聚类分析是一种比较常见算法,实际应用也很多,比如大家经常听到的RMF模型、分客群精准营销等都是聚类分析的应用。
我们可以用“物以类聚、人以群分”来简单理解,它是一种无监督的分类算法。但是这种“简单”的算法,在运用到实际工作中会遇到很多问题,比如:
①极端值的影响造成个别几个样本被聚为了一类,剩余绝大部分样本被聚为了一类,相当于没有聚类。
②指标太多,不知道选哪些指标,量纲该如何处理?
③聚出来的客群大的大小的小,无法营销。
④不知道聚类效果如何,是否使用了最好的聚类算法,得到了最佳的N个客群。
聚类算法是基于距离计算的,所以我们选择的指标一定是数值型变量,大部分情况下都需要消除量纲的影响。
聚类算法按照方式不同,可以分为凝聚式和分裂式两种。
凝聚式 Agglometative:顾名思义就是开始时将所有的样本(n个)都视为一类(n类),然后一步步的把距离近的聚为一类,最终所有样本聚为一类的方法。
分裂式 Divisive:开始时将所有样本视为一类,最终拆分到每个样本都是一类。
我们来看一下Python中聚类算法的实现。
1. 常见的聚类算法
skleaarn中展示了不同的聚类算法适用的数据分布及运行时间。链接
可以看到不同的算法适合不同的数据分布,也有不同的时耗,具体使用哪种算法,需要根据数据情况来选择,甚至迭代不同算法不同参数来择优。
%pylab inline
from IPython.display import Image
Image('cluster methods.png')
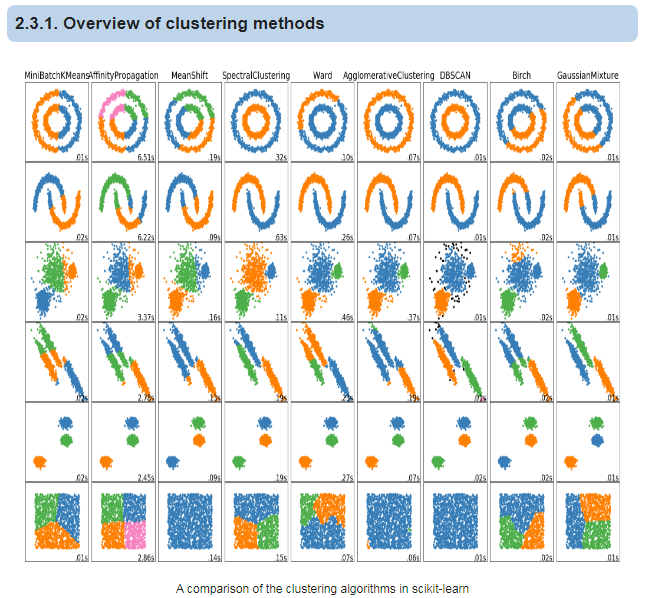
2. 聚类算法示例
我们使用内置的鸢尾花数据集来进行聚类。鸢尾花数据集:共150条记录,有花萼长度、花萼宽度、花瓣长度、花瓣宽度、品种5个变量,其中每个品种50条记录。
2.1 使用scipy进行层次聚类
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=[15,5])
dendrogram = sch.dendrogram(sch.linkage(iris.data, method='ward')) #ward最小方差法(使用的是欧氏距离)
plt.title('鸢尾花聚类树状图')
plt.xlabel('鸢尾花数据')
plt.ylabel('欧式距离')
plt.show()
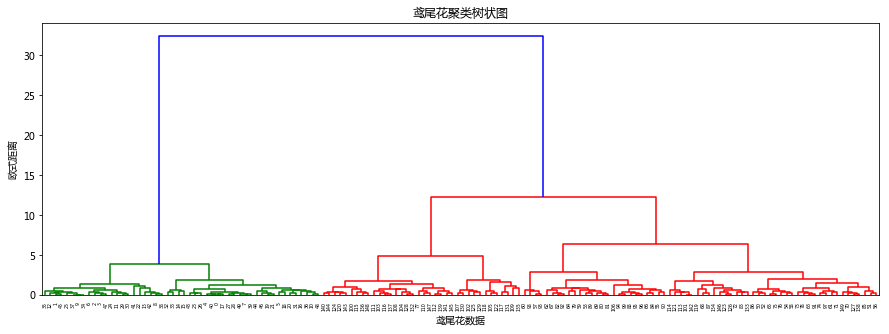
根据树状图我们可以确定聚为几类及样本分类,这种方法非常直观,但是不适用于大样本。
2.2 凝聚聚类
from sklearn.cluster import AgglomerativeClustering
ac = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='ward')
y_ac = ac.fit_predict(iris.data)
# 查看聚类结果
# 我们使用鸢尾花的花瓣长度和花瓣宽度做散点图,用散点颜色来区分鸢尾花的品种
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(12, 12))
plt.subplot(221)
color = {0:'r',1:'y',2:'b'}
plt.scatter(iris.data[:,2], iris.data[:,3], c=[color[_] for _ in y_ac])
plt.title('Cluster data')
color = {0:'y',1:'b',2:'r'}
plt.subplot(222)
plt.scatter(iris.data[:,2], iris.data[:,3], c=[color[_] for _ in iris.target])
plt.title('Original data')
plt.show()
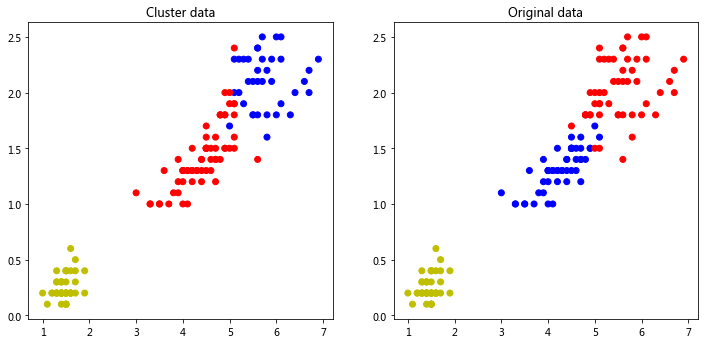
2.3 KMeans聚类
from sklearn.cluster import KMeans
model_kmeans = KMeans(n_clusters=3, init='k-means++', random_state=123)
y_pred = model_kmeans.fit_predict(iris.data)
model_kmeans.cluster_centers_ # 类中心
# 聚类效果可视化
colors = ['red', 'blue', 'green']
for i in range(3):
plt.scatter(iris.data[y_pred == i, 2], iris.data[y_pred == i, 3], s = 100, c = colors[i], label = 'Cluster '+str(i+1))
plt.scatter(model_kmeans.cluster_centers_[:,2], model_kmeans.cluster_centers_[:,3], s = 200, c = 'yellow', label = 'Center')
plt.title('Clusters of Iris')
plt.xlabel('Petal.Length')
plt.ylabel('Petal.Width')
plt.legend()
plt.show()
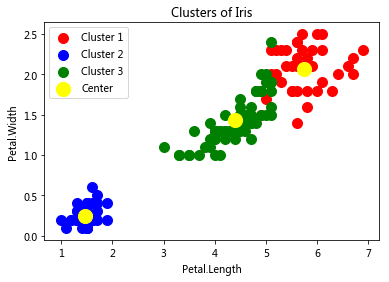
3. 聚类算法调优
3.1 极端值处理
从散点图来看:鸢尾花数据集中是没有特别极端的值的,但是实际数据中很可能存在离群点或极端值(如某个大客户的交易额),这些样本点会增加极差,聚类效果不佳(绝大部分聚为一类,个别样本聚为一类),但换个角度想,这些恰恰是我们的异常数据,可以做异常检查,比如说刷单客户识别,这样的场景下我们不要对数据分布进行处理。
3.2 聚类个数的确定
我们知道鸢尾花数据集中有setosa、versicolor、virginica三个品种,但实际上聚类算法是无监督学习算法,我们并不知道结果,那么如何确定聚类个数呢? 按照聚类算法“物以类聚,人以群分”的思想,自然是簇内距离最小,簇间距离最大为最好的分群标准。
# 使用inertia或silhouette_score来确定
from sklearn import metrics
plt.figure(figsize=[8, 2])
rng1 = range(1, 11)
rng2 = range(2, 11)
inertia = []
silhs = []
for k in rng1:
model = KMeans(n_clusters=k)
model.fit(iris.data)
inertia.append(model.inertia_)
for k in rng2:
model = KMeans(n_clusters=k)
model.fit(iris.data)
silhs.append(metrics.silhouette_score(iris.data, model.predict(iris.data)))
plt.subplot(121)
plt.title('inertia')
plt.plot(rng1, inertia)
plt.subplot(122)
plt.title('silhouette_score')
plt.plot(rng2, silhs)
plt.show()
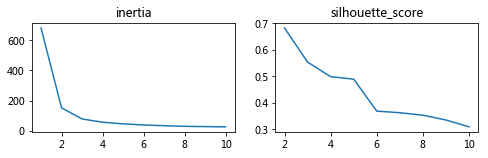
从上图可以看出:inertia在K=2时出现拐点,silhouette_score在K=2时最大,说明聚为2类比较合适。从鸢尾花花瓣的散点图来看,散点确实分布在两个区域。 这里只做算法演示,实际运用中还是要根据客观情况决定。比如本例中我们已知是三个品种的鸢尾花数据,那么肯定是要聚为三类的。
# 看一下聚为两类时各客群的样本量
import pandas as pd
model_kmeans = KMeans(n_clusters=2, init='k-means++', random_state=123)
y_pred = model_kmeans.fit_predict(iris.data)
df_y_pred = pd.DataFrame(y_pred, columns=['cluseter'])
df_y_pred['cluseter'].value_counts()

可以看到聚为两类时一个客群97个样本,一个客群53个样本。
3.3 变量的选择
我们在对样本进行聚类时,通常有许多指标可供选择,但是选择哪些指标呢?我们可以从两个方面来选择:一是看数据分布,只选择我们看中的且特征明显的指标;二是对我们认为应该选中的指标进行降维,例如主成分分析(PCA)。
3.3.1 主观选择变量
# 看一下鸢尾花的四个指标的散点图分布
import seaborn as sns
df_iris = pd.concat([pd.DataFrame(iris.data, columns=iris.feature_names), pd.DataFrame(iris.target, columns=['species'])], axis=1)
sns.pairplot(df_iris,
hue='species', kind='reg', diag_kind='kde', size=1.5)
plt.show()
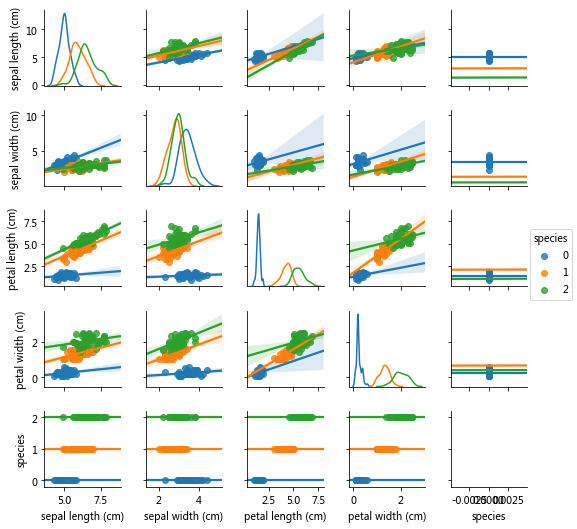
可以看到三个品种的花萼长度和花萼宽度散点图区别不大,而花瓣长度和花瓣宽度散点图区别较大,我们只选用花瓣数据进行聚类。
由于我们已知三个鸢尾花,我们使用模型的调整兰德指数来作为聚类效果的评判标准。(注:实际中并不知道分类结果,我们这里只做算法比较用)。 调整兰德指数 adjusted_rand_s:值介于0到1之间,值越大,聚类效果越好。
# 先来看一下使用四个变量聚为三类的模型得分
model_a = KMeans(n_clusters=3, init='k-means++', random_state=123)
y_pred_a = model_a.fit_predict(iris.data)
ARI_a = metrics.adjusted_rand_score(y_pred_a, iris.target)
ARI_a
得到:ARI_a=0.73
# 仅使用花瓣的两个变量聚为三类的模型得分
model_b = KMeans(n_clusters=3, init='k-means++', random_state=123)
y_pred_b = model_a.fit_predict(iris.data[:,2:4])
ARI_b = metrics.adjusted_rand_score(y_pred_b, iris.target)
ARI_b
得到:ARI_b=0.89
3.3.2 对多变量降维
from sklearn.decomposition import PCA
pca = PCA(n_components=4)
pca.fit(iris.data)
pca.explained_variance_ratio_
得到主成分的方差解释比例:array([0.92461621, 0.05301557, 0.01718514, 0.00518309]),可以看到第一个主成分就能解释92%的方差(一般前n个主成分累计超过80%即可),所以我们可以选择一个主成分,但是为了数据展示需要,这里我们选择两个主成分。
pca = PCA(n_components=2)
pca.fit(iris.data)
iris_data_pca = pca.transform(iris.data)
# 先看一下得到的降维数据三种鸢尾花散点图
plt.scatter(iris_data_pca[:, 0], iris_data_pca[:, 1],c=iris.target)
plt.title('pca iris data')
plt.show()
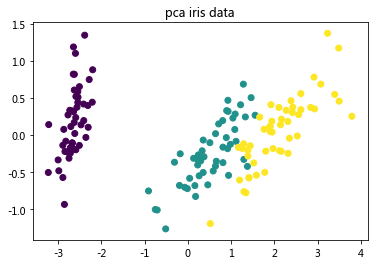
# 使用降维后的数据进行聚类
model_c = KMeans(n_clusters=3, init='k-means++', random_state=123)
y_pred_c = model_c.fit_predict(iris_data_pca)
ARI_c = metrics.adjusted_rand_score(y_pred_c, iris.target)
ARI_c
得到:ARI_c=0.72,略低于ARI_a的0.73。本例中聚类效果没有提升,但使用PCA可以解决高维变量的聚类问题。
3.4 变量分布处理
当我们需要将全部样本数据较均匀的拆分为N个客群时,样本数据的分布会造成较大的影响,为此我们可以改变样本数据的分布形态,来达到均衡客群量的问题。
# 先正态化后再聚类
from sklearn.preprocessing import StandardScaler, Normalizer
iris_norm = Normalizer().fit_transform(iris.data)
model_d = KMeans(n_clusters=3)
y_pred_d = model_d.fit_predict(iris_norm)
ARI_d = metrics.adjusted_rand_score(y_pred_d, iris.target)
ARI_d
ARI_d提升到了0.90!
# 正态+降维后再聚类
iris_norm_pca = PCA(n_components=2).fit_transform(iris_norm)
model_e = KMeans(n_clusters=3).fit(iris_norm_pca)
y_pred_e = model_e.fit_predict(iris_norm)
ARI_e = metrics.adjusted_rand_score(y_pred_e, iris.target)
ARI_e
本例中ARI_e并没有提升。
4. 总结
综上,我们总结一下开篇提到的四个问题:
①极端值问题:若是识别异常客户,极端值是不需要处理的;若是分群,可以对数据进行标准化、正态化处理。
②指标太多、量纲处理:首先可以主观判断,其次可以使用主成分分析。比如使用销售额、利润额和毛利率三个指标直接聚类显然是不合适的。
③客群大小:可以正态化处理让客群大小更加均衡,有时可以调整客群数来满足客群量的问题。
④聚为几类:如果是明确的,就直接聚为几类;也可以通过树状图、inertia、silhouette来确定。
以上,如有不妥之处还请多多指正。
