并不关心找到的位置,但是因为有可能找到,有可能找不到,如果找不到,SEARCH这个函数就会ERROR。所以对于只是找,不一定找得到的情况,要结合ISERROR函数一起使用,才有效果。所以,找不到Y_N_contain 就返回0,找到就是1.
Y_N = IF(Approval[Y_N_contain] = 1,
IF(EXACT(Approval[Order Id],(MID(Approval[Note],FIND("@D2",Approval[Note])+1,LEN(Approval[Order Id])))),0,1),0)
这个写的有点复杂。从以下4点来了解这个表达式。
1. 在能找到@D2的前提下,Approval[Y_N_contain] = 1;
2. 找到”@D2“中“@”出现的位置位置FIND("@D2",Approval[Note])
3. 在Approval[Note]中截取从“@D2”中“2“开始FIND("@D2",Approval[Note])+1,到一个Approval[Order Id]订单代号长度的字段
MID(Approval[Note],FIND("@D2",Approval[Note])+1,LEN(Approval[Order Id]))
4. 对比订单代号Approval[Order Id]和截取出来的新字段是不是一样。一般结合IF一起来用。
厉害吧。哈哈~~

这个文章写的有点长了。希望写明白了。
最后贴一个最近写的IF逻辑的DAX,写得有点头晕。
说,如果Business Region是MC,就返回MC这个名称;如果是韩国,客户名称以L开头到Z的是HAAA负责,否则是LBBB;如果不是韩国,先判断Bussiness Area,如果是M,就得到MaDDD,如果不是M,如果是日本这个国家,如果是Business Area 是O,返回OCCC,负责KEEE;如果不是日本,其他的所有国家,客户名称是A到G的LFFF,T到Y的HAAA,S的LBBB,其他的MGGG。有点绕,不过就是想说,只要你逻辑清楚,没有不可实现的。
Collector Name =
IF('AR Balance 201909 Raw Data'[Business Region] = "MC",
"MC",
(IF('AR Balance 201909 Raw Data'[Area other] = "Korea",
(IF(AND(MID('AR Balance 201909 Raw Data'[Customer name],1,1)>="L",MID('AR Balance 201909 Raw Data'[Customer name],1,1)<="Z"), "HAAA","LBBB")),
(IF('AR Balance 201909 Raw Data'[Business Area] = "M",
"MaDDD",
IF('AR Balance 201909 Raw Data'[Area other] = "Japan",
(IF('AR Balance 201909 Raw Data'[Business Area] ="O",
"OCCC",
"KEEE")),
if(AND(MID('AR Balance 201909 Raw Data'[Customer name],1,1)>="A",MID('AR Balance 201909 Raw Data'[Customer name],1,1)<="G"),
"LFFF",
if(AND(MID('AR Balance 201909 Raw Data'[Customer name],1,1)>="T",MID('AR Balance 201909 Raw Data'[Customer name],1,1)<="Y"),
"HAAA",
if(MID('AR Balance 201909 Raw Data'[Customer name],1,1)="S",
"LBBB","MGGG"
)))))))))

谢谢您的关注。

